当前位置:网站首页>Feel the power of shardingsphere JDBC through the demo
Feel the power of shardingsphere JDBC through the demo
2022-06-13 05:46:00 【Coffee is not bitter**】
ShardingSphere Contains three important products ,
- ShardingJDBC
ShardingJDBC Just a toolkit for the client , It can be understood as a special JDBC Drive pack , All sub database and sub table logic is controlled by the business party , So its function is relatively flexible , There are also many supported databases , But it's a big intrusion into the business , The business party needs to customize all the sub database and sub table logic . - ShardingProxy
ShardingProxy Is an independently deployed service , No invasion of the business party , The business side can use an ordinary MySQL Data interaction like a service , Basically, I can't feel the existence of back-end database and table logic , But it also means that the function will be fixed , There are few databases that can be supported . - ShardingSidecar
sidecar Is aimed at service mesh Locate a sub database and sub table plug-in .
At present, our project is only limited to Sharding-JDBC Complete the corresponding functions .
One 、JDBC The core concept
The core function is data fragmentation and read-write separation , adopt ShardingJDBC, Applications can be used transparently JDBC Access has been sub database sub table 、 Read write separation of multiple data sources , Instead of caring about the number of data sources and how the data is distributed .
1) The core concept
- Logic table : The same logical and data structure table of a horizontally split database
- True table : Physical tables that actually exist in a fragmented database .
- Data nodes : The smallest unit of data fragmentation . Consists of data source name and data table
- Binding table : Main table and sub table with consistent fragmentation rules .
- Broadcast table : Also called public watch , It refers to the table that exists in all the partitioned data sources , The table structure and the data in the table are completely consistent in each database . For example, dictionary table .
- Patch key : Database fields for sharding , It's the database ( surface ) Key fields for horizontal split .SQL If there is no fragment field in , Full routing will be performed , The performance will be very poor .
- Sharding algorithm : The data is segmented by the segmentation algorithm , Supported by =、BETWEEN and IN Fragmentation . The sharding algorithm needs to be implemented by the application developer , The flexibility that can be achieved is very high .
- Fragmentation strategy : What is really used for slicing operation is the slicing key + Sharding algorithm , That is, fragmentation strategy . stay ShardingJDBC Based on Groovy Of expression inline Fragmentation strategy , The fragmentation strategy is formulated through an algorithm expression containing fragmentation key , Such as t_user_$->{u_id%8} The logo is based on u_id model 8, Divide into 8 A watch , The name of the table is t_user_0 To t_user_7.
2) Understanding the core concepts
3) How to divide databases and tables in a project ?
Two 、demo test
1) Test environment construction
spring+mybatisplus+druid Framework implementations , adopt SpringBootTest test .
There are two problems in the process of building :
When writing configuration files , Automatic prompt function , It's really convenient , Self checking configuration

spring-boot-starter-test When it comes to testing , The test package path cannot be wrong , Otherwise, we can't get , Will report a mistake .

2) test demo- The initial release , Some configurations before splitting databases and tables
1、 pom file
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- Test package -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<!--shardingsphere package -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.23</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
2、application.properties Yes sharding Some basic configuration of
spring.shardingsphere.datasource.names=m1
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://127.0.0.1:3306/employees?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
3、 normal SpringBoot frame , The startup class needs to be configured @MapperScan Scanning package
@SpringBootApplication
@MapperScan("com.huohuo.sharding.mapper")
public class Application {
public static void main(String[] args) {
ApplicationContext context = SpringApplication.run(Application.class, args);
}
}
4、 Database table corresponding to mapper file ,mybatisplus comparison mybatis A lot of convenient , Directly by inheritance BaseMapper<> The mapping is done
The following is what I used for the test CourseMapper as well as Model
public interface CourseMapper extends BaseMapper<Course> {
}
public class Course {
private Integer id;
private String name;
private String type;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
@Override
public String toString() {
return "Course{" +
"id=" + id +
", name='" + name + '\'' +
", type='" + type + '\'' +
'}';
}
}
5、 Test class , The required annotations are indispensable
@SpringBootTest
@RunWith(SpringRunner.class)
public class ShardingTest {
@Resource
CourseMapper courseMapper;
@Test
public void addCourse() {
for (int i = 1; i <= 10; i++) {
Course c = new Course();
c.setId(i);
c.setName("shardingsphere");
c.setType(String.valueOf(i));
courseMapper.insert(c);
}
}
}
Then execute the result , See that the data is entered successfully .

