当前位置:网站首页>Next generation visual transformer: Unlocking the correct combination of CNN and transformer
Next generation visual transformer: Unlocking the correct combination of CNN and transformer
2022-07-26 14:52:00 【PaperWeekly】

author | Machine center editorial department
source | Almost Human
Due to the complex attention mechanism and model design , Most existing visual Transformer(ViT) In real industrial deployment scenarios, it cannot be like Convolutional Neural Networks (CNN) So efficient . This brings up a problem : Can visual neural network be like CNN Infer as quickly as and like ViT As strong as ?
Some recent work has attempted to design CNN-Transformer Hybrid architecture to solve this problem , But the overall performance of these works is far from satisfactory . Based on this , Researchers from ByteDance have proposed a next-generation vision that can be effectively deployed in real industrial scenes Transformer——Next-ViT. From delay / From the perspective of accuracy balance ,Next-ViT Its performance is comparable to that of excellent CNN and ViT.

Paper title :
Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios
Thesis link :
https://arxiv.org/pdf/2207.05501.pdf
Next-ViT By developing new convolution blocks (NCB) and Transformer block (NTB), Deploy friendly mechanisms to capture local and global information . then , This study proposes a new hybrid strategy NHS, Designed to stack in an efficient hybrid paradigm NCB and NTB, So as to improve the performance of various downstream tasks .
A lot of experiments show that ,Next-ViT Delays in various visual tasks / The accuracy trade-off is significantly better than the existing CNN、ViT and CNN-Transformer Hybrid architecture . stay TensorRT On ,Next-ViT And ResNet comparison , stay COCO The detection task is higher than 5.4 mAP(40.4 VS 45.8), stay ADE20K Split up 8.2% mIoU(38.8% VS 47.0%). meanwhile ,Next-ViT Achieved and CSWin Quite good performance , And the reasoning speed is improved 3.6 times . stay CoreML On ,Next-ViT stay COCO The detection task is better than EfficientFormer Higher than 4.6 mAP(42.6 VS 47.2), stay ADE20K Split up 3.5% mIoU( from 45.2% To 48.7%).

Method
Next-ViT The overall structure is as follows 2 Shown .Next-ViT Follow the hierarchical pyramid architecture , One at each stage patch Embedding layer and a series of convolutions or Transformer block . The spatial resolution will be gradually reduced to the original 1/32, The channel dimension will be expanded by stages .

Researchers first designed the core module of information interaction , And develop powerful NCB and NTB To simulate short-term and long-term dependencies in visual data .NTB It also integrates local and global information , Further improve the modeling ability . Last , In order to overcome the inherent defects of the existing methods , This study systematically studies convolution and Transformer Block integration , Put forward NHS Strategy , To stack NCB and NTB Build a new CNN-Transformer Hybrid architecture .
1.1 NCB
Researchers analyzed several classic structural designs , Here's the picture 3 Shown .ResNet [9] Proposed BottleNeck Due to its inherent inductive bias and easy deployment on most hardware platforms , It has been playing a leading role in visual neural networks for a long time . Unfortunately , And Transformer Block comparison ,BottleNeck The effectiveness of the block is not good .ConvNeXt block [20] By imitation Transformer Block design , Yes BottleNeck The block has been modernized . although ConvNeXt Block improves network performance , But it's in TensorRT/CoreML The reasoning speed on is severely limited by inefficient components .Transformer Block has achieved excellent results in various visual tasks , However Transformer The reasoning speed of blocks is faster than TensorRT and CoreML Upper BottleNeck Block is much slower , Because its attention mechanism is more complex , This is unbearable in most real industrial scenes .

In order to overcome the problems of the above blocks , This study proposes Next Convolution Block (NCB), It's keeping BottleNeck The deployment advantages of the block are achieved at the same time Transformer Outstanding performance of blocks . Pictured 3(f) Shown ,NCB follow MetaFormer ( It has been proved right Transformer Blocks are crucial ) The general architecture of .
Besides , An efficient attention based token Mixers are also important . This research designs a multi head convolution attention (MHCA) As an efficient way to deploy convolution operations token Mixer , And in MetaFormer [40] In the paradigm of MHCA and MLP Layer building NCB.
1.2 NTB
NCB Local representations have been learned effectively , The next step is to capture global information .Transformer The architecture has a strong ability to capture low-frequency signals , These signals can provide global information ( Such as global shape and structure ).
However , Relevant research has found ,Transformer Blocks may deteriorate high-frequency information to some extent , For example, local texture information . Signals of different frequency bands are essential in human visual system , They fuse in a particular way , To extract more essential and unique features .
Affected by these known results , It's time to develop Next Transformer Block (NTB), To capture multifrequency signals in a lightweight mechanism . Besides ,NTB It can be used as an effective multi frequency signal mixer , Further enhance the overall modeling ability .
1.3 NHS
Some recent efforts will CNN and Transformer Combine to deploy efficiently . Here's the picture 4(b)(c) Shown , Almost all of them use convolution blocks in the shallow stage , Only stack in the last oneortwo stages Transformer block , This combination is effective in classification tasks . But the study found that these hybrid strategies are easy to work downstream ( For example, segmentation and detection ) Up to performance saturation . as a result of , The classification task uses only the output of the final stage for prediction , And downstream tasks ( For example, segmentation and detection ) Usually rely on the characteristics of each stage to get better results . This is because the traditional hybrid strategy is only stacked in the last few stages Transformer block , Shallow layer cannot capture global information .

