当前位置:网站首页>EFK昇級到ClickHouse的日志存儲實戰
EFK昇級到ClickHouse的日志存儲實戰
2022-06-26 06:09:00 【Impl_Sunny】
0、背景
唯品會日志系統dragonfly 1.0是基於EFK構建,於2014年服務至今已長達7年,支持物理機日志采集,容器日志采集,特殊分類日志綜合采集等,大大方便了全公司日志的存儲和查詢。
隨著公司的業務發展,日志應用場景逐漸遇到了一些瓶頸,主要錶現在應用數量和打印的日志越來越多,開發需要打印更多日志,定比特業務問題,做出運營數據分析;另外外部攻擊問題和審計要求,需要更多安全相關的日志數據要上報並且能够提供半年以上的保存時長,以應對潜在的攻擊和攻擊發生時調查原因和受影響面。ELK的架構的缺點顯現,ES集群規模達260臺機器,需要的硬件和維護成本高達千萬,如果通過擴容的方法去滿足上述業務場景,ES集群會太大會變動不穩定,創建獨立集群,也需要更高成本,兩者都會使得成本和維護工作量劇增。
一、日志系統演進之路
1.1 標准日志格式

規範標准日志格式,有利於正確的識別出日志關鍵元信息,以滿足查詢,告警和聚合計算的需求。從以上格式日志,通過filebeat轉換後的結果如下:
時間戳,日志級別,線程名,類名,eventName,和自定義字段將被日志采集Agent解析後和其他元數據如域名,容器名或主機名一起以JSON格式上報。
自定義字段是開發人員根據業務需要打印到日志,主要支持功能:
①查詢時支持各種聚合分析場景
②根據自定義字段進行聚合函數告警
1.2 ES存儲方案問題
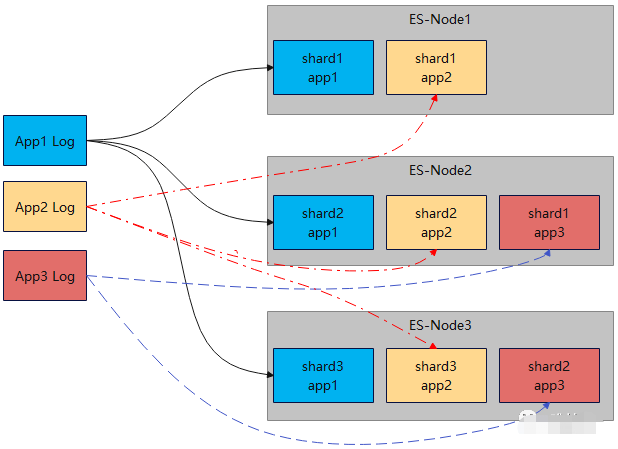
EFK日志存儲在elasticsearch,每個域的日志以天粒度在ES創建一個索引,索引大小是根據前幾日數據大小計算得出,每個索引分片大小不超過30G,日志量越多的域分片越多。如果一個域的日志量寫入過大或超長,將會占用ES節點大量CPU來做解析和segment合並,這會影響其他域日志的正常寫入,導致整體寫入吞吐下降。排查是哪個域的哪個分片日志過大通常較為困難,在面對這種熱點問題時經常要花很長時間。
ES版本使用的是5.5,還不支持索引自動删除和冷熱遷移,有幾個脚本每日定時執行,完成删除索引,關閉索引,移動冷索引,創建新索引的任務,其中移動索引和創建新索引都是耗時非常長的操作。整個生命周期每天循環執行,如果突然一天某個步驟執行失敗,或者執行時間太長,會導致整個生命周期拉長甚至無法完成,第二天的新數據寫入將受到嚴重影響,甚至無法寫入。
另外ES的倒排索引需要對日志進行分詞,產生的索引文件較大,占用了大量磁盤空間。
不過ES也有其優點,基於倒排索引的特性使得ES查詢時,1個分片只需要一個核即可完成查詢,因為查詢速度通常較快,QPS較高。
下面是在大規模(或海量)日志存儲場景下ES的主要存儲優點和缺點:

