当前位置:网站首页>【论文阅读|深读】DANE:Deep Attributed Network Embedding
【论文阅读|深读】DANE:Deep Attributed Network Embedding
2022-06-30 03:33:00 【海轰Pro】
目录

前言
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
自我介绍 ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研。
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力
知其然 知其所以然!
本文仅记录自己感兴趣的内容
Abstract
近年来,网络嵌入引起了越来越多的关注
它是为了学习网络中节点的低维表示,有利于后续的任务,如节点分类和链路预测
大多数现有的方法只基于拓扑结构来学习节点表示
然而在许多实际应用程序中,节点常常与丰富的属性相关联
因此,学习基于拓扑结构和节点属性的节点表示是非常重要和必要的
本文
- 提出了一种新的深度属性网络嵌入方法,该方法既能捕获高非线性,又能保持拓扑结构和节点属性的各种邻近性
- 提出了一种新的策略,保证学习到的节点表示能够从拓扑结构和节点属性中编码出一致和互补的信息
1 Introduction
网络在现实世界中无处不在,如社交网络、学术引文网络和交流网络
在各种网络中,属性网络近年来备受关注
与普通网络只有拓扑结构不同,属性网络的节点拥有丰富的属性信息
这些信息属性有助于网络分析
例如,在一个学术引文网络中,不同文章之间的引文组成了一个网络,每个节点都是一篇文章
在这个网络中,每个节点都有关于文章主题的大量文本信息。另一个例子是社交网络,用户与他人联系,并将他们的个人资料作为属性
此外,社会科学表明节点的属性可以反映和影响其社区结构
因此,对带属性网络进行研究是十分必要和重要的。
网络嵌入作为一种分析网络的基本工具,近年来引起了数据挖掘和机器学习界的广泛关注。
它是为了学习网络中每个节点的低维表示,同时保持其邻近性。
然后,下游的任务,如节点分类、链路预测和网络可视化,可以受益于学习的低维表示
近年来,各种网络嵌入方法被提出,例如DeepWalk
然而,现有的方法大多集中在普通网络上,忽略了节点的有用属性
例如,在Facebook或Twitter这样的社交网络中,每个用户都与他人连接,构成一个网络。
在学习节点表示时,现有的方法大多只关注连接。但是每个节点的属性也可以提供有用的信息
用户个人资料就是一个很好的例子
一个年轻用户可能与另一个年轻人更相似,而不是一个老用户。
因此,在学习节点表示时,合并节点属性是很重要的
此外,网络的拓扑结构和属性是高度非线性的
因此,获取高度非线性的属性以发现底层模式是很重要的。这样,学习到的节点表示可以更好地保持接近性
然而,现有的大多数方法,如[Huang et al., 2017a;Yang等人,2015]只采用了浅层模型,未能捕捉到高度非线性的特性
此外,由于复杂的拓扑结构和属性,如何捕捉这种高度非线性的特性是困难的
因此,对于属性网络嵌入来说,如何获取高度非线性的特性是一个挑战
为了解决上述问题,我们提出了一种基于属性网络的深度属性网络嵌入(DANE)方法
详细地:
- 提出了一个深度模型来捕获底层的拓扑结构和属性的高非线性。同时,该模型能够强化学习到的节点表示,保持原始网络的第一阶和高阶邻近性
- 此外,为了从网络的拓扑结构和属性中学习一致和互补的表示,我们提出了一种新的策略,将这两种信息结合起来
- 此外,为了获得鲁棒的节点表示,提出了一种有效的最负采样策略,使损失函数具有鲁棒性
2 Related Works
2.1 Plain Network Embedding
网络嵌入可以追溯到图嵌入问题。代表性的方法有
- Laplacian eigenmap
- Locality Preserving Projection (LPP)
这些方法是在学习嵌入数据的同时保持局部流形结构,在传统的机器学习应用中得到了广泛的应用。
但是,这些方法都不适用于大规模的网络嵌入,因为它们都涉及耗时较长的特征分解操作,其时间复杂度为 O ( n 3 ) O(n^3) O(n3),其中 n n n为节点数
近年来,随着大规模网络的发展,各种各样的网络嵌入方法被提出
例如:
- DeepWalk通过观察随机漫步中的节点分布与自然语言中的单词分布相似,采用随机漫步和Skip-Gram来学习节点表示
- LINE提出在学习节点表示时保持一阶和二阶邻近性
- GraRep被提出以保持更高阶的接近性
- Node2Vec通过在柔性节点的邻域上设计有偏随机游走提出
