当前位置:网站首页>Structured Streaming报错记录:Overloaded method foreachBatch with alternatives
Structured Streaming报错记录:Overloaded method foreachBatch with alternatives
2022-07-30 20:37:00 【7&】
【文章目录】
Structured Streaming报错记录:Overloaded method foreachBatch with alternatives
0. 写在前面
- Spark :
Spark3.0.0 - Scala :
Scala2.12
1. 报错
overloaded method value foreachBatch with alternatives:
2. 代码及报错信息
Error:(48, 12) overloaded method value foreachBatch with alternatives:
(function:org.apache.spark.api.java.function.VoidFunction2[org.apache.spark.sql.Dataset[org.apache.spark.sql.Row],java.lang.Long])org.apache.spark.sql.streaming.DataStreamWriter[org.apache.spark.sql.Row]
(function: (org.apache.spark.sql.Dataset[org.apache.spark.sql.Row], scala.Long) => Unit)org.apache.spark.sql.streaming.DataStreamWriter[org.apache.spark.sql.Row]
cannot be applied to ((org.apache.spark.sql.Dataset[org.apache.spark.sql.Row], Any) => org.apache.spark.sql.Dataset[org.apache.spark.sql.Row])
.foreachBatch((df, batchId) => {
import java.util.Properties
import org.apache.spark.sql.streaming.{
StreamingQuery, Trigger}
import org.apache.spark.sql.{
DataFrame, SparkSession}
object ForeachBatchSink1 {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local[*]")
.appName("ForeachSink1")
.getOrCreate()
import spark.implicits._
val lines: DataFrame = spark.readStream
.format("socket") // 设置数据源
.option("host", "cluster01")
.option("port", 10000)
.load
val props = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "1234")
val query: StreamingQuery = lines.writeStream
.outputMode("update")
.foreachBatch((df, batchId) => {
val result = df.as[String].flatMap(_.split("\\W+")).groupBy("value").count()
result.persist()
result.write.mode("overwrite").jdbc("jdbc:mysql://cluster01:3306/test","wc", props)
result.write.mode("overwrite").json("./foreach1")
result.unpersist()
})
// .trigger(Trigger.ProcessingTime(0))
.trigger(Trigger.Continuous(10))
.start
query.awaitTermination()
}
}
/**
- Error:(43, 12) overloaded method value foreachBatch with alternatives:
- (function:org.apache.spark.api.java.function.VoidFunction2[org.apache.spark.sql.Dataset[org.apache.spark.sql.Row],java.lang.Long])org.apache.spark.sql.streaming.DataStreamWriter[org.apache.spark.sql.Row]
- (function: (org.apache.spark.sql.Dataset[org.apache.spark.sql.Row], scala.Long) => Unit)org.apache.spark.sql.streaming.DataStreamWriter[org.apache.spark.sql.Row]
- cannot be applied to ((org.apache.spark.sql.Dataset[org.apache.spark.sql.Row], Any) => org.apache.spark.sql.DataFrame)
- .foreachBatch((df, batchId) => {
*/
import java.util.Properties
import org.apache.spark.sql.streaming.{
StreamingQuery, Trigger}
import org.apache.spark.sql.{
DataFrame, SparkSession}
object ForeachBatchSink {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local[*]")
.appName("ForeachSink")
.getOrCreate()
import spark.implicits._
val lines: DataFrame = spark.readStream
.format("socket") // 设置数据源
.option("host", "cluster01")
.option("port", 10000)
.load
val props = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "1234")
val query: StreamingQuery = lines.writeStream
.outputMode("complete")
.foreachBatch((df, batchId) => {
result.persist()
result.write.mode("overwrite").jdbc("jdbc:mysql://cluster01:3306/test","wc", props)
result.write.mode("overwrite").json("./foreach")
result.unpersist()
})
.start
query.awaitTermination()
}
}
3. 原因及纠错
Scala2.12版本和2.11版本的不同,对于foreachBatch()方法的实现不太一样
正确代码如下
import java.util.Properties
import org.apache.spark.sql.streaming.StreamingQuery
import org.apache.spark.sql.{
DataFrame, Dataset, Row, SparkSession}
object ForeachBatchSink {
def myFun(df: Dataset[Row], batchId: Long, props: Properties): Unit = {
println("BatchId" + batchId)
if (df.count() != 0) {
df.persist()
df.write.mode("overwrite").jdbc("jdbc:mysql://cluster01:3306/test","wc", props)
df.write.mode("overwrite").json("./StructedStreaming_sink-ForeachBatchSink")
df.unpersist()
}
}
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local[2]")
.appName("ForeachBatchSink")
.getOrCreate()
import spark.implicits._
val lines: DataFrame = spark.readStream
.format("socket") // TODO 设置数据源
.option("host", "cluster01")
.option("port", 10000)
.load
val wordCount: DataFrame = lines.as[String]
.flatMap(_.split("\\W+"))
.groupBy("value")
.count() // value count
val props = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "1234")
val query: StreamingQuery = wordCount.writeStream
.outputMode("complete")
.foreachBatch((df : Dataset[Row], batchId : Long) => {
myFun(df, batchId, props)
})
.start
query.awaitTermination()
}
}
import java.util.Properties
import org.apache.spark.sql.streaming.{
StreamingQuery, Trigger}
import org.apache.spark.sql.{
DataFrame, Dataset, Row, SparkSession}
object ForeachBatchSink1 {
def myFun(df: Dataset[Row], batchId: Long, props: Properties, spark : SparkSession): Unit = {
import spark.implicits._
println("BatchId = " + batchId)
if (df.count() != 0) {
val result = df.as[String].flatMap(_.split("\\W+")).groupBy("value").count()
result.persist()
result.write.mode("overwrite").jdbc("jdbc:mysql://cluster01:3306/test","wc", props)
result.write.mode("overwrite").json("./StructedStreaming_sink-ForeachBatchSink1")
result.unpersist()
}
}
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local[2]")
.appName("ForeachBatchSink1")
.getOrCreate()
import spark.implicits._
val lines: DataFrame = spark.readStream
.format("socket") // TODO 设置数据源
.option("host", "cluster01")
.option("port", 10000)
.load
val props = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "1234")
val query: StreamingQuery = lines.writeStream
.outputMode("update")
.foreachBatch((df : Dataset[Row], batchId : Long) => {
myFun(df, batchId, props, spark)
})
.trigger(Trigger.Continuous(10))
.start
query.awaitTermination()
}
}
4. 参考链接
https://blog.csdn.net/Shockang/article/details/120961968
边栏推荐
- ENS 表情包域名火了!是炒作还是机遇?
- [Typora] This beta version of Typora is expired, please download and install a newer version.
- 使用map函数,对list中的每个元素进行操作 好像不用map
- MySQL的Replace用法详解
- GateWay实现负载均衡
- TensorFlow2:概述
- excel数字下拉递增怎么设置?
- Can't find the distributed lock of Redisson?
- MySQL 视图(详解)
- [PM only] Quickly count who else in the team has not registered and reported information, and quickly screen out the members of their own project team who have not completed the list of XXX work items
猜你喜欢
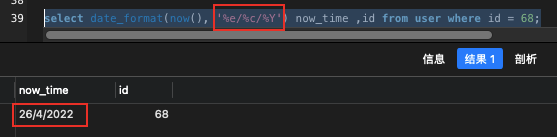
MySQL的DATE_FORMAT()函数将Date转为字符串
想要写出好的测试用例,先要学会测试设计