1.3 日志系統2.0方案
2019年我們嘗試了另外一種HDFS存儲方案,把每個域的數據按照域名+toYYDDMMHH(timestamp)+host作為鍵在客戶端緩存,當大小或過期時間到了之後,提交到HDFS生成一個獨立的文件,存儲路徑包含了域,主機和時間信息,搜索時即可根據這幾個標簽過濾,這種存儲方式有點類似loki,它的缺點顯而易見,優點是吞吐和壓縮率都非常高,可以解决我們吞吐和壓縮率不足的問題。
如果基於此方案繼續增强功能,如添加標簽,簡單的跳數索引,查詢函數,多節點並發查詢,多字段存儲,需要開發的工作量和難度都非常大。我們對比了業界前沿使用的一些存儲方案,最終選擇了clickhouse,他的批量寫入和列式存儲方案完全滿足我們的要求(基於HDFS存儲),另外還提供了占用磁盤空間非常小的主鍵索引和跳數索引,相比ES的全文索引,優勢明顯。
將近26G的應用日志分別使用clickhouse的lz4,zstd和ES的lz4壓縮算法對比

實際生產環境中zstd的日志壓縮比更高,這和應用日志的相似度有關,最大達到15.8。

Clickhouse壓縮率這麼高,但沒有索引,其查詢速度如何?雖然沒有索引,但其向量執行和SIMD配合多核CPU,可以大大緩解沒有全文索引的缺點。經過多次測試對比後,其查詢速度在絕大多數場景下和ES不相上下,在部分場景下甚至比ES還要快。
下圖是實際生產環境的數千個應用真實運行數據,查詢24小時時間範圍內日志和24小時以上時間範圍日志的耗時對比

通過對日志的應用場景分析,我們發現萬億級別的日志,真正能被查詢的日志數量是非常非常少的,這意味著ES對所有日志的分詞索引,大多數是無效的,日志越多,這個分詞消耗的資源越浪費。相對比clickhouse的MergeTree引擎專一的多,主要資源消耗是日志排序壓縮和存儲。
另外Clickhouse的MPP架構使得集群非常穩定,幾乎不要太多運維工作。下面以一幅圖綜合對比ES和Clickhouse的優缺點,說明為什麼我們選擇將clickhouse作為下一代日志存儲數據庫。

二、技術詳解
EFK架構發展這麼多年體系要成熟得多,ES默認參數和倒排索引使得你不需要對ES有太多了解即可輕松使用,開源kibana又提供豐富的查詢界面和圖形面板,對於日志量不大的場景來講,EFK架構仍然是首選。
Clickhouse是近幾年OLAP領域比較熱門的數據庫,其成熟度和生態仍在快速發展中,用來存儲日志的開源方案不是很多,要用好它不但需要對Clickhouse有深入的了解,還需要做很多開發工作。

2.1 日志攝入-vfilebeat
起初dragonfly使用logstash來做日志采集,但logstash的配置較複雜並且無法支持配置文件下發,不便於容器環境下的日志采集,當時另一個使用GO語言開發的采集工具vfilebeat在性能和擴展性方面較好,我們在此基礎上做了定制開發自己的日志采集組件vfilebeat。
vfilebeat運行在宿主機上,啟動時可以通過參數指定采集的宿主機日志所屬的域,如果沒有指定,則讀取安裝時CMDB配置文件的域名和主機名,宿主機采集的每條日志均帶上域名和主機名作為標簽。
容器環境下vfilebeat還會監聽容器的創建和銷毀,當容器創建時,讀取容器的POD信息獲取到域名和主機名,然後從ETCD拉取到域的日志采集路徑等配置參數,按照域名和POD名稱生成容器所屬目錄的日志文件采集路徑,並在本地生成新的配置文件,vfilebeat重新加載配置文件,即可滾動采集。
現在我們環境絕大部分應用均使用vfilebeat采集,少部分場景保留使用logstash采集。vfilebeat將采集到的日志附帶上應用和系統環境等標簽,序列化配置的數據格式,上報到kafka集群,應用日志是JSON,Accesslog為文本行。
2.2 日志解析-flink writer
采集到kafka的日志將被一個flink writer任務實施消費後再寫入到clickhouse集群。

