当前位置:网站首页>零样本学习&Domain-aware Visual Bias Eliminating for Generalized Zero-Shot Learning
零样本学习&Domain-aware Visual Bias Eliminating for Generalized Zero-Shot Learning
2022-07-31 05:31:00 【右边是我女神】
文章目录
提出背景
在有限的类别中,感知到未知类别。
有监督、弱监督、无监督学习与ZSL的区别在于,测试时,测试标签种类超过训练标签种类。
ZSL的常见问题
跨数据集偏差
imagenet和自己的数据集之前的差别很大的话,预训练模型的视觉特征的表示能力会比较差。
异构特征对齐
(公共子空间中)视觉特征和语义特征需要对齐,但是这两个特征属于异构特征,因此难以对其。
本真语义表示
不同动物的尾巴不一样,难以表示一个细粒度的特征。
Domain-aware Visual Bias Eliminating for Generalized Zero-Shot Learning
Abstract
传统的零次学习目的是从可见与不可见的domain中识别图像。
最近的方法聚焦于学习一个联合的语义对齐视觉表征来在两个domain中迁移知识,然而这却忽视了semantic-free visual representation对于缓解偏差认知问题的影响。
为了解决这个问题,提出了Domain-aware Visual Bias Eliminating network。
什么是semantic-aligned visual representation?
什么是semantic-free visual representation?
如何结合这两种representation?
什么是biased recognition problem?
cross-attentive second-order visual statistics和adaptive margin Softmax的原理?
如何自动搜索一个优化的semantic-visual alignment architecture?
Introduction
通用的GZSL范式是在连接的语义空间中对齐视觉图像和语义标签。这样一种对齐转换成了最近邻搜索。
在joint space中,语义嵌入和视觉表征被视为class anchor和input queries。
然而,提供的语义标签通常并不具有区分度。因此,在semantic-visual对齐中,类内的差异被削弱的,从而进一步导致了biased recognition problem,也就是说unseen images被识别为seen classes。
为了解决上述问题,最近的工作聚焦于扩大视觉表征区分。但是,只要他们为了知识迁移而对齐语义标签,它们就会遭受视觉区分度不足的问题。
于是,本文考虑学习一个额外的semantic-free的视觉表征。高度区分的表征不仅能够提升seen class的预测,还能够筛选出unseen images。
DVBE的作用是构建出两个互补的视觉特征。具体而言,其聚焦于两个问题:
- 如何提升semantic-free representation 的区分度来提升domain detection的精确度。
- 如何设计semantic-visual对齐结构来得到鲁棒的知识迁移;
DVBE包含两个子模块AMSE和autoS2V。
Related Works
产生biased recognition problem的主要问题是提供的提供的语义标签区分度不强。
改进的方法都需要将视觉表征和语义标签对齐,所以会受到弱语义区分度的影响。
GZSL的范式
Zero-Shot Visual Recognition using Semantics-Preserving Adversarial Embedding Networks
属于visual2semantic embedding的方法。
本身GZSL就是一个挑战,在测试的时候,模型会倾向于对未见类样例标注为已见类的标签,进而导致识别的准确率和传统零样本学习相比大幅下降。
semantic-visual alignment?
描述同一类别对象的图像和描述之间建立语义对应的关系。
biased recognition problem?
