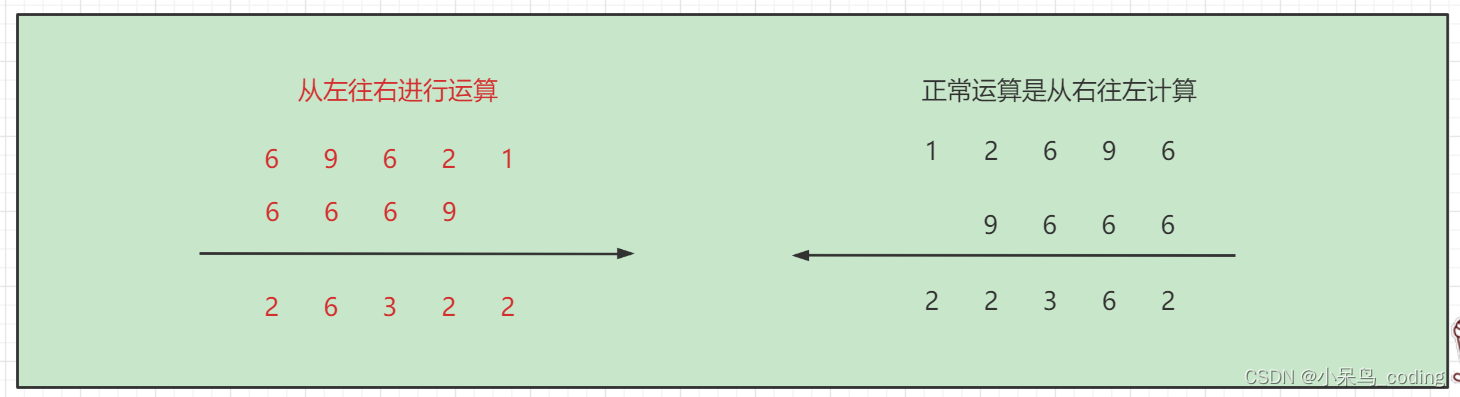
When we usually build tables , It usually looks like the following .
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT COMMENT ' Primary key ',
`name` char(10) NOT NULL DEFAULT '' COMMENT ' name ',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Out of habit , We usually add a column
id A primary key
, The primary key usually has a
AUTO_INCREMENT
, This means that the primary key is self incremented . Self increase is i++, That is, every time you add 1.
But here's the problem .
Primary key id No, no, no ?
Why use self increasing id Do primary key ?
Outrageous , Can I do without a primary key ?
Under what circumstances should it not increase itself ?
Being questioned by such a wave , I can't even think ?
This article , I will try to answer these questions .
The primary key does not automatically add rows
Of course you can . For example, we can build tables sql Inside
AUTO_INCREMENT
Get rid of .
CREATE TABLE `user` (
`id` int NOT NULL COMMENT ' Primary key ',
`name` char(10) NOT NULL DEFAULT '' COMMENT ' name ',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
And then execute
INSERT INTO `user` (`name`) VALUES ('debug');
It's time to report a mistake
Field 'id' doesn't have a default value
. In other words, if you don't let the primary key increase by itself , You need to specify when writing data id What's the value of , Want primary key id Write as much as you want , If you don't write, you will report an error .
Just change it to the following
INSERT INTO `user` (`id`,`name`) VALUES (10, 'debug');
Why use self incrementing primary keys
The data we keep in the database is just like excel The table is the same , Line by line .

user surface
And at the bottom , This row of data , Is to keep them one by one
16k The size of the page
in .
The performance of traversing all rows every time will be poor , So in order to speed up the search , We can
According to primary key id, Arrange the row data from small to large
, Use these data pages
Double linked list
In the form of , Then extract some information from these pages and put them into a new 16kb In the data page of , Then add
The concept of hierarchy
. therefore , Data pages are organized , Became a tree
B + Tree index
.