writer把從kafka消費的數據先轉換為結構化數據,vfilebeat上報的時候可能會上報一些日期較久的數據,太久的數據,報上來意義不大,並且會導致產生比較多的小part,消耗clickhosue cpu資源,這一步把這些過期超過三天的日期丟掉,無法解析的數據或者缺少必須字段的日志也會丟掉。經解析過濾後的數據再經過轉換步驟,轉換為clickhouse的錶字段和類型。
轉換操作從schema和metadata錶讀取域日志存儲的元信息,schema定義了clickhouse本地錶和全局錶名,字段信息,以及默認的日志字段和錶字段的映射關系。metadata定義了域日志具體使用的schema信息,日志存儲的時長,域分區字段值,域自定義字段映射到的錶字段,通過這些域級別的配置信息,我們做到可以指定域存儲的錶,存儲的時長,超大日志域獨立分區存儲,降低日志合並的CPU消耗。
自定義字段默認是按照數組存儲,有些域打印的自定義日志字段較多,在日志量大的情况下,速度較慢,配置了自定義映射物理字段存儲,可以提供比數組更快的查詢速度和壓縮率。
clickhouse錶schema信息

域自定義存儲元數據信息

經過轉換後的數據,攜帶了存儲到CK錶所需要的所有信息,將臨時存儲在本地的一個隊列內,本地隊列可能混合存儲了多個域多張錶的日志,達到指定的長度或時間後,再被提交到一個進程級的全局隊列內。
因為writer進程是多線程消費多個kafka分區,全局隊列將同一個錶多個線程的數據合並到一起,使得單次提交的批次更大,全局線程短暫緩沖,當滿足寫入條數,大小或超時後,數據將被作為一次寫入,提交到submit worker線程。submit worker負責數據的寫入,高可用,負載均衡,容錯和重試等邏輯。
submit收到提交的批量數據後,隨機尋找一個可用的clickhosue分片,提交寫入到分片節點。clickhouse集群配置是雙副本,當一個副本節點失敗時,將嘗試切換寫入到另一個節點上,如果兩個都失敗,則暫時剔除分片,重新尋找一個健康的分片寫入。
寫入數據到Clickhouse我們使用的是clickhouse-jdbc,起初寫入時消耗內存和CPU都較大,對jdbc源碼進行分析後,我們發現jdbc寫入數據時,先把所有數據轉換成一個List對象,這個list對象相當於提交數據的byte[]副本格式,為了降低這個占用,在數據轉換步驟我們進行優化,每條日志數據直接轉換為jdbc可以直接使用的List數據,這樣jdbc在構造生成SQL的時候,拿到的數據其實是List的一個引用,這個優化降低了約三分之一內存消耗。
另外對writer進程做火焰圖分析時,我們發現jdbc在生成SQL時,會把提交數據的每個字符進行判定,識別出特殊字符如'\', '\n', '\b'等做轉義,這個轉義操作使用的是map函數,在數據量大時,消耗了約17%的CPU,我們對此做了優化,使用swtich後,內存大幅降低,節約了13%的CPU消耗。
clickhouse的弱集群概念保證了單節點宕機時,整個集群幾乎不受影響,submit高可用保證了當節點异常時,數據仍然可以正常寫入到健康節點,從而使得整個日志寫入非常穩定,幾乎沒有因為節點宕機導致的延遲情况。
關於日志攝入Clickhouse的方式,石墨開源了另一種攝入方式,創建KafkaEngine錶直接消費clickhouse,再將數據導入到物化視圖內,通過物化視圖最終導入到本地錶。這種方式好處是節省了一個writer的組件,上報到kafka的數據直接就可以存儲到clickhouse,但缺點非常多:
每個topic都需要創建獨立的KafkaEngine,如果需要切換錶,增加topic,都要變更DDL,並且無法支持一個topic不同域存儲到不同錶
另外解析kafka數據和物化視圖都要消耗節點CPU資源,而clickhouse合並和查詢都是非常依賴cpu資源的操作,這會加重clickhouse的負載,從而限制了clickhosue整體吞吐,影響了查詢性能,需要擴容更多的節點來緩解此問題,clickhouse的單臺服務器需要更多核數,SSD和大磁盤存儲,因此擴容成本很高。
選擇了將解析寫入組件獨立出來,可解决上面提到的很多問題,也為後期很多擴展功能提供了很大靈活性,好處很多,不再一一列舉。
2.3 存儲-Clickhouse
2.3.1 高吞吐寫入
提交到Clickhouse的數據以二維錶的形式存儲,二維錶我們使用的是Clickhouse最常用的MergeTree引擎,關於MergeTree更詳細的描述可以參考網上這篇文章《MergeTree的存儲結構》。
https://developer.aliyun.com/article/761931spm=a2c6h.12873639.0.0.2ab34011q7pMZK
數據在磁盤的邏輯存儲示意圖