(ZSL中)映射域偏移(domain shift)问题:根源在于映射模型较差的泛化能力,模型使用了训练类样本学习由样例特征空间到类标签语义空间的映射,由于没有测试类的未见类样例可以用于训练,因此,在映射测试类的输入样例的时候会产生一定的偏差。
由于GZSL中,测试时加入了已见类,所以偏差加剧为了认知错误,即将未见图像识别为已见类。
Domain-aware Visual Bias Eliminating
广义零次学习的目的在于从seen和unseen的domains中识别图像。

如果两个类有许多相同的语义标签,那么属于这两个类的视觉表征也很难去区分。不幸的是,在两个domain中,提供的语义标签通常有一个很小的区别,这使得 f ( x u ) , f ( x v ) f(x_u),f(x_v) f(xu),f(xv)很相似,以致于 x u x_u xu会和 a s a_s as配对上。
Formulation
除了学习semantic-aligned的视觉表征模型之外,还额外引入了semantic-free的视觉表征模型 f d ( x ) f_d(x) fd(x),这一模型在 { x s , y s } \{x_s,y_s\} { xs,ys}上训练。
尽管没有了语义相关性, f d f_d fd无法预测unseen classes,但是还是能够基于seen class prediction entropy筛选出unseen image,这样就能保证 f v f_v fv推断unseen classes。
于是乎,上述的模型就演变为了: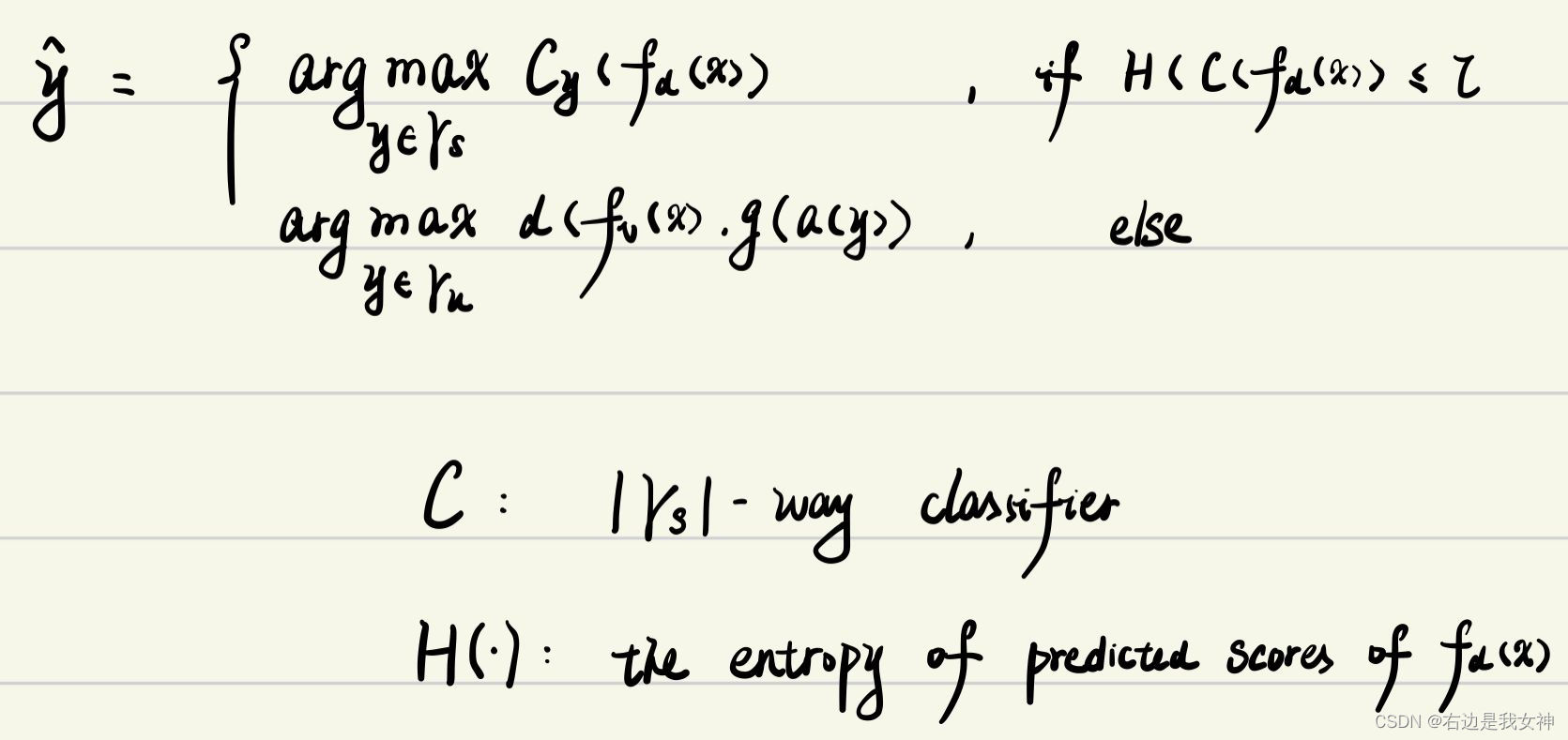
熵越大反映了这个模型越可能属于unseen类。
沿着Introduction的思路,所以说,DVBE的思路有两点:
- 如何设计一个 f d f_d fd,来使得seen类的识别精度尽可能高
- 如何设计 f v , g f_v,g fv,g,来沟通semantic-visual的沟壑,使得unseen class prediction更加正确。
Adaptive Margin Second-order Embedding
先前的工作表明,如果视觉表征足够有区分度,那么分布之外的图像能够通过基于熵的检测器筛选出来。
AMSE是基于bilinear pooling的。
双线性池化源自于细粒度图像分类领域。
由于双线性池化,噪声元素也同样被放大了,也就是说,噪声会和其他的元素有相互作用。
为了减小噪声特征的消极作用,使用cross-attentive channel interaction实现紧凑的特征表示。

优势在于:
- 两个不同的注意力函数能够有效消除不重要的特征;
- cross-attentive的方法能够提升inputs complementarity。
为了进一步扩大这个 f d f_d fd函数的判别能力,AMSE应用了一个适应性的margin Softmax来最大化类间的区别。

不同的是,Lams在y和Y/y之间强加了一个间隔惩罚。
在这篇工作中, λ \lambda λ的计算公式为 λ = e − ( p y ( x ) − 1 ) 2 / σ 2 \lambda=e^{-(p_y(x)-1)^2/\sigma^2} λ=e−(py(x)−1)2/σ2
其中, p y ( x ) p_y(x) py(x)是 x x x属于 y y y的可能性大小。
当置信度为1的时候, λ → 1 \lambda\to1 λ→1,于是成为了一个标准正态分布,反之,对于难样本, λ \lambda λ小,那么损失函数的值大,于是间隔约束大,更多的注意力就放在了这个样本身上。
这里因为采用了一个非线性的函数,所以说能够防止模型被约束地过于严格,比如说用一个大的margin约束一个简单的样本。
区别于focal loss的是,Lams在决策边界之间采用高斯margin约束,这更加具有可解释性。
