当前位置:网站首页>Faster - RCNN principle and repetition code
Faster - RCNN principle and repetition code
2022-08-04 07:02:00 【hot-blooded chef】
Principle
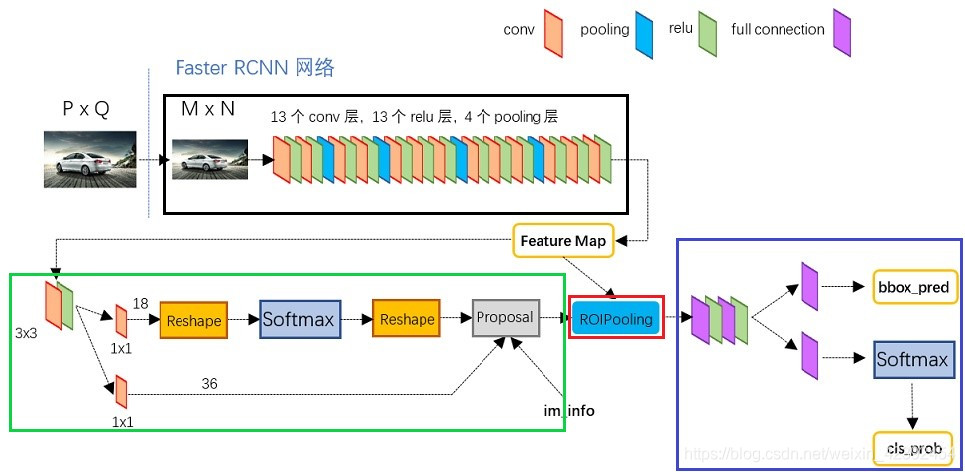
Faster RCNN can be divided into four main parts:
- Conv layers.As a CNN network target detection method, Faster RCNN first uses a set of basic conv+relu+pooling layers to extract image feature maps.The feature maps are shared for subsequent RPN layers and fully connected layers.
- Region Proposal Networks.The RPN network is used to generate region proposal boxes.This layer determines whether the anchors belong to the foreground or background through softmax, and then uses the prediction box regression to correct the anchors to obtain accurate proposal boxes.
- Roi Pooling.This layer collects the input feature maps and proposal boxes, extracts proposal feature maps after synthesizing these information, and sends them to the subsequent fully connected layer to determine the target category.
- Classification.Use proposal feature maps to calculate the proposal category, and at the same time bounding box regression again to obtain the final precise position of the detection frame.
Conv layers
The content of the black box in the figure is Conv layers, which are actually classic networks in traditional image classification, such as VGG and ResNet.In target detection, it is the backbone network for feature extraction. It does not directly participate in the prediction of the box, but outputs the feature layer.Therefore, its last layer does not output the number of categories, but outputs a feature layer with variable width and height.
Region Proposal Networks
The specific structure of the RPN network is shown in the green box above.It can be seen that the RPN network is actually divided into 2 lines. The above one obtains foreground and background classification through softmax classification anchors (the number of channels is 18, which is 2x9, and there are 9 a priori boxes in total. 2 is to use multi-class cross entropy. If twoThe meta cross entropy is 1), the following one is used to calculate the bounding box regression offset for anchors to obtain an accurate proposal (the same is 4x9 here, 4 represents the coordinates of the candidate box on the rpn).The proposal here is the proposal box, and the objects in the proposal box belong to the foreground in the picture.So in this part of the RPN network, the model only separates the foreground and background.
The final proposal layer is responsible for synthesizing the positive anchors and the corresponding bounding box regression offset to obtain proposals, while eliminating proposals that are too small and beyond the boundary.In fact, when the entire network reaches the Proposal Layer, it completes the function equivalent to target positioning.
Roi Pooling
Take the input feature layer as an image, use the image captured by the candidate frame generated by rpn, and then resize it to the size of pool_size * pool_size.After this processing, even if the proposal output results of different sizes are of a fixed size, a fixed-length output is realized.
Classification
After obtaining the fixed-size proposal feature maps from the ROI Pooling layer and sending them to the subsequent network, you can see that the following two things have been done:
- Classify proposals through full connection and softmax, which is actually the category of recognition
- Perform bounding box regression on proposals again to obtain a higher-precision rect box
But in the actual code, the output of the ROI Pooling layer needs to be subjected to conventional convolution, AveragePooling, and Flatten operations before the final object specific classification and prediction box regression operations can be performed.So from the overall point of view, the Faster RCNN network is divided into two steps. The first step is to output the proposal frame of the approximate position of the object from backbone->rpn, and the second step is to classify and position the content in the proposal frame in detail.predict.This is the architecture of the Two-Stage target detection network.