This study proposes a new hybrid strategy (NHS), Creatively combine convolution blocks (NCB) and Transformer block (NTB) And (N + 1) * L Mixed paradigms are combined .NHS Under control Transformer In the case of block proportions , Significantly improve the performance of the model on downstream tasks , And achieve efficient deployment .
First , In order to give the shallow layer the ability to capture global information , The study proposes a kind of (NCB×N+NTB×1) Mode blending strategy , Stack in turn at each stage N individual NCB And a NTB, Pictured 4(d) Shown . say concretely ,Transformer block (NTB) Place at the end of each stage , It enables the model to learn the global representation in the shallow layer . This study conducted a series of experiments to verify the superiority of the proposed hybrid strategy , The performance of different hybrid strategies is shown in the following table 1 Shown .

Besides , The following table 2 Shown , The performance of the large model will gradually reach saturation . This phenomenon shows that , By expanding (NCB × N + NTB × 1) Mode N To enlarge the size of the model , That is, simply adding more convolution blocks is not the best choice ,(NCB × N + NTB × 1) In the pattern N Values can seriously affect model performance .

therefore , Researchers began to explore through extensive experiments N The effect of the value of on the performance of the model . As shown in the table 2( in ) Shown , In the third stage of the study, different N Value model . In order to build a model with similar delay for fair comparison , The study was conducted in N Stack when the value is small L Group (NCB × N + NTB × 1) Pattern .
As shown in the table 2 Shown , The third stage N = 4 Our model achieves the best tradeoff between performance and latency . The study was expanded in the third stage (NCB × 4 + NTB × 1) × L Mode L To further build a larger model . As shown in the table 2( Next ) Shown ,Base(L = 4) and Large(L = 6) The performance of the model is significantly improved compared with the small model , The proposed (NCB × N + NTB × 1)× L General validity of the pattern .
Last , In order to provide with existing SOTA Fair comparison of Networks , Researchers have proposed three typical variants , namely Next-ViTS/B/L.


experimental result
2.1 ImageNet-1K Classification task on
With the latest SOTA Method ( for example CNN、ViT And hybrid networks ) comparison ,Next-ViT Achieve the best trade-off between accuracy and latency , The results are as follows 4 Shown .

2.2 ADE20K Semantic segmentation task on
The study will Next-ViT And CNN、ViT Compared with some recent hybrid architectures for semantic segmentation tasks . The following table 5 Shown , A lot of experiments show that ,Next-ViT Excellent potential in segmentation tasks .

2.3 Object detection and instance segmentation
In the task of target detection and instance segmentation , The study will Next-ViT And SOTA The models are compared , The results are as follows 6 Shown .

2.4 Ablation experiments and visualization
Just to understand Next-ViT, The researchers evaluated their performance in ImageNet-1K Classification and performance on downstream tasks to analyze the role of each key design , The Fourier spectrum and heat map of the output features are visualized , To display Next-ViT The inherent advantages of .
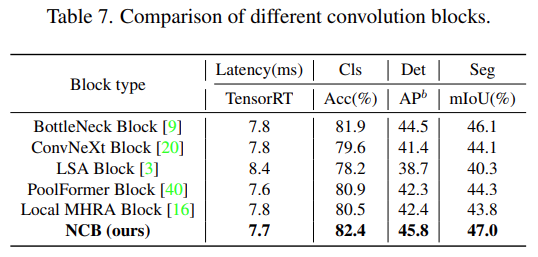
The following table 7 Shown ,NCB The best delay is achieved on all three tasks / Accuracy tradeoffs .
about NTB block , The study explored NTB Shrinkage of r Yes Next-ViT The impact of overall performance , The results are as follows 8 Shown , Reduce shrinkage r Will reduce model latency .

Besides ,r = 0.75 and r = 0.5 Our model is better than pure Transformer (r = 1) The model has better performance . This shows that fusing multifrequency signals in an appropriate way will enhance the representational learning ability of the model . especially ,r = 0.75 Our model achieves the best delay / Accuracy tradeoffs . These results illustrate NTB Block validity .
The study further analyzed Next-ViT Influence of different normalization layers and activation functions in . The following table 9 Shown ,LN and GELU Although it brings some performance improvements , But in TensorRT The reasoning delay on is significantly higher . On the other hand ,BN and ReLU The best delay is achieved in the overall task / Accuracy tradeoffs . therefore ,Next-ViT Unified use BN and ReLU, For efficient deployment in real industrial scenarios .

Last , The study visualized ResNet、Swin Transformer and Next-ViT The output characteristics of Fourier spectrum and heat map , Here's the picture 5(a) Shown .ResNet The spectrum distribution shows that convolution blocks tend to capture high-frequency signals 、 It is difficult to pay attention to low-frequency signals ;ViT Good at capturing low-frequency signals and ignoring high-frequency signals ; and Next-ViT It can capture high-quality multi frequency signals at the same time , This shows NTB The effectiveness of the .

Besides , Pictured 5(b) Shown ,Next-ViT Energy ratio ResNet and Swin Capture richer texture information and more accurate global information , This explanation Next-ViT Better modeling ability .
Read more




# cast draft through Avenue #
Let your words be seen by more people
How to make more high-quality content reach the reader group in a shorter path , How about reducing the cost of finding quality content for readers ? The answer is : People you don't know .
There are always people you don't know , Know what you want to know .PaperWeekly Maybe it could be a bridge , Push different backgrounds 、 Scholars and academic inspiration in different directions collide with each other , There are more possibilities .
PaperWeekly Encourage university laboratories or individuals to , Share all kinds of quality content on our platform , It can be Interpretation of the latest paper , It can also be Analysis of academic hot spots 、 Scientific research experience or Competition experience explanation etc. . We have only one purpose , Let knowledge really flow .
The basic requirements of the manuscript :
• The article is really personal Original works , Not published in public channels , For example, articles published or to be published on other platforms , Please clearly mark
• It is suggested that markdown Format writing , The pictures are sent as attachments , The picture should be clear , No copyright issues
• PaperWeekly Respect the right of authorship , And will be adopted for each original first manuscript , Provide Competitive remuneration in the industry , Specifically, according to the amount of reading and the quality of the article, the ladder system is used for settlement
Contribution channel :
• Send email :[email protected]
• Please note your immediate contact information ( WeChat ), So that we can contact the author as soon as we choose the manuscript
• You can also directly add Xiaobian wechat (pwbot02) Quick contribution , remarks : full name - contribute

△ Long press add PaperWeekly Small make up
Now? , stay 「 You know 」 We can also be found
Go to Zhihu home page and search 「PaperWeekly」
Click on 「 Focus on 」 Subscribe to our column
·
·

边栏推荐
- JS wave animation effect menu style
- Brief description of llcc68 broadcast wake-up
- 《MySQL高级篇》五、InnoDB数据存储结构
- Create Yum warehouse inside the enterprise
- Whaledi message queue stability improvement practice
- Flask send_ Absolute path traversal caused by file function
- C nanui related function integration
- Parsing XML files using Dom4j
- [ostep] 04 virtualized CPU - process scheduling strategy
- leetcode汇总
猜你喜欢
Figure introduction to neural network core dataset

基于CAS的SSO单点服务端配置

Keyboard shortcut to operate the computer (I won't encounter it myself)

PyTorch中 torch.nn与torch.nn.functional的区别

Parsing XML files using Dom4j

Summary and analysis of image level weakly supervised image semantic segmentation
PyTorch中 nn.Conv2d与nn.ConvTranspose2d函数的用法
Create root permission virtual environment

BSN IPFS(星际文件系统)专网简介、功能、架构及特性、接入说明
![Matlab solution of [analysis of variance]](/img/30/638c4671c3e37b7ce999c6c98e3700.png)
Matlab solution of [analysis of variance]
随机推荐
堆叠降噪自动编码器 Stacked Denoising Auto Encoder(SDAE)
Usage of nn.conv2d and nn.convtranspose2d functions in pytorch
[nuxt 3] (XII) project directory structure 1
C winfrom common function integration
Classic line style login interface
[ostep] 04 virtualized CPU - process scheduling strategy
Canvas laser JS special effect code
4 kinds of round head arrangement styles overlay styles
Advanced MySQL v. InnoDB data storage structure
【常微分方程求解及绘图之求解小船行走轨迹】
[untitled]
Unity学习笔记–无限地图
Winscp transfer file and VNC connection problem
go开发调试之Delve的使用
SA-Siam:用于实时目标跟踪的孪生网络
Kubernetes ---- pod configuration resource quota
Create root permission virtual environment
Error reported by Nacos enabled client
Summary and analysis of image level weakly supervised image semantic segmentation
C nanui related function integration