最终Lams相比于标准的Softmax损失,确保 f d f_d fd拥有一个更大的类间差异。
bilinear pooling
双线性池化用于特征融合,对于从同一个样本提取出来的特征x和特征y,通过双线性池化得到两个特征融合后的向量,进而用来分类。
如果特征 x , y x,y x,y相等,那么称为同源双线性池化或者二阶池化,这里就是说两个特征提取器是一致的。
直观上来说,是将同一位置上的两个特征双线性融合(相乘)之后,得到矩阵b,然后对所有位置的b进行sum pooling,再reshape成一个向量,称之为bilinear vector。
为什么双线性池化好用呢?
second-order pooling
同源双线性池化,能够度量通道之间(特征之间)的相关性,每一个元素指的是每一通道的feature map与另一通道的feature map之间的相关性,对角元素提供了不同特征图之各自的信息,其余元素提供了不同特征图之间的关系,有助于把握整个图像的大体风格,这样一个矩阵既体现了有哪些特征又体现出不同特征之间的紧密程度。
二阶池化的意思是提取其中的间接信息。
softmax中的margin控制
通常而言,我们在用softmax时,只是要求其能够输出C个分数,然后使得目标分数比非目标分数更大,为了不让分数无限制地上升或下降,所以一般会让损失函数表现为 L = ∑ i = 1 , i ≠ y C max ( z i − z y , 0 ) L=\sum_{i=1,i\not=y}^C\max(z_i-z_y,0) L=i=1,i=y∑Cmax(zi−zy,0)
但是这样子做的话,当目标分数刚超过非目标分数,就会停止更新,从而泛化性能下降。于是乎,我们可以借鉴SVM中的间隔的概念,让目标分数超过非目标分数一定数值才停止,比如 L h i n g e = ∑ i = 1 , i ≠ y C max ( z i − z y + m , 0 ) L_{hinge}=\sum_{i=1,i\not=y}^C\max(z_i-z_y+m,0) Lhinge=i=1,i=y∑Cmax(zi−zy+m,0)
我们将优化问题换一种措辞,输出C个分数,使得目标分数比最大的非目标分数更大,损失函数表现为 L = max ( max i ≠ y ( z i ) − z y , 0 ) L=\max(\max_{i\not= y}(z_i)-z_y,0) L=max(i=ymax(zi)−zy,0)
max函数的平滑版本是LogSumExp: L l s e = max ( log ( ∑ i = 1 , i ≠ y C e z i ) − z y , 0 ) L_{lse}=\max(\log(\sum_{i=1,i\not=y}^Ce^{ {z_i}})-z_y,0) Llse=max(log(i=1,i=y∑Cezi)−zy,0)
使用LogSumExp相当于变相地加了一定的m。
softmax交叉熵损失函数在此基础上进一步进行了平滑,成为了 L s o f t m a x = log ( 1 + e log ( ∑ i = 1 , i ≠ y C e z i ) − z y ) = − log e z y ∑ i = 1 C e z i L_{softmax}=\log(1+e^{\log(\sum_{i=1,i\not=y}^Ce^{z_i})-z_y})=-\log\frac{e^{z_y}}{\sum_{i=1}^Ce^{z_i}} Lsoftmax=log(1+elog(∑i=1,i=yCezi)−zy)=−log∑i=1Ceziezy
这就是最后的交叉熵损失函数。
本身是带有一定的margin的。
SVM的理论核心就是加大margin可以使得“结构风险最小化”。
这里在加权的基础上额外增加了间隔系数,相当于缩放了目标分数,于是乎,进一步放大了间隔的需要。
Auto-searched Semantic-Visual Embedding
根据范式,AutoS2V模块包含两个函数,分别是视觉、语义映射函数。