B + Tree structure
And when we are building tables sql It's stated in
PRIMARY KEY (id)
when ,mysql Of innodb engine , It will be the primary key id Generate a
primary key
, It's through B + Maintain this set of indexes in the form of a tree .
Come here , We have
Two points
It needs attention :
The data page size is
Fix 16k
Due to the data page size
Fixed is 16k
, When we need to insert a new piece of data , Data pages will be slowly
fill up
, When more than 16k when , This data page may be
split
.
in the light of B + Trees
Leaf node
,
If the primary key is self increasing
, Then it produces id Each time is bigger than the previous time , So every time I add the data to B + Trees
The tail
,B + The leaf nodes of a tree are essentially
Double linked list
, Find its head and tail ,
Time complexity O (1)
. And if the last data page is full , Just create a new page .
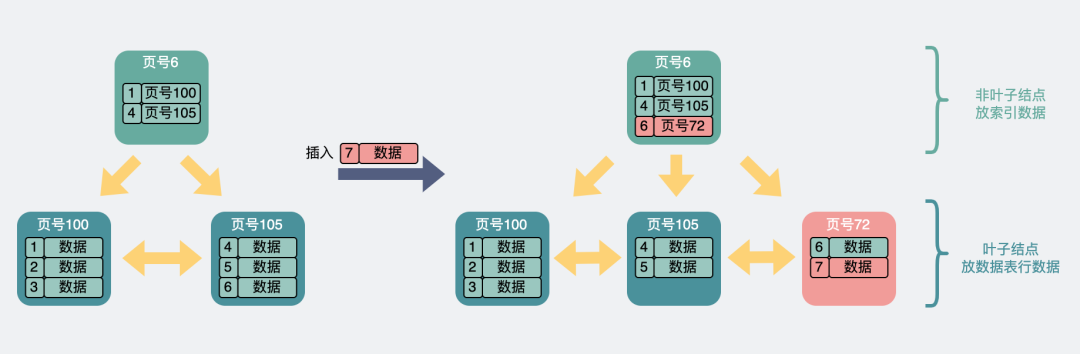
Primary key id Self increasing situation
If the primary key is not self incrementing
, For example, the last time we allocated id=7, This time, we allocated id=3, In order to allow new data to be added
B + The leaf nodes of the tree can also be kept in order
, It needs to go to the middle of the leaf node , Find the
The time complexity is O (lgn)
, If this page happens to be full , It's time to do
Page splitting
了 . And the page splitting operation itself needs to add
Pessimistic locking
Of . On the whole , A self incrementing primary key is less likely to encounter page splitting , Therefore, the performance will be higher .

Primary key id A situation that does not increase by itself
Can I do without a primary key
mysql If the table has no primary key index , You have to scan the whole table to check the data , Since it is so important , I will not be a person today ,
Do not declare primary key , Is that OK ?
Um. , You can not declare the primary key .
You can really build a watch sql It's written like this .
CREATE TABLE `user` (
`name` char(10) NOT NULL DEFAULT '' COMMENT ' name '
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
It looks like there is no primary key . But in fact ,mysql Of innodb The engine will help you generate a file named
ROW_ID
Column , It is a 6 Hidden column of bytes , You don't usually see it , But actually , It is also self increasing . With this bottom covering mechanism, we can guarantee ,
Data tables must have primary keys and primary key indexes
.
Follow ROW_ID The hidden columns are
trx_id
Field , The data line used to record the current line is
Which transaction
Modified , And a
roll_pointer
Field , This field is used to point to the previous version of the current data row , Through this field , A version chain can be formed for this row of data , So as to achieve
Multi version concurrency control (MVCC)
. Do you look familiar , This has appeared in previous articles .

Hidden row_id Column
Is there a scenario where the primary key is not self incremented
As mentioned earlier, primary key auto increment can bring many benefits , in fact
In most scenes , We all suggest that the primary key be set to auto increment .
Is there a scenario where the primary key auto increment is not recommended ?
mysql Under sub database and sub table id
Talk about sub database and sub table , Then I need to explain ,
The difference between increasing and self increasing
了 ,
Self increasing
Every time + 1, and
Increasing
Is new id Compared to the previous one id Just be big , How big is it , No problem .
I wrote an article about ,mysql When dividing the horizontal database and tables , There are generally two ways .
One way to split tables is through
Yes id Take the mold and divide the table
, This kind of requirement increases by degrees , It is not required to strictly self increase , Because the data will be scattered into multiple sub tables after the module is taken , Even if the id It is strictly self increasing , After dispersion , Can only ensure that each sub table id It can only be incremental .