MergeTree采用類似LSM-Tree數據結構存儲,每次提交的批量數據,按照錶的分區鍵,分別保存到不同的part目錄內,一個part內的行數據按照排序鍵進行排序後,再按列壓縮存儲到不同的文件內,Clickhouse後臺任務會持續對這些每個小型的part進行合並,生成更大的part。
MergeTree雖然沒有ES的倒排索引,但有更輕量級的分區鍵,主鍵索引和跳數索引。
分區鍵可以確保查找的時候快速過濾掉很多part,例如按照時間搜索時,只命中時間範圍的part。
主鍵索引和關系型數據庫的主鍵不同,是用來對排序數據塊進行快速查找的輕量級索引。
跳數索引則根據索引類型對字段值進行索引,例如minmax索引指定字段的最大值和最小值,set存儲了字段的唯一值進行索引,tokenbf_v1則對字段進行切分,創建bloomfilter索引,查詢的時候可以直接根據關鍵字計算日志是否在對應數據塊內。
一個part的數據會被按照排序鍵進行排序,然後按照大小切分成一個個較小的塊(index_granularity),塊默認有8192行,同時主鍵索引對每個塊的邊界進行索引,跳數索引則根據索引的字段生成索引文件,通常這三者生成的索引文件都非常小,可緩存在內存中加速查詢。
了解了MergeTree的實現原理,我們可以發現,影響Clickhouse寫入的一個關鍵因素是part的數量,每次寫入都會產生一個part,part越多,那麼後臺合並任務也將越繁忙。除了這個因素外,part的生成和合並均需要消耗CPU和磁盤IO。
所以總結一下,三個影響寫入的因素:
①part數量 - 少
②CPU核數 - 多
③磁盤IO - 高
要提高寫入吞吐,就需要從這三個因素入手,降低part數量,提高CPU核數,提高磁盤IO