但是,所有这些方法都只利用了拓扑结构,忽略了有用的节点属性
2.2 Attributed Network Embedding
对于有属性的网络,已经提出了各种各样的模型
例如
- [Yang et al., 2015]提出了一种归纳矩阵分解方法,将网络的拓扑结构和属性结合起来。但是,它本质上是一个线性模型,这对于复杂的属性网络是不够的
- [Huang等人,2017a;2017b]采用图拉普拉斯技术从拓扑结构和属性学习关节嵌入。
- [Kipf和Welling, 2016a]提出了一种用于属性网络的图卷积神经网络模型。但该模型是半监督的方法,无法处理无监督的情况。
- [Pan等人,2016]提出将DeepWalk与神经网络相结合来进行网络表示。尽管如此,DeepWalk仍然是一个肤浅的模型。
- 最近,两种无监督的深度属性网络嵌入方法[Kipf和Welling, 2016b;Hamilton et al., 2017]。但是,它们只能隐式地探索拓扑结构
因此,有必要探索一种更有效的深度属性网络嵌入方法
3 Deep Attributed Network Embedding
3.1 Problem Definition
G = { E , Z } G = \{E, Z\} G={ E,Z},一个属性网络,含有 n n n个节点
- E = [ E i j ] ∈ R n × n E = [E_ij] \in R^{n \times n} E=[Eij]∈Rn×n,邻接矩阵
- Z = [ Z i j ] ∈ R n × m Z= [Z_{ij}] \in R^{n \times m} Z=[Zij]∈Rn×m,属性矩阵
Definition 1. (First-Order Proximity)
给定一个网络 G = { E , Z } G=\{E,Z\} G={ E,Z}
- 两个节点 i i i和 j j j的一阶邻近度由 E i j E_{ij} Eij确定
- 具体地说,较大的 E i j E_{ij} Eij表示第 i i i个节点和第 j j j个节点之间的距离越近
一阶邻近度表示如果两个节点之间存在链接,则它们是相似的。除此之外,它们是不同的。因此,它可以被视为局部接近
Definition 2. (High-Order Proximity)
给定一个网络 G = { E , Z } G=\{E,Z\} G={ E,Z}
- 两个结点 i i i和 j j j的高阶邻近度由 M i ⋅ M_{i·} Mi⋅和 M j ⋅ M_{j·} Mj⋅的相似性决定
- 其中 M = E ^ + E ^ 2 + ⋅ ⋅ ⋅ + E ^ t M=\hat E+\hat E^2+···+\hat E^t M=E^+E^2+⋅⋅⋅+E^t是高阶邻接矩阵
- E ^ \hat E E^是邻接矩阵 E E E的逐行归一化得到的一步概率转移矩阵
高阶邻近度实际上表明了邻域的相似性。
具体地说,如果两个节点共享相似的邻居,则它们是相似的。除此之外,它们并不相似。
在这里,高阶接近可以被视为全局接近
Definition 3. (Semantic Proximity)
给定一个网络 G = { E , Z } G=\{E,Z\} G={ E,Z}
- 两个节点 i i i和 j j j的语义贴近度由 Z i ⋅ Z_{i·} Zi⋅和 Z j ⋅ Z_{j·} Zj⋅的相似度决定
语义接近表示如果两个节点具有相似的属性,则它们是相似的。除此之外,它们是不同的
属性网络嵌入是基于邻接矩阵 E E E和属性矩阵 Z Z Z学习每个节点的低维表示,使得学习的表示可以保持存在于拓扑结构和节点属性中的邻近性
形式上,我们的目标是学习一个映射 f : { E , Z } → H f:\{E,Z\}→H f:{ E,Z}→H,其中 H ∈ R n × d H\in R^{n×d} H∈Rn×d是节点表示
使得 H H H能够保持一阶邻近、高阶邻近和语义邻近
然后,可以在学习到的 H H H上执行下游任务,例如节点分类、链路预测
3.2 Deep Attributed Network Embedding
从本质上讲,属性网络嵌入面临三大挑战才能获得良好的嵌入效果。它们是:
- 高度非线性结构:拓扑结构和属性的底层结构是高度非线性的,因此很难捕捉到这种非线性
- 邻近度保持:属性网络中的邻近度既取决于网络的拓扑结构,也取决于网络的属性,因此如何发现和保持邻近度是一个棘手的问题。
- 拓扑结构和属性中的一致和互补信息:这两种信息为每个节点提供不同的视图,因此重要的是使学习的节点表示在这两种模式下保持一致和互补的信息。
为了解决这三个问题,我们提出了一种新的深度属性网络嵌入方法(DANE)。该体系结构如图1所示