according to id Die taking table
Another way to split tables is
according to id The scope of ( Fragmentation )
, It will draw a certain range , For example 2kw Is the size of a sub table , that 0~2kw In this sub table ,2kw~4kw Put it in another sub table , The data is growing , Sub tables can also be increased ,
It is very suitable for dynamic capacity expansion
, But it requires
id Self increasing
, If
id Increasing
, The data will appear
A lot of holes
. for instance , For example, the first allocation id=2, Second distribution id=2kw, At this time, the range of the first table is filled , Assign another one later id, For example 3kw, It can only be saved to 2kw~4kw( The second ) In the sub table of . Then I am 0~2kw The sub table of this range , It will be saved
Two pieces of data
, It's too wasteful .

according to id Range sub table
But no matter what kind of tabulation , It's usually
It is impossible to continue using the self incrementing primary key in the original table
, The reason is easy to understand , If the original tables are all from 0 If it starts to increase , Then several tables will be repeated several times id, according to id The only principle , This is obviously unreasonable .
So we are in the scenario of dividing databases and tables , Inserted id It's all special id Service generated , If it is strictly self increasing , That usually goes through redis To obtain a , Of course not id Request to get once , Usually
Get by batch , For example, one-time acquisition 100 individual . When it is almost used up, go to get the next batch 100 individual .
But there is a problem with this plan , It relies heavily on redis, If redis Hang up , Then the whole function is stupid .
Is there a method that does not depend on other third-party components ?
Snowflake algorithm
Yes , such as
Twitter Open source snowflake algorithm .
Snowflake algorithm passed 64 A number with a special meaning id.

Snowflake algorithm
First
The first 0 position
no need .
Next
41 position
yes
Time stamp
. The accuracy is
millisecond
, This size can probably represent
69 year
about , Because the timestamp must be getting bigger and bigger as time goes by , So this part determines the generated id It must be bigger and bigger .
And then the next
10 position
The algorithm that generates these snowflakes
Work the machine id
, This allows each machine to produce id All have corresponding identifications .
And then the next
12 position
,
Serial number
, It refers to the incremental number generated in the working machine .
It can be seen that , As long as it is in the same millisecond , All the snowflake algorithms id Before 42 The values of bits are the same , So in this millisecond , What can be produced id The quantity is
2 Of 10 Power ️2 Of 12 Power
, Probably
400w
, It must be enough , Even a little more .
however !
Careful brothers must have found out , The snowflake algorithm always calculates millions more than the last time , That is, it generates id yes
The trend is increasing
Of , Not strictly
+1 Self increasing
Of , That is to say, it is not suitable for the scenario of dividing tables according to ranges . This is a very painful problem .
There's another.
A small problem
yes , that 10 A working machine id, I expand one working machine at a time , How does this machine know its own id How much is? ? Do you have to read it from somewhere .
Is there a generation id Generation scheme , It can support dynamic capacity expansion by database and table , It can be as independent as the snowflake algorithm redis Such third-party services .
Yes . This is the focus of this article .
Suitable for sub database and sub table uuid Algorithm
We can refer to the implementation of snowflake algorithm , It is designed as follows . Pay attention to each of the following ,
It's all decimal
, Not binary .

Suitable for sub database and sub table uuid Algorithm
At the beginning
12 position
Still time , But it's not a timestamp , The time stamp of the snowflake algorithm is accurate to milliseconds , We don't need this detail , Let's change it to
yyMMddHHmmss
, Pay attention to the beginning yy It's two , That is to say, this plan can ensure that 2099 Years ago ,id Will not repeat , Repetition can be used , That's true ・ Centennial enterprise . Also because the first is time , Over time , Also can guarantee id The trend is increasing .
Next
10 position
, use
Decimal system
Of the working machine ip, You can put the 12 Bit ip To 10 Digit number , It can guarantee global uniqueness , As long as the service gets better , I know my own ip How much is it , There is no need to read from other places like the snowflake algorithm worker id 了 , Another small detail .