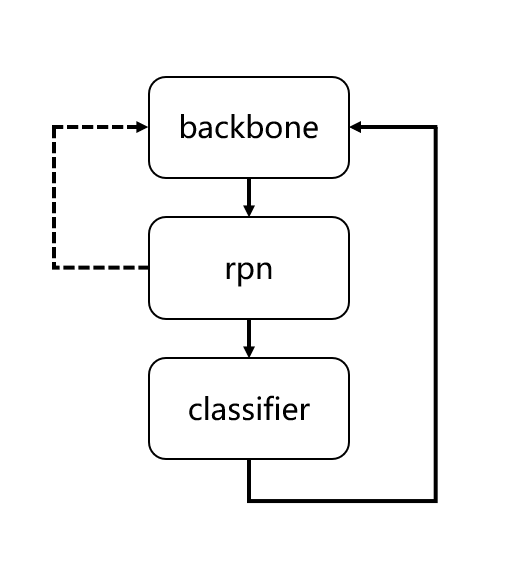
How to train Faster RCNN
The training of Faster RCNN is also divided into two steps
- For backbone-rpn training, the first backpropagation will be performed at this time, and the rpn network will output a prediction result as the data input of the subsequent classifier. If it is not trained well, it will result in no data input for the training of the classifier., so sometimes this step is skipped directly.
- Train the classifier according to the output of the rpn network.
It is worth mentioning that during the training process, the training data may have an imbalance of positive and negative samples, such as the number of backgrounds is much larger than the number of foregrounds or the opposite.Then Faster RCNN will limit the number of positive and negative samples to 128. If there are less than 128 positive samples in the image, the mini-batch data will be filled with negative samples.
Code
Reference
边栏推荐
猜你喜欢

Memory limit should be smaller than already set memoryswap limit, update the memoryswap at the same

