当前位置:网站首页>Active learning overview, strategy and uncertainty measurement
Active learning overview, strategy and uncertainty measurement
2022-06-22 04:18:00 【deephub】
Active learning refers to the process of prioritizing the data to be marked , In this way, we can determine which data have the greatest impact on the training supervision model .
- Active learning is a learning algorithm that can interactively query users (teacher or oracle), Strategy of labeling new data points with real labels . The process of active learning is also called optimizing experimental design .
- The motivation for active learning is to recognize that not all labeled samples are equally important .
- Active learning can greatly reduce the amount of labeled data required by the training model by prioritizing the labeling work of experts . cost reduction , At the same time, improve the accuracy .
- Active learning is a strategy / Algorithm , Is an enhancement to the existing model . Not a new model architecture .
- Active learning is easy to understand , Not easy to implement
The key idea behind active learning is , If the machine learning algorithm is allowed to select the data it learns , This allows for greater accuracy with fewer training tags .——Active Learning Literature Survey, Burr Settles
Introduction to active learning
Active learning is not about collecting all the tags for all the data at once , It prioritizes the data that is most difficult for the model to understand , And label only those data . Then the model trains a small amount of labeled data , After the training, it is required to mark the most uncertain data again .
By prioritizing uncertain samples , Models allow experts ( artificial ) Focus on providing the most useful information . This helps the model learn faster , And let experts skip data that is not very helpful to the model . In some cases , It can greatly reduce the number of labels that need to be collected from experts , And you can still get a good model . This can save time and money for machine learning projects !
Active learning strategies
There are many papers on how to determine data points and how to iterate on the method . The most common and direct methods will be introduced in this article , Because this is the simplest and easiest to understand .
The steps to use active learning on unlabeled datasets are :
- The first thing to do is to manually mark a very small sub sample of the data .
- Once there is a small amount of tag data , You need to train them . The model is certainly not great , But it will help us understand which areas of the parameter space need the first tag .
- After training the model , The model is used to predict the category of each remaining unlabeled data point .
- According to the prediction of the model , Select a score on each unlabeled data point ( In the next section , Some of the most commonly used scores will be introduced )
- Once you have chosen the best way to prioritize the tags , This process can be iteratively repeated : The new model is trained on the new label data set marked based on the priority score . Once the new model is trained on the data subset , Unmarked data points can be run in the model and the priority score can be updated , Continue to mark .
In this way , As the model gets better , We can constantly optimize the labeling strategy .

Active learning method based on data flow
In flow based active learning , The set of all training samples is presented to the algorithm in the form of flow . Each sample is sent to the algorithm separately . The algorithm must immediately decide whether to mark this example . The training samples selected from this pool are oracle( Labor industry experts ) Mark , Before displaying the next sample , The tag is immediately received by the algorithm .
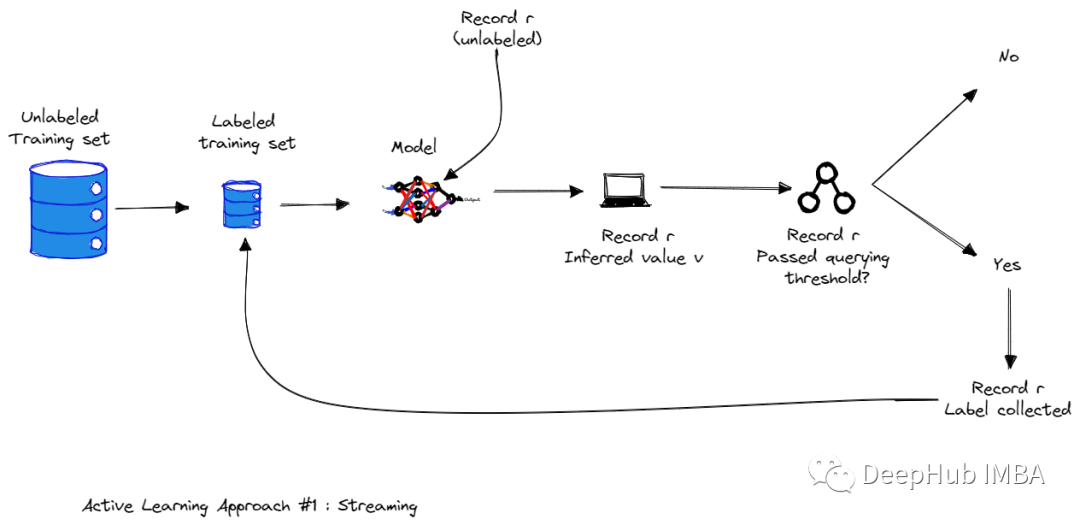
Active learning method based on data pool
In pool based sampling , The training sample is selected from a large unlabeled data pool . The training samples selected from this pool are oracle Mark .