In the following
6 position
, It is used to generate serial numbers , It can support every second to generate 100w individual id.
final
4 position
, Is this id The best part of the algorithm . it
front 2 position
Represents sub Treasury id,
after 2 position
Represents the sub table id. That is, support a total of
100*100=1w
Split sheet .
for instance , Suppose I only used 1 A sub Treasury , When I started with 3 In the case of a sub table , Then I can configure , Required to be generated uuid The last one 2 position , The value can only be [0,1,2], Corresponding to three tables respectively . So I generated id, It can fall into the three sub tables very evenly , This is also
Incidentally, it solves the problem of writing a single sub table hotspot .
If the business continues to develop , Two new tables need to be added (3 and 4), At the same time 0 The watch is a little full , I don't want to be written anymore , Then change the configuration to [1,2,3,4], Generated in this way id It will not be inserted into the corresponding 0 In the table . At the same time, you can also add generation id Of
Probability and weight
To adjust which sub table has more data .
With this new uuid programme , We
It can ensure that the generated data trend increases , At the same time, it is very convenient to expand the sub table
. very nice.
There are so many databases ,mysql It's just one of them , Do other databases require the primary key to be self incremented ?
tidb Primary key of id Self increase is not recommended
tidb It's a distributed database , As mysql Alternative products in the scenario of sub database and sub table , It can better segment the data .
It's through the introduction of
Range
The concept of data table segmentation , For example, the first partition table id stay 0~2kw, Of the second partition table id stay 2kw~4kw. This is actually
according to id The database is divided into tables
.
Its syntax is almost the same as mysql Agreement , Most of the time it is senseless .
But follow mysql One thing is very different ,mysql Suggest id Self increasing , but
tidb It is suggested to use random uuid
. The reason is that if id Self increasing words , According to the rule of range partition , Generated over a period of time id Almost all of them will fall on the same piece , For example, below , from
3kw
The self increasing of the beginning uuid, Almost all fall to
range 1
In this slice , Other tables have almost no writes , Performance is not being utilized . appear
A watch is difficult , Watch more
The scene of , This situation is also called
Write hot spots
problem .

Write hot issues
So in order to make full use of the writing ability of multiple sub tables ,tidb It is recommended that we use
Random id
, In this way, the data can be evenly distributed into multiple slices .
user id Self augmentation is not recommended id
As mentioned above, autoincrement is not recommended id Scene , It is all caused by technical reasons , And the following one , Simply because of the business .
Let's give you an example .
If you can know a product every month , How many new users , Will this be useful information for you ?
For programmers , Maybe this information is of little value .
But what if you are investing , Or analyze competitors ?
That's the reverse .
If you find your competitors , You can always clearly know how many new registered users your product has each month , Will you be so upset ?
If this problem really occurs , Don't think about whether there is an insider , First check whether the primary key of your user table is self incremented .

If the user id Since the increase , Then others only need to register a new user every month , Then grab the packet to get the user's user_id, Then subtract the value of the previous month , You will know how many new users have entered this month .
There are many similar scenes , Sometimes you go to a small restaurant for dinner , The invoice says which order you are today , Then we can probably estimate how many orders the store has made today . You are the shopkeeper , You're not feeling well either .
For example, some small app Orders for goods id, If we also make it self increasing , It's easy to know how many orders have been made this month .
There are many similar things , For these scenarios, it is recommended to use trend increasing uuid A primary key .
Of course ,
The primary key keeps increasing automatically , But not exposed to the front end , That will do , The previous words , You think I didn't say
.
summary
Build table sql Next to the primary key
AUTO_INCREMENT
, You can increase the primary key automatically , It's OK to get rid of it , But this requires you to insert Set the value of the primary key .
Build table sql Inside
PRIMARY KEY
Is used to declare the primary key , If you remove , That can also build a table successfully , but mysql The interior will secretly build one for you
ROW_ID
As the primary key .
because mysql Use
B + Tree index , Leaf nodes are sorted from small to large
, If you use auto increment id