將圖中的方法按照實現手段進行分類
- 硬件:CPU核數越多越好,我們生產環境40+,磁盤SSD是標配,由於SSD價格貴容量小,采用SSD+HDD冷熱分離模式
- 錶結構:長日志量又大的域使用bloomfilter索引加速查詢,其他域則使用普通跳數索引即可,我們測試觀察能節約近一半的CPU。
- 數據寫入:Writer提交的數據,按照分區鍵進行分批提交,或者部分分區字段都可,也即單次提交的分區鍵基數盡可能小,最理想為1,此方法可大大降低小part數量。分區鍵的選擇上,可根據應用日志的數量選擇獨立分區鍵,存儲大日志量域,大日志量應用通常會達到條數閾值提交,可使得合並的part都是較大part,效率高;或者混合分區鍵,將小應用混合在一個分區提交。
2.3.2 高速查詢
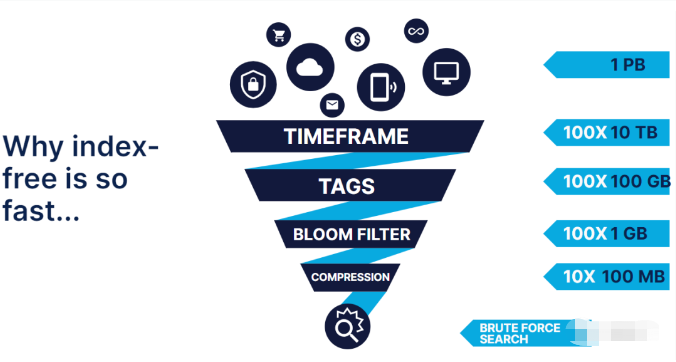
1PB的數據存儲,沒有了全文索引的情况,直接暴力檢索一個關鍵字,肯定是超時的,如果先經過時間,標簽以及bloomfilter進行過濾篩選後,再執行暴力搜索,則需要檢索的數據量會小的多。
MergeTree引擎是列式存儲,壓縮率很高,高壓縮率有很多優勢,從磁盤讀取的數據量少,頁面緩存需要的內存少,更多的文件可以緩存在高速內存中,Clickhouse有和Humio一樣的向量化執行和SIMD,在查詢時,這些內存中的壓縮數據塊會被CPU批量的執行SIMD指令,由於塊足够小,通常為壓縮前1M,這樣函數向量執行和SIMD計算的數據足够全部放在cpu緩存內,不僅减少了函數調用次數,並且cpu cache的miss率大大降低。查詢速度相比沒有向量執行和SIMD有數倍提昇。

2.4 應用維度日志TTL
起初我們計劃使用錶級別的TTL來管理日志,將不同存儲時長的日志放入不同的錶內,但這樣會導致錶和物化視圖變得非常多,不方便管理,後來使用了一個改進方案,將TTL放在錶分區字段內,開發一個簡單的定時任務,每天掃描删除所有超過TTL日期的part,這樣做到了一張錶支持不同TTL的日志存儲,靈活性非常高,應用可以通過界面很方便查看和調整存儲的時長。
2.5 自定義字段存儲方案
標准格式日志內的自定義字段名稱由業務輸出,基數是不確定的,我們第一版方案是創建數百個字符串,整數和浮點數的擴展字段,由開發自行配置這個自定義映射,後來發現這個方案存在嚴重缺陷:
①開發需要將日志的每一個字段均手動配置到映射上去,隨著日志的變更,這樣的字段越來越多,隨著數量膨脹將難以維護,
②Clickhouse需要創建大量的列來保存這些字段,由於所有應用混合在一起存儲,對於大多數應用,太多列不但浪費,並且降低了存儲速度,占用了大量的文件系統INODE節
後來借鑒了Uber日志存儲的方案,每種數據類型的字段,分別創建兩個數組,一個保存字段名稱,另一個保存字段值,名字和值按順序一一對應,查詢時,使用clickhouse的數組檢索函數來檢索字段,這種用法支持所有的Clickhouse函數計算。
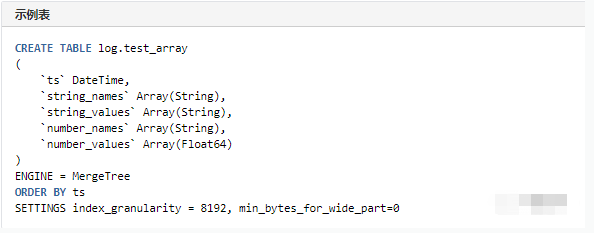
[type]_names和[type]_values分別存儲對應數據類型字段的名稱和值
插入:

多層嵌套的json字段將被打平存儲,例如{"json": {"name": "tom"}}將轉換為 json_name="tom"字段
不再支持數組的存儲,數組字段值將被轉換為字符串存儲,例如:{"json": [{"name": "tom", "age": 18}]},轉換為json="[{\"name\": \"tom\", \"age\": 18}]"
查詢:

原來的映射自定義字段目前仍然保留10個,如果不够,可以隨時添加,可以支持一些域的固定自定義字段,或者一些特殊類型的日志,例如審計日志,系統日志等,這些字段在查詢的時候用戶可以使用原來的名稱,訪問Clickhouse之前會被替換為錶字段名稱
自定義字段的另一個方案是存儲在map內,可以節約兩個字段,查詢也更簡單,但經過我們測試,查詢性能沒有數組好:
①數組存儲壓縮率相比比Map略好
②數組查詢速度比Map快1.7倍以上
③Map的查詢語法比數組簡單,在前端簡化了數組的查詢語法情况下,這個優勢可忽略
三、前端日志查詢系統
日志系統第一版是基於kibana開發的,版本較老。2.0系統我們直接拋弃舊版,自研了一套查詢系統。新版查詢會自動對用戶輸入的查詢語句進行分析,添加上查詢的應用域名和時間範圍等,降低用戶操作難度,支持多租戶隔離。
自定義字段的查詢是非常繁瑣的,我們也做了一個簡化操作:
string_values[indexOf(string_names, 'name')] 簡化為:str.name
number_values[indexOf(number_names, 'height')] 簡化為:num.height
Clickhouse一次執行一條語句,日志查詢時柱狀圖和TOP示例日志是兩條語句,會使得查詢時間範圍翻倍,參考攜程的優化方法,查詢詳情時,我們會根據柱狀圖的結果,將時間範圍縮小至TOP條記錄所在的時間區間。
3.1 豐富查詢用法
Clickhouse豐富的查詢語法,讓我們新日志系統的查詢分析功能非常强大,從海量日志提取關鍵字,非常容易,下面列舉兩個查詢用法:
①從文本和JSON混合的日志數據中提取JSON字段

②從日志計算分比特數

四、正確使用姿勢
1、打印日志不要太長,不超過10K
2、查詢條件帶上有跳數索引的標簽,或者其他非日志詳情的字段,召回日志數越小,查詢速度越快
五、總結
該案例講述了日志系統存儲從簡單的EFK方案昇級到基於Clickhouse存儲和分析的方案,方案非常清晰細節很全,可以作為海量日志昇級方法的參考。
Clickhouse是處理大規模數據密集型場景的利器,非常適合海量日志存儲和查詢分析,構建了一個低成本,無單點,高吞吐,高速查詢的下一代日志系統。
參考資料:
1.微信公眾號(唯技術)-《唯品會基於 Clickhouse 存儲日志的實踐》
边栏推荐
- Spark source code analysis (I): RDD collection data - partition data allocation
- Thread status and stop
- 类和对象的学习
- Gram matrix
- "= =" difference from "equals"
- Library management system
- Handwritten background management framework template (I)
- MySQL database-01 database overview
- numpy. frombuffer()
- How to use the tablet as the second extended screen of the PC
猜你喜欢

A tragedy triggered by "yyyy MM DD" and vigilance before New Year's Day~

MySQL-09

Logstash——Logstash将数据推送至Redis

重载和重写

Household accounting procedures (First Edition)

E-commerce seeks growth breakthrough with the help of small program technology

Cython入门
状态模式,身随心变

Household accounting procedures (the second edition includes a cycle)

去哪儿网BI平台建设演进史
随机推荐
Household accounting procedures (First Edition)
Explore small program audio and video calls and interactive live broadcast from New Oriental live broadcast
【 langage c】 stockage des données d'analyse approfondie en mémoire
Keepalived to achieve high service availability
Basic construction of SSM framework
tf. nn. top_ k()
Bubble sort
Test depends on abstraction and does not depend on concrete
Operator priority, associativity, and whether to control the evaluation order [detailed explanation]
The use of loops in SQL syntax
冒泡排序(Bubble Sort)
小程序第三方微信授权登录的实现
423-二叉树(110. 平衡二叉树、257. 二叉树的所有路径、100. 相同的树、404. 左叶子之和)
Machine learning 07: Interpretation of PCA and its sklearn source code
302. 包含全部黑色像素的最小矩形 BFS
Sql语法中循环的使用
MySQL-07
怎么把平板作为电脑的第二扩展屏幕
MySQL-06
Ribbon load balancing service call