Query based active learning method
This committee query based approach uses multiple models instead of one .
The Committee inquired about (Query by Committee), It maintains a collection of models ( The assembly is called a committee ), By inquiring ( vote ) Choose the most “ Controversial ” As the next data point to be marked . Through this model, the committee can overcome the restrictive assumptions that can be expressed by a single model ( And we don't know what assumptions to use at the beginning of the task ).
Uncertainty measurement
The process of identifying the most valuable samples that need to be marked next is called “ Sampling strategy ” or “ Query strategy ”. The scoring function in this process is called “acquisition function”. The meaning of this score is : The data points with higher scores are marked , The higher the value of model training ( Not as good as the model ). There are many different sampling strategies , For example, uncertainty sampling , Diversity sampling , Expected model changes …, In this paper , We will focus only on the measurement of uncertainty for the most commonly used strategies .
Uncertainty sampling is a set of techniques , It can be used to identify unlabeled samples near the decision boundary in the current machine learning model . The most informative example here is the most uncertain example of the classifier . The most uncertain sample of the model may be the data near the classification boundary . Our model learning algorithm will obtain more information about class boundaries by observing the most difficult samples .
Let's take a concrete example , Suppose you are trying to build a multi class classification , To distinguish 3 Cat like , Dog , Horse . The model may give us the following predictions :
{
"Prediction": {
"Label": "Cat",
"Prob": {
"Cat": 0.9352784428596497,
"Horse": 0.05409964170306921,
"Dog": 0.038225741147994995,
}
}
}
This output is likely to come from softmax, It uses exponents to convert logarithms to 0-1 Score of the range .

Minimum confidence :(Least confidence)
Minimum confidence =1(100% Degree of confidence ) And the difference between the most confident labels of each project .
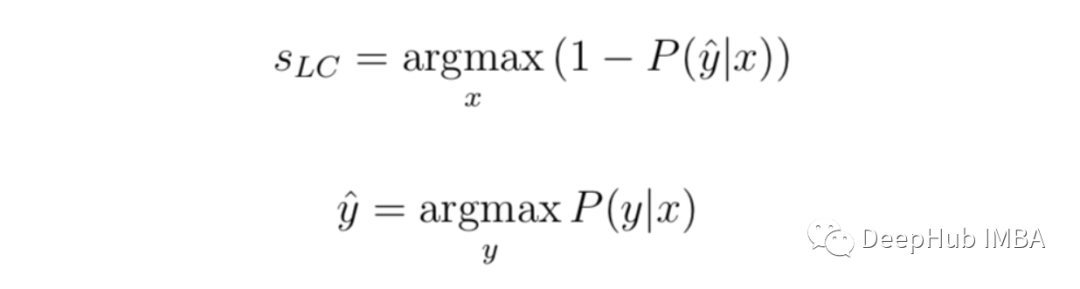
Although it can be ranked separately in the order of confidence , But convert the uncertainty score to 0-1 Range , among 1 Is the most uncertain score that can be useful . Because in this case , We must standardize our scores . We from 1 Subtract this value from , Multiply the result by N/(1-N),n Is the number of tags . At this time, because the minimum confidence will never be less than the number of tags ( When all tags have the same predictive confidence ).
Let's apply it to the above example , The uncertainty score will be :(1-0.9352) *(3/2)= 0.0972.
Minimum confidence is the simplest , The most common method , It provides a ranking of the prediction order , In this way, the prediction tag can be sampled with the lowest confidence .
Confidence sampling interval (margin of confidence sampling)
The most intuitive form of uncertainty sampling is the difference between two predictions with high confidence . in other words , How big is the difference between the tags predicted by the model and the second highest tag ? This is defined as :
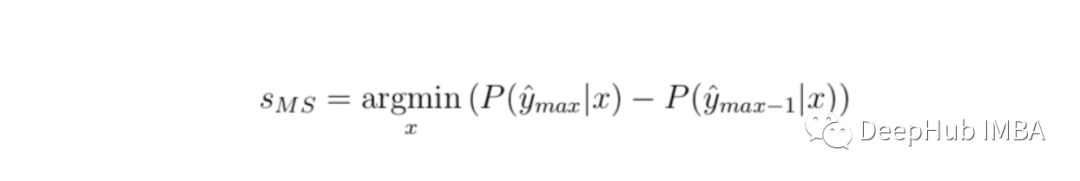
Again, we can convert it to 0-1 Range , Must be used again 1 Subtract the value , But the maximum possible score is 1 了 , So there is no need to do anything else .
Let's apply the confidence sampling interval to the sample data above .“ cat ” and “ Horse ” It's the first two . Use our example , This uncertainty score will be 1.0 - (0.9352–0.0540)= 0.1188.
Sampling ratio (Ratio sampling)
The confidence ratio is the change in the confidence margin , Is the ratio of the difference between two scores, not the absolute value of the difference between the two scores .