大部分现有的方法是将g手工设计,与fv比较相似。
然而,视觉和语义信号有显著的gap,因此不能设计得一样。
AutoS2V自动地为g搜寻一个优化的结构。
函数g被视为一个有多个节点的有向无环图,每个节点与之前所有节点连接,并在两个连接的节点之间进行的操作从操作集中选择。
其中操作集包括全连接、图卷积、跳跃连接和空。
值得注意的是,图卷积是一种特定于任务的操作,是建模拓扑关系的专家。
为了搜索在两个节点之间搜索一个优化的操作,我们将选择放宽为一个softmax的优化问题。
Overall
L a l l = L s 2 v + L a m s + γ L c e t L_{all}=L_{s2v}+L_{ams}+\gamma L_{cet} Lall=Ls2v+Lams+γLcet
L c e t L_{cet} Lcet是为了避免所有的fv坍缩到一个点。
Expriments
数据集:
对于目标分类任务:CUB、SUN、AWA2、aPY;
对于分割任务:VOC;
对于目标分类任务:
MCA: M C A = 1 ∥ γ ∥ ∑ c = 1 ∥ γ ∥ c 中正确的数量 c 中样本数量 MCA=\frac{1}{\|\gamma\|}\sum_{c=1}^{\|\gamma\|}\frac{c中正确的数量}{c中样本数量} MCA=∥γ∥1c=1∑∥γ∥c中样本数量c中正确的数量
H: H = 2 M A C u × M C A s M C A u + M C A s H=\frac{2MAC_u\times MCA_s}{MCA_u+MCA_s} H=MCAu+MCAs2MACu×MCAs
PA:类别正确的像素个数占总的像素数的比例
mIOU:平均交并比
hIOU:mIOU的调和平均数
消融实验
- 超参数 τ \tau τ;
- semantic-free visual representation的影响:证明其更有区分度;
- cross-attentive channel interaction;
- Adaptive margin Softmax;
- Auto-searched;
Conclusion
本篇文章提出了DVBE network来解决GZSL中的biased recognition problem。
区别于先前聚焦于semantic-aligned表征的方法,本文还考虑了semantic-free表征。
为了进一步提升semantic-free表征的视觉判别能力,本文提出了adaptive margin second-order embedding(cross-attentive channel interaction 和 adaptive margin Softmax)。
此外,本文还自动地搜索了一个optimal semantic-visual 结构来产生鲁棒的semantic-aligned representation。
最终,通过搜索这两种互补的视觉特征,DVBE表现优异。
边栏推荐
猜你喜欢






随机推荐
性能测试概述
Oracle入门 09 - Linux 文件上传与下载
银河麒麟V10 sp1服务器安装英伟达显卡驱动
项目练习——备忘录(增删改查)
常用命令讲解
Basic usage of Koa framework
Oracle入门 10 - Linux 设备类型与文件目录结构
浅层了解欧拉函数
深度解析 z-index
浅析重复线性渐变repeating-linear-gradient如何使用
11.0 堆参数调优入门之堆参数调整
@ConfigurationProperties和@EnableConfigurationProperties
防抖和节流
Oracle入门 11 - Linux 开关机及系统进程命令
记录一下,今天开始刷剑指offer
Skywalking UI使用
Debian 10 dhcp 服务配置
数据驱动,
Hook API
OSI七层模型