总体而言,有两个分支:
- 第一个分支由一个多层非线性函数组成,该函数可以捕捉高度非线性的网络结构,将输入 M M M映射到低维空间
- 第二个分支是将输入 Z Z Z映射到低维空间,以捕捉属性中的高度非线性。
Highly Non-linear Structure
为了捕捉高度非线性的结构,图1中的每个分支都是一个自动编码器
自动编码器是一种功能强大的无监督深度特征学习模型。
它已被广泛用于各种机器学习应用[酱等人,2016]。基本自动编码器包含三个层
- 输入层
- 隐藏层
- 输出层
其定义如下


人们可以通过最小化重建误差来学习模型参数:

为了捕捉拓扑结构和属性中的高度非线性,图1中的两个分支在编码器中使用了 K K K层,如下所示:

相应地,在解码器中将有 K K K个层。
对于我们的方法
- 第一个分支的输入是高阶邻近矩阵 M M M,以捕捉拓扑结构中的非线性。
- 第二个分支的输入是属性矩阵 Z Z Z,以捕捉属性中的非线性
这里,我们将从拓扑结构和属性中学习的表示分别表示为 H M H^M HM和 H Z H^Z HZ
Proximity Preservation
为了保持语义接近,我们最小化了编码器的输入 Z Z Z和解码器的输出 Z ^ \hat Z Z^之间的重构损失:

具体地说,重建损失可以迫使神经网络平滑地捕获数据流形,从而可以保持样本之间的邻近性[Wang等人,2016]
因此,通过最小化重构损失,我们的方法可以保持属性之间的语义接近
同样,为了保持高阶邻近,我们还将重构损失最小化,如下所示:

具体地说,高阶邻近度 M M M表示邻域结构。
如果两个节点具有相似的邻域结构,这意味着 M i ⋅ M_{i·} Mi⋅和 M j ⋅ M_{j·} Mj⋅相似,则通过最小化重构损失而学习的表示 H i ⋅ m H^m_{i·} Hi⋅m和 H j ⋅ m H^m_{j·} Hj⋅m也将彼此相似
如前所述,我们需要保持捕获局部结构的一阶邻近性
回想一下定义1,如果两个节点之间存在边,则它们相似。
因此,为了保持这种接近,我们最大限度地进行以下似然估计:

其中, p i j p_{ij} pij是第 i i i个节点和第 j j j个节点之间的联合概率
需要注意的是,我们应该同时保持拓扑结构和属性的一阶邻近性,这样才能得到这两种信息之间的一致结果。
对于拓扑结构,联合概率定义如下:

同样,基于属性的联合概率定义如下:

因此,通过如下最小化负对数似然率,我们可以同时保持拓扑结构和属性中的一阶邻近性:

Consistent and Complementary Representation
由于拓扑结构和属性是同一网络的双峰信息,因此我们应该确保从它们学习的表示是一致的
另一方面,这两种信息描述了同一节点的不同方面,提供了互补的信息
因此,学习的陈述也应该是互补的
总而言之,如何学习一致和互补的低维表示是非常重要的
一种直接而简单的方法是将这两个表示 H M H^M HM和 H Z H^Z HZ直接连接起来作为嵌入结果
虽然这种方法可以保持两个模式之间的互补信息,但不能保证这两个模式之间的一致性。
另一种广泛使用的方法是强制图1中的两个分支共享相同的最高编码层,即 H M = H Z H^M=H^Z HM=HZ
虽然这种方法可以保证两个模式之间的一致性,但由于两个模式的最高编码层完全相同,因此会丢失来自两个模式的互补信息。
因此,如何将拓扑结构和属性结合起来进行属性网络嵌入是一个具有挑战性的问题。
为了解决这个具有挑战性的问题,我们建议最大限度地进行以下似然估计:

其中, p i j p_{ij} pij是两个模态之间的联合分布,其定义如下:

此外, s i j ∈ { 0 , 1 } s_{ij}\in\{0,1\} sij∈{ 0,1}表示 H i ⋅ m H^m_{i·} Hi⋅m和 H j ⋅ z H^z_{j·} Hj⋅z是否来自同一节点
具体地,如果 i = j , 则 s i j = 1 i=j,则s_{ij}=1 i=j,则sij=1。否则, s i j = 0 s_{ij}=0 sij=0。
此外,Eq.(10)相当于将负对数概率最小化,如下所示:

通过最小化等式(12)
- 当 H i ⋅ N H^N_{i·} Hi⋅N和 H j ⋅ Z H^Z_{j·} Hj⋅Z来自同一节点时,我们可以强制它们尽可能一致
- 而当它们来自不同节点时,我们可以将它们推开。另一方面,它们并不完全相同,因此它们可以保留每种通道中的互补信息。
然而,公式(十二)右侧的第二项过于严格
例如,如果根据一阶邻近度,两个节点 i i i和 j j j相似,则表示 H i ⋅ N H^N_{i·} Hi⋅N和 H j ⋅ Z H^Z_{j·} Hj⋅Z也应该相似,尽管它们来自不同的节点
这就是说,我们不应该把他们赶走。
因此,我们松弛等式(12)如下:

这里
- 当 H i ⋅ N H^N_{i·} Hi⋅N和 H j ⋅ Z H^Z_{j·} Hj⋅Z来自同一节点时,我们将它们推到一起
- 而当两个节点没有连接时,我们将它们推开
因此,为了保持邻近性并学习一致和互补的表示,我们联合优化了以下目标函数:
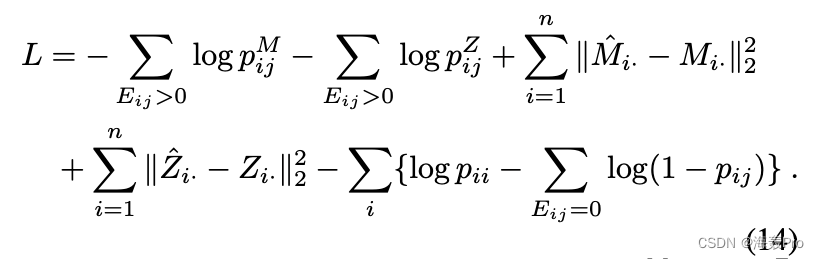
简单记忆:
L = L f + L s + L h + L c L = L_f + L_s + L_h + L_c L=Lf+Ls+Lh+Lc
通过最小化这个问题,我们可以得到 H i ⋅ N H^N_{i·} Hi⋅N和 H j ⋅ Z H^Z_{j·} Hj⋅Z
然后我们将它们连接起来作为节点的最终低维表示,这样我们就可以保留来自拓扑结构和属性的一致和互补的信息。
3.3 Most Negative Sampling Strategy
更详细地看一下等式。(13)针对每个节点解决以下问题:

实际上,邻接矩阵 E E E是非常稀疏的,因为许多边没有被发现。
然而,未发现的边并不意味着两个节点不相似
如果我们推开两个潜在的相似节点,学习到的表示将变得更差
使用梯度下降方法求最优值时
- 如果两个节点 i i i和 j j j潜在地相似,但没有直接链接,则 p i j p_{ij} pij将很大
- 从而 H j ⋅ M H^M_{j·} Hj⋅M将被推离 H i ⋅ Z H^Z_{i·} Hi⋅Z很远。如此一来,嵌入效果就会越来越差
为了缓解这一问题,我们提出了一种最负采样策略来获得稳健的嵌入结果
具体地说,在每次迭代中,我们通过 P = H M ( H Z ) T P=H^M(H^Z)^T P=HM(HZ)T来计算 H M H^M HM和 H Z H^Z HZ之间的相似度。
然后,对于每个节点 i i i,我们按如下方式选择最负的样本:

基于该负样本,建立了目标函数Eq(15)成为

其中 j j j是基于公式(17)进行采样的
采用这种最负抽样策略,尽可能不侵犯潜在的相似节点
因此,嵌入结果将更加稳健。
采样复杂度采样复杂度主要由相似度 P P P的计算决定,其复杂度为 O ( N 2 ) O(N^2) O(N2),而Eq(13)的复杂度为 O ( N 2 ) O(N^2) O(N2)
因此,采用我们的抽样策略不会增加太多成本
因此,我们提出的抽样策略是高效和有效的
4 Experiments
数据集
- Cora
- Citeseer
- PubMed
- Wiki
基线
- DeepWalk
- LINE
- GraRep
- Node2Vec
- TADW
- ANE
- 图形自动编码器(GAE)
- 变化图自动编码器(VGAE)
- SAGE
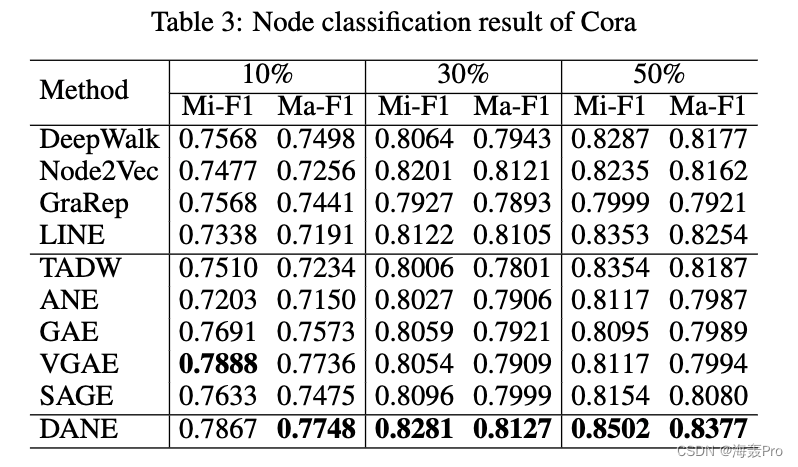
节点分类实验结果



聚类
可视化

读后总结
这篇文章主要的思路还是借助自动编码器(两个)
- 依据原图得到高邻接矩阵 M M M和属性矩阵 Z Z Z
- 然后使用编码器分别对 M M M和 Z Z Z中的向量继续编码,得到 H M H^M HM和 H Z H^Z HZ
- H M H^M HM与 H Z H^Z HZ直接拼接在一起得到最终的节点嵌入
- 这里使用的损失函数由四部分组成 L = L f + L s + L h + L c L = L_f + L_s + L_h + L_c L=Lf+Ls+Lh+Lc
- 其中 L f L_f Lf:依据嵌入向量计算节点之间的一阶邻近
- L s L_s Ls:自动编码器重构 Z Z Z的损失
- L h L_h Lh:自动编码器重构 M M M的损失
- L c L_c Lc:这里有点不太懂,但大概意思是希望顶点相似的更近,顶点若不相似,则远离(有点中心熵的意思了)
- 通过求解 L L L的最优参数训练网络
- 注: M M M是由邻接矩阵 E E E计算得到的(高阶)
嗓子不太舒服,难受
结语
原文链接:https://dl.acm.org/doi/10.5555/3304222.3304235
年度:2018
文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正

边栏推荐
- hudi记录
- Vscode+anaconda+jupyter reports an error: kernel did with exit code
- How do college students make money by programming| My way to make money in College
- Stc89c52/90c516rd/89c516rd ADC0832 ADC driver code
- 如果辨别我现在交易的外盘股指期货交易平台是否正规安全?
- Ubuntu20.04 PostgreSQL 14 installation configuration record
- 51单片机的室内环境监测系统,MQ-2烟雾传感器和DHT11温湿度传感器,原理图,C编程和仿真
- Laravel9 installation locale
- Mysql性能优化(5):主从同步原理与实现
- Use of foreach in QT
猜你喜欢

【十分钟】manim安装 2022

C#【高级篇】 C# 多线程

Redis高并发分布式锁(学习总结)
![[wechat applet] how did the conditional rendering list render work?](/img/db/4e79279272b75759cdc8d6f31950f1.png)
[wechat applet] how did the conditional rendering list render work?

Chapter 2 control structure and function (programming problem)

Simple custom MVC

Realization of BFS in C language by storing adjacency matrix of graph
第2章 控制结构和函数(编程题)

Auto. JS learning notes 16: save to the mobile phone by project, instead of saving a single JS file every time, which is convenient for debugging and packaging

What are outer chain and inner chain?
随机推荐
【笔记】2022.6.7 数据分析概论
如果辨别我现在交易的外盘股指期货交易平台是否正规安全?
Are you a "social bull" or a "social terrorist" in the interview?
QT中foreach的使用
Laravel9 local installation
Tidb 6.0: making Tso more efficient tidb Book rush
【作业】2022.5.23 MySQL入门
JS cross reference
[0x0] 校长留的开放问题作业
Redis高并发分布式锁(学习总结)
Feign pit
数据库的下一个变革方向——云原生数据库
Use common fileUpload to upload files
Usage record of unity input system (instance version)
yarn的安装和使用
Is the largest layoff and salary cut on the internet coming?
4-4 beauty ranking (10 points)
Play with algorithm interview together, nanny level strategy (with high-definition codeless algorithm summary map), recommended collection
利用反射整合ViewBinding和ViewHolder
Number of students from junior college to Senior College (4)