Entropy sampling (Entropy Sampling)
The entropy applied to the probability distribution consists of multiplying each probability by its own logarithm , Then sum and take the negative number :

Let's calculate entropy on the sample data :

obtain 0 - sum(–0.0705,–0.0903,–0.2273)= 0.3881
Divided by the number of tags log obtain 0.3881/ log2(3)= 0.6151
summary
Much of the focus of the machine learning community is on creating better algorithms to learn from data . It is very important to obtain useful labeled data in training , But labeling data can be very laborious , And if the quality of annotation is poor, it will also have a great impact on the training . Active learning is a way to solve this problem , And it is a very good direction .
https://avoid.overfit.cn/post/26eeaad603b540dbba4962c9179f6c64
author :Zakarya ROUZKI
边栏推荐
- Code of ultrasonic rangefinder based on 51 (screenshot version)
- Storage structure of tree
- Dameng database client shielding SQL keyword
- What are the useful work reporting tools
- active RM机子断电后,RM HA切换正常。但是YarnUI上查看不到集群资源,application也一直处于ACCEPTED状态。
- Solend闹剧背后的「DeFi道德悖论」
- Kubernetes cluster log management
- Spark - Executor 初始化 && 报警都进行1次
- Larave 数据库备份 定时任务
- Basic operation of sequence table
猜你喜欢

【写文章神器】标记语言Markdown的使用
首个女性向3A手游要来了?获IGN认可,《以闪亮之名》能否突出重围

Internet of things UWB technology scheme, intelligent UWB precise positioning, centimeter level positioning accuracy
Use of markdown markup language

Insert sort

Twitter如何去中心化?看看这十个SocialFi项目

Invalid character found in request destination. Valid characters are defined in RFC 7230 and RFC 3986
Online document collaboration: a necessary efficient artifact for office

Basic operation of sequence table
插入排序
随机推荐
Window common shortcut keys
Replacement has 2 rows, data has 0, to solve how R language dynamically generates dataframes
POSIX semaphore
Laravel implements soft deletion
PHP determines whether the current time has exceeded
EcRT of EtherCAT igh source code_ slave_ config_ Understanding of dc() function.
冒泡排序
Empty, isset and is of PHP_ Null difference
Fluent syntax configuration
Huffman tree
Convenient and easy to master, vivo intelligent remote control function realizes the control of household appliances in the whole house
树的存储结构
PCM data format
Experience and summary of embedded software testing
顺序表的基本操作
图的基本概念
Django learning - model and database operation (II)
BFs of figure
Twitter如何去中心化?看看这十个SocialFi项目
Raspberry pie preliminary use