当前位置:网站首页>ACL 2022 | 预训练语言模型和图文模型的强强联合
ACL 2022 | 预训练语言模型和图文模型的强强联合
2022-06-12 02:02:00 【智源社区】
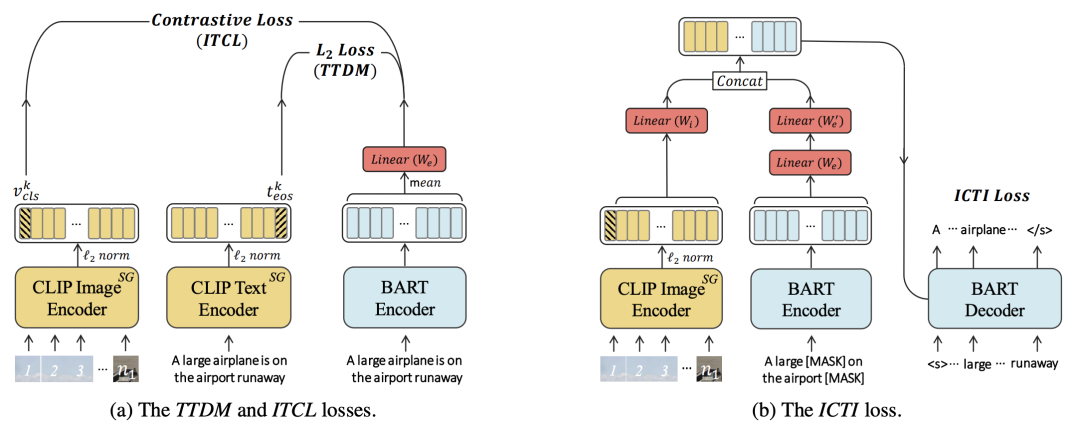
ACL 2022华为发表了一篇论文:Enabling Multimodal Generation on CLIP via Vision-Language Knowledge Distillation(VLKD)。这篇文章将CLIP的跨模态能力以及预训练语言模型的BART的生成能力进行联合,实现了对CLIP模型text encoder的加强,在VQA、Caption等多个任务上都取得非常好的效果。

论文链接:
https://arxiv.org/abs/2203.06386
VLKD的整体结构非常简单,如下图所示,将原来CLIP模型中的text encoder替换成预训练BART的encoder + decoder,通过知识蒸馏的方式让BART的encoder和decoder学到CLIP中的跨模态知识。这里的跨模态知识,指的是让BART能够处理图像信息,借助CLIP中已经将图像和文本的表示映射到同一空间的能力,将BART对文本的表示也映射到这一空间。
边栏推荐
- Wide match modifier symbol has been deprecated, do not use
- C asynchronous programming from simple to deep (III) details awaiter
- LeetCode LCP 07. 传递信息
- [C language] C language file operation | C language file reading and writing | single character reading and writing | string reading and writing | format reading and writing | binary form reading and
- Comprehensive quality of teaching resources in the second half of 2019 - subjective questions
- Quatre schémas de mise en file d'attente des messages pour redis
- [C language] summary of basic knowledge points of pointer
- 通用树形结构的迭代与组合模式实现方案
- Database
- How to restore the redis cluster and retain the complete cluster data after changing the node IP
猜你喜欢

螺旋矩阵(技巧)
redis集群(cluster)+哨兵模式+主从(replicas)

Basedexclassloader

pip运行报错:Fatal error in launcher: Unable to create process using

The release of star ring kundb 2.2 provides a new choice for business systems with high concurrent transactions and queries

TIOBE - 2022年6月编程语言排行
Redis实现消息队列的4种方案

自适应搜索广告有哪些优势?

SQL calculates KS, AUC, IV, psi and other risk control model indicators

Operating mechanism of Google ads bidding
随机推荐
lua 函数
PHP builds a high-performance API architecture based on sw-x framework (III)
Tiobe - programming language ranking in June 2022
PHP security development 13 column module of blog system
LeetCode LCP 07. 传递信息
Ozzanmation action system based on SSE
Unit tests in golang
Linux(CentOS7)安裝MySQL-5.7版本
Basic use of MATLAB
Summary of concrete (ground + wall) + Mountain crack data set (classification and target detection)
国资入股,建业地产这回稳了吗?
MySQL advanced knowledge points
Websocket is closed after 10 seconds of background switching
Linux(CentOS7)安装MySQL-5.7版本
Linux (centos7) installer mysql - 5.7
打包一个包含手表端应用的手机端APK应用—Ticwear
Graphical data analysis | business analysis and data mining
android html5页面加载缓存优化
Redis实现消息队列的4种方案
C language programming classic games - minesweeping