当前位置:网站首页>Selenium基础知识 分页处理
Selenium基础知识 分页处理
2022-07-22 18:09:00 【everyone_yi】
有时需要对列表进行翻页操作,Selenium同样提供了相应API。
分页处理逻辑大致可分为以下三个步骤:
(1)获取总页数。
(2)获取所有分页并循环翻页。
(3)针对每一次分页进行后续逻辑处理。
以百度贴吧Python为例:
1.先定位到分页div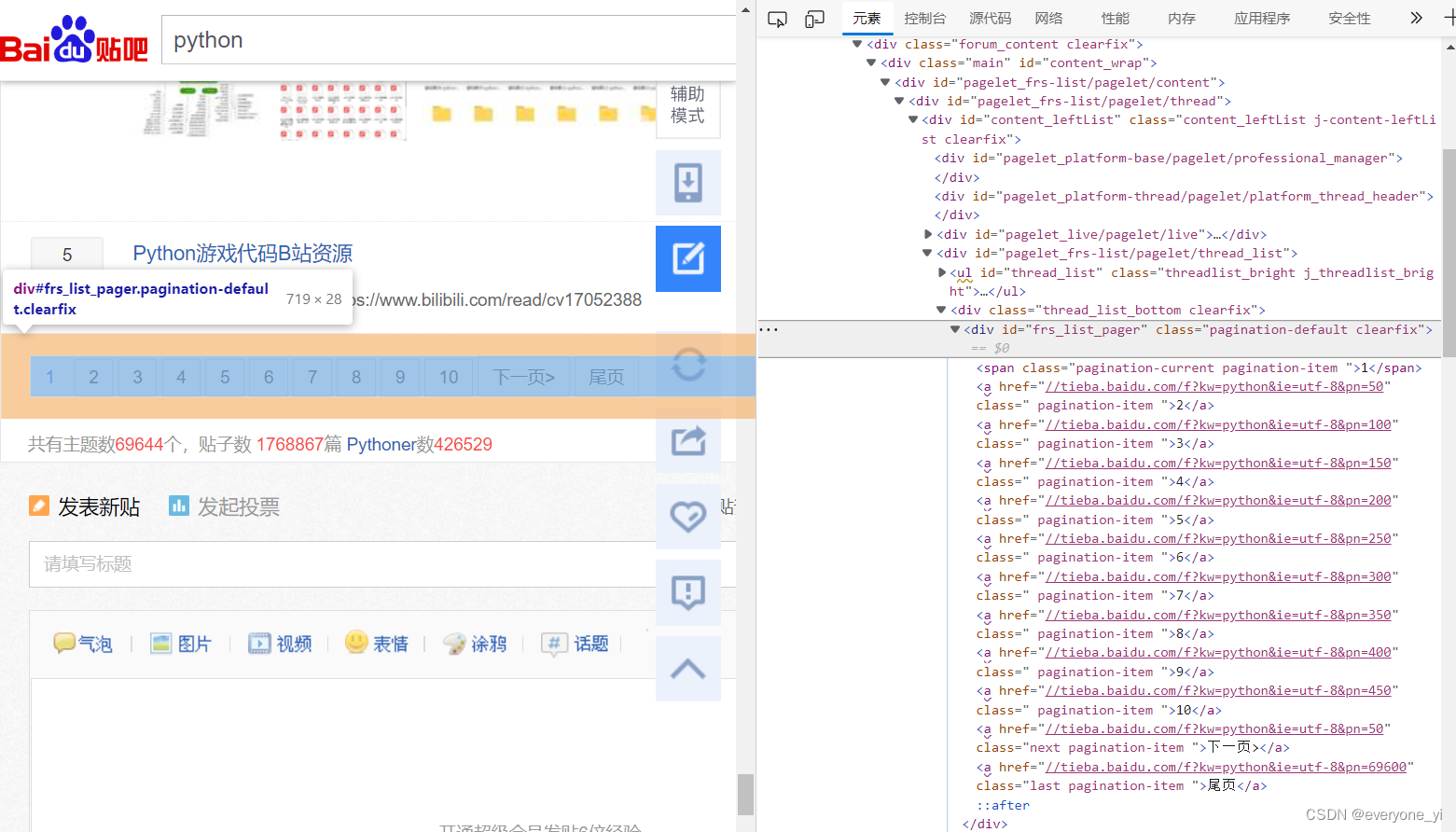
2.定位到尾页按钮
# -*- coding: utf-8 -*-
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
driver = webdriver.Edge()
data = {
'index_url':'http://tieba.baidu.com/f?ie=utf-8&kw=python',
'pagination_id':'frs_list_pager',
'':''
}
# 访问Python吧首页
# frs_list_pager
driver.get(data['index_url'])
# 定位等到分页div
pagination_div = driver.find_element(by=By.ID,value=data['pagination_id'])
print(pagination_div)
# 计算最后一页的页码
# 先点击尾页按钮
driver.find_element(by=By.CSS_SELECTOR,value='#frs_list_pager > a.last.pagination-item').click()
time.sleep(3)
# 获取尾页的页码数
last_page_no = driver.find_element(by=By.CSS_SELECTOR,value='#frs_list_pager > span').text
time.sleep(2)
print(last_page_no)
# 跳回首页
driver.get(data['index_url'])
# 循环last_page_no次获取每一页的数据
for index in last_page_no:
# 一些收集数据的代码,省略
time.sleep(2)
driver.find_element(by=By.CSS_SELECTOR,value='#frs_list_pager > a.next.pagination-item').click()
# driver.quit()
试运行了几次发现每次一到第五页就停止 然后在循环里加了个输出语句 发现每次的index 分别是 1 3 9 3
发现刚好和总页数一样 就又加了个type语句输出last_page_no变量 发现是string类型 所以只有四次循环 print(type(last_page_no))
最终代码
# -*- coding: utf-8 -*-
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
driver = webdriver.Edge()
data = {
'index_url':'http://tieba.baidu.com/f?ie=utf-8&kw=python',
'pagination_id':'frs_list_pager'
}
# 访问Python吧首页
# frs_list_pager
driver.get(data['index_url'])
# 定位等到分页div
pagination_div = driver.find_element(by=By.ID,value=data['pagination_id'])
print(pagination_div)
# 计算最后一页的页码
# 先点击尾页按钮
driver.find_element(by=By.CSS_SELECTOR,value='#frs_list_pager > a.last.pagination-item').click()
time.sleep(2)
# 获取尾页的页码数
last_page_no = driver.find_element(by=By.CSS_SELECTOR,value='#frs_list_pager > span').text
# 现在得到的last_page_no是string类型 需要转换 否则只会有四次循环 1 3 9 3 因为lastpageno是字符串‘1393’
time.sleep(2)
print(type(last_page_no))
last_page_no = int(last_page_no)
print(type(last_page_no))
print(last_page_no)
# 跳回首页
driver.get(data['index_url'])
# 循环last_page_no次获取每一页的数据
for index in range(last_page_no):
# 一些收集数据的代码,省略
print(index)
time.sleep(2)
driver.find_element(by=By.CSS_SELECTOR,value='#frs_list_pager > a.next.pagination-item').click()
# driver.quit()
像这样就可以啦!
边栏推荐
- 软件测试基础
- Test preface 2
- day04---禅道的使用
- Dynamic planning A-1
- Divided by whether to run source code: static test and dynamic test
- 按照是否查看原代码划分: 白盒测试和黑盒测试
- 使用清华镜像安装librosa
- [原创]软件测试实例指导
- Icm20948 conversion relationship between angular velocity reading of nine axis sensor and actual unit conversion
- [original] software test example guidance
猜你喜欢