3) test demo- table
Mainly to increase sharding-JDBC Some parameters of the configuration :
spring.shardingsphere.datasource.names=m1
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://127.0.0.1:3306/employees?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
#actual-data-nodes course The logical table corresponds to the real table distribution m1.course_1 m1.course_2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m1.course_$->{
1..2}
# Primary key generation policy Yes id Do the following generation , Snowflake algorithm is adopted SNOWFLAKE; Yes worker.id Don't configuration , Have default values
spring.shardingsphere.sharding.tables.course.key-generator.column=id
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
#spring.shardingsphere.sharding.tables.course.key-generator.props.worker.id=1
# Configure sub table strategy such as id( Corresponding to the main table id) yes 2,id%2+1 Will enter course_1 surface
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{
id%2+1}
# Other running properties
spring.shardingsphere.props.sql.show = true
spring.main.allow-bean-definition-overriding=true
When performing data insertion in a split table , We can't add it manually id The way of the , By configuring the primary key generation policy and data table splitting policy in the configuration file . See the following test code and data execution results , According to our course_$->{id%2+1} Table separated , It should be noted that , Tables must be created in advance , Otherwise, the report does not exist .
@Test
public void addCourse() {
for (int i = 1; i <= 10; i++) {
Course c = new Course();
// c.setId(Long.valueOf(i));
c.setName("shardingsphere");
c.setType(String.valueOf(i));
courseMapper.insert(c);
}
}

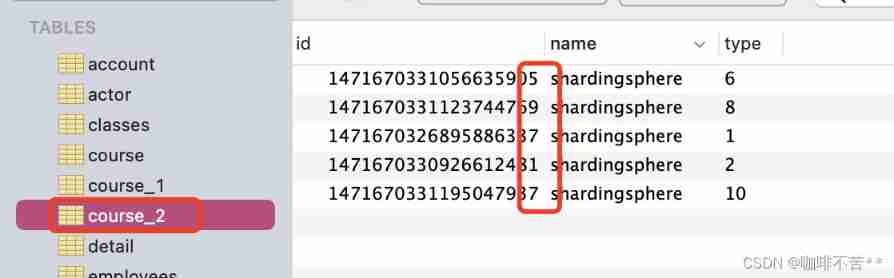
4) test demo- sub-treasury

A new library called m2, Our configured m2 The database is called metting. There are also course_1,course_2.
Follow the configuration above , We can complete the function of dividing databases and tables , But data can only be allocated to m1 Of course_1 and m2 Of course2. give the result as follows :

5) Data query after database and table splitting
Test as above demo, It simply satisfies the concept of "sub database and sub table" , Adopted inline The segmentation algorithm of , This algorithm can realize all data queries or fixed order queries , It does not satisfy the range query . The next part mainly focuses on the partition algorithm .
Test data :
@Test
public void queryOrderRange(){
//select * from course
QueryWrapper<Course> wrapper = new QueryWrapper<>();
wrapper.between("id",1471677043910221826L,1471677048146468866L);
List<Course> courses = courseMapper.selectList(wrapper);
courses.forEach(course -> System.out.println(course));
}

边栏推荐
- 中断处理过程
- Difference between deviation and variance in deep learning
- Implementation of concurrent programming locking
- Celery understands
- Mysql database crud operation
- 16 the usertask of a flowable task includes task assignment, multi person countersignature, and dynamic forms
- Calculate the number of days between two times (supports cross month and cross year)
- Django uses redis to store sessions starting from 0
- MySQL fuzzy query and sorting by matching degree
- Shell instance
猜你喜欢
Information collection for network security (2)

MySQL fuzzy query and sorting by matching degree

Database design
KVM hot migration for KVM virtual management

2 first experience of drools

MySQL transactions and foreign keys

MySQL performs an inner join on query. The query result is incorrect because the associated fields have different field types.

Django uploads local binaries to the database filefield field

2021.9.30学习日志-postman

20 flowable container (event sub process, things, sub process, pool and pool)
随机推荐
MongoDB 多字段聚合Group by
Pychart error resolution: process finished with exit code -1073741819 (0xc0000005)
Shell instance
Summary of the 11th week of sophomore year
MySQL basic query
Jeffery0207 blog navigation
C calls the API and parses the returned JSON string
OpenGL馬賽克(八)
MySQL log management and master-slave replication
Basic application of sentinel series
[China & some provinces and cities] JSON file for offline map visualization
How to Algorithm Evaluation Methods
NVIDIA Jetson Nano/Xavier NX 扩容教程
1 Introduction to drools rule engine (usage scenarios and advantages)
Pychart professional edition's solution to SQL script error reporting
How to set the import / export template to global text format according to the framework = (solve the problem of scientific counting)
August 15, 2021 another week
Etcd fast cluster building
Working principle of sentinel series (concept)
JNDI configuration for tongweb7