数据库技巧:整理SQLServer非常实用的脚本
并发概念基础:并发、同步、阻塞
QT QOpenGLWidget 全屏导致其他控件显示问题

Unity Day02
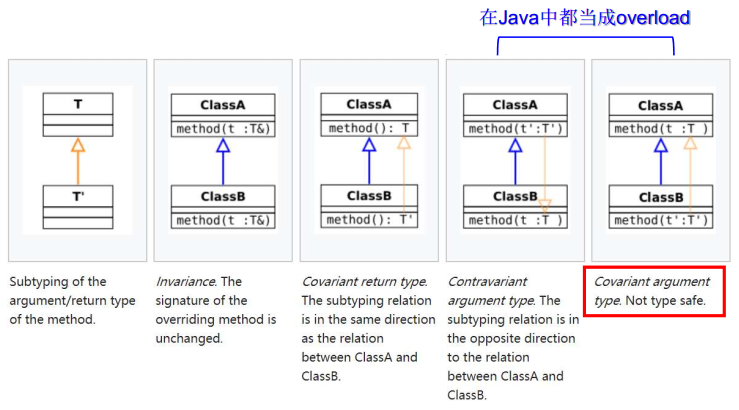
【HIT-SC-MEMO4】哈工大2022软件构造 复习笔记4
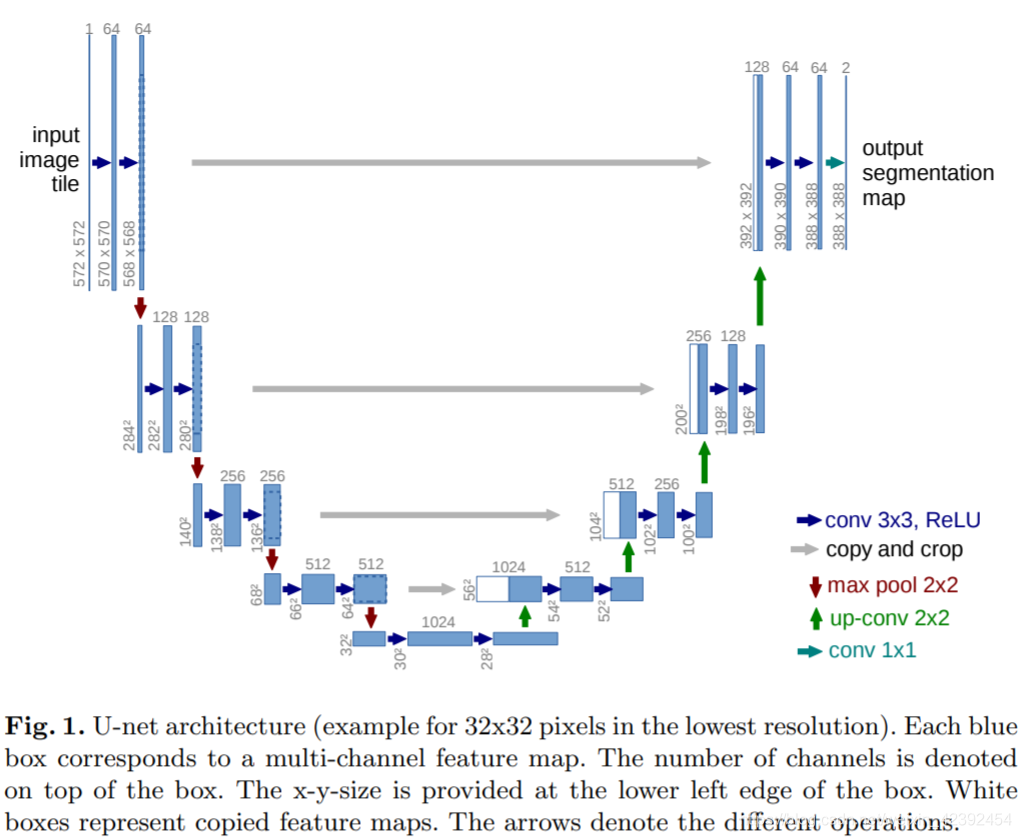
U-Net详解:为什么它适合做医学图像分割?(基于tf-Kersa复现代码)
基于子空间结构保持的迁移学习方法MLSSM
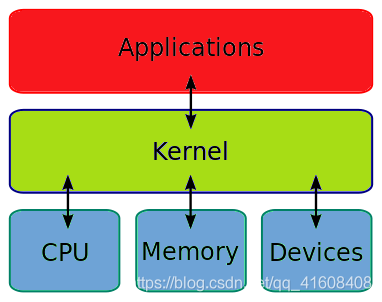
Operating System Kernel
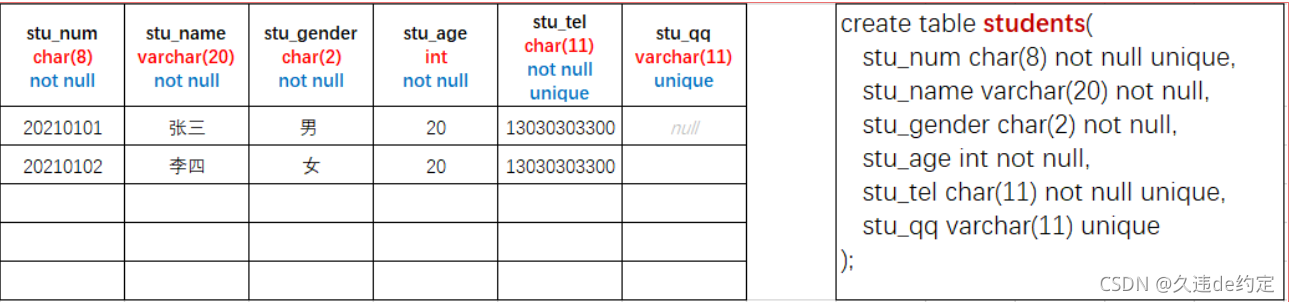
MySQL之SQL结构化查询语言
随机推荐
Uos统信系统 CA根证书搭建
ssm pom文件依赖 web.xml配置
QT 出现多冲定义问题
RHCE之路----全
VS 2017编译 QT no such slot || 找不到*** 问题
【HIT-SC-LAB1】哈工大2022软件构造 实验1
JVM intro
基于子空间结构保持的迁移学习方法MLSSM
数据库技巧:整理SQLServer非常实用的脚本
Uos统信系统 Postfix-smtps & Dovecot-imaps
【HIT-SC-MEMO4】哈工大2022软件构造 复习笔记4
并发概念基础:线程,死锁
Multi-threaded sequential output
基于Webrtc和Janus的多人视频会议系统开发5 - 发布媒体流到Janus服务器
FCN——语义分割的开山鼻祖(基于tf-Kersa复现代码)
POI及EasyExcel
普通用户 远程桌面连接 服务器 Remote Desktop Service
生成一个包含日期的随机编码
Memory limit should be smaller than already set memoryswap limit, update the memoryswap at the same
Scheduler (Long-term,Short-term, Medium-term Scheduler) & Dispatcher