测试用例:注册邮箱

2021-06-03pip报错 ValueError: Unable to find resource t64.exe in package pip._vendor.distlib

Software life cycle model ----- V model

Day03 --- flow chart operation -- scenario method

After class exercise 01 --- QQ login
第二天总结及测试用例作业

The new business form of smart civil aviation has emerged, and Tupo digital twin has entered the civil aviation flight network of the Bureau

Espressif plays PWM

接口文档案例

Day02 test case
随机推荐
有关排序题目合集
Digital twin demonstration project -- from the simple pendulum (1)
关于自动化适配的落地方案
Summary of UVM knowledge points
Software testing ~ learning / advanced route
App性能测试Case
Advantages and disadvantages of pyramid automation
How does app automated testing achieve H5 testing
Compile and install redis-6.2.5 under Windows
一个简易的手机端todo
idea中GBK代码转换成UTF-8格式 Ctrl+C+V一秒 解决单个代码文件转义 完美解决方法
二叉树 题目合集
软件测试流程
day03----测试用例扩充
[原创]软件测试实例指导
第二天总结及测试用例作业
深入浅出掌握接口自动化-01
Introduction to espif ESP AWS IOT
其他测试: 回归测试 , 冒烟测试 , 随机测试
PHP一句话木马-易错的语法-初学记录