基于Apache Doris的湖仓分析

WPS没有在任务栏显示所有窗口选项怎么回事?

Babbitt | Metaverse Daily Must Read: The shuffling is coming, will the digital Tibetan industry usher in a new batch of leaders in the second half?Will there be new ways to play?...
【Codeforces思维题】20220728

4年测试经验去面试10分钟就被赶出来了,面试官说我还不如应届生?都这么卷吗...
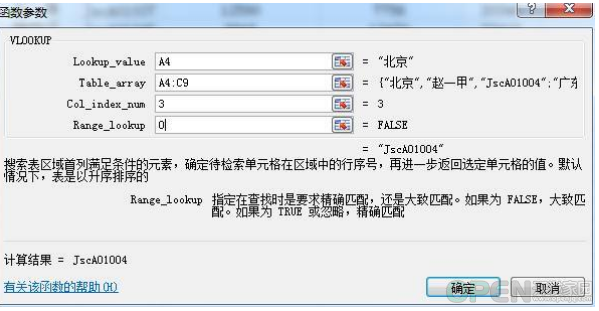
vookloop函数怎么用?vlookup函数的使用方法介绍
TensorFlow2: Overview
![Recommendation System - Sorting Layer - Model (1): Embedding + MLP (Multilayer Perceptron) Model [Deep Crossing Model: Classic Embedding + MLP Model Structure]](/img/bb/25b0493398901b52d40ff11a21e34c.png)
Recommendation System - Sorting Layer - Model (1): Embedding + MLP (Multilayer Perceptron) Model [Deep Crossing Model: Classic Embedding + MLP Model Structure]
随机推荐
Recommendation System - Sorting Layer - Model (1): Embedding + MLP (Multilayer Perceptron) Model [Deep Crossing Model: Classic Embedding + MLP Model Structure]
推荐系统-排序层:排序层架构【用户、物品特征处理步骤】
ECCV2022 | 对比视觉Transformer的在线持续学习
MySQL 高级(进阶) SQL 语句 (一)
2022年SQL经典面试题总结(带解析)
Face-based Common Expression Recognition (2) - Data Acquisition and Arrangement
7.联合索引(最左前缀原则)
Recommendation system-model: FNN model (FM+MLP=FNN)
微信读书,导出笔记
vlookup函数匹配不出来只显示公式的解决方法
使用map函数,对list中的每个元素进行操作 好像不用map
mysql 递归函数with recursive的用法
多线程获取官方汇率
基于人脸的常见表情识别(1)——深度学习基础知识
excel数字下拉递增怎么设置?
Difference Between Concurrency and Parallelism
Mysql 回表
Activiti 工作流引擎 详解
bebel系列- 插件开发
银行数据资产转换能力弱?思迈特软件助力解决银行困境