当前位置:网站首页>Process the dataset and use labelencoder to convert all IDs to start from 0
Process the dataset and use labelencoder to convert all IDs to start from 0
2022-07-03 02:43:00 【strawberry47】
Data sets in the field of recommended algorithms always start from 1 Start , Or a string of numbers , Every time you deal with it, you need one more user2id The operation of , It's a real hassle
Simply handle it before using the dataset , And save it user2id Dictionaries , Convenient for follow-up query
Pay attention to the :
- sep To change to the separator of the current dataset (’ ‘,’\t’)
- names Change to the column name of the current dataset
The code is as follows :
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
def load_mat():
data_path = '../dataset/ml-100k/u.data'
df_data = pd.read_csv(data_path, header = None, sep='\t', names =['user_id', 'item_id', 'rating','time'])
lbe_user = LabelEncoder()
lbe_user.fit(df_data['user_id'].unique())
converted_user = lbe_user.transform(df_data['user_id'])
lbe_item = LabelEncoder() # Make it discrete
lbe_item.fit(df_data['item_id'].unique())
converted_item = lbe_item.transform(df_data['item_id'])
converted_data = pd.DataFrame()
converted_data['user_id'] = converted_user
converted_data['item_id'] = converted_item
converted_data['rating'] = df_data['rating']
# Corresponding relation
user2id = {
}
for user in lbe_user.classes_:
user2id.update({
user: lbe_user.transform([user])[0]})
item2id = {
}
for item in lbe_item.classes_:
item2id.update({
item: lbe_item.transform([item])[0]})
return converted_data,user2id,item2id
def save(converted_data,user2id,item2id):
sort = converted_data.sort_values(by=['user_id'])
sort.to_csv('../dataset/ml-100k/data_converted', header=None, index=False)
np.save('../dataset/ml-100k/user2id.npy', user2id)
np.save('../dataset/ml-100k/item2id.npy', item2id)
print('successfully saved')
if __name__ == '__main__':
converted_data,user2id,item2id = load_mat()
save(converted_data,user2id,item2id)
边栏推荐
- GBase 8c触发器(二)
- Restcloud ETL cross database data aggregation operation
- [translation] modern application load balancing with centralized control plane
- Deep Reinforcement Learning for Intelligent Transportation Systems: A Survey 论文阅读笔记
- C语言中左值和右值的区别
- Gbase 8C system table PG_ authid
- 4. Classes and objects
- 基于can总线的A2L文件解析(2)
- [fluent] future asynchronous programming (introduction | then method | exception capture | async, await keywords | whencomplete method | timeout method)
- JMeter performance test JDBC request (query database to obtain database data) use "suggestions collection"
猜你喜欢

Check log4j problems using stain analysis
Didi programmers are despised by relatives: an annual salary of 800000 is not as good as two teachers

How to change the panet layer in yolov5 to bifpn
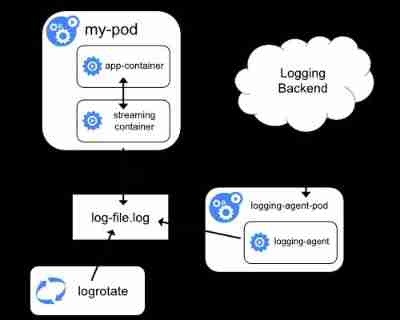
Kubernetes cluster log and efk architecture log scheme
![[fluent] listview list (map method description of list set | vertical list | horizontal list | code example)](/img/e5/c01f760b07b495f5b048ea367e0c21.gif)
[fluent] listview list (map method description of list set | vertical list | horizontal list | code example)

easyPOI
Create + register sub apps_ Define routes, global routes and sub routes

Your family must be very poor if you fight like this!

Principle and application of database

HW-初始准备
随机推荐
[advanced ROS] Lesson 6 recording and playback in ROS (rosbag)
Deep learning: multi-layer perceptron and XOR problem (pytoch Implementation)
The Linux server needs to install the agent software EPS (agent) database
[principles of multithreading and high concurrency: 1_cpu multi-level cache model]
Word word word
Random Shuffle attention
GBase 8c系统表-pg_class
超好用的日志库 logzero
Gbase 8C system table PG_ cast
Source code analysis | layout file loading process
Cvpr2022 remove rain and fog
Gbase 8C function / stored procedure definition
Interview stereotyped version
GBase 8c系统表pg_database
Gbase 8C system table PG_ am
[flutter] example of asynchronous programming code between future and futurebuilder (futurebuilder constructor setting | handling flutter Chinese garbled | complete code example)
Gbase 8C trigger (I)
GBase 8c 创建用户/角色 示例二
怎么将yolov5中的PANet层改为BiFPN
GBase 8c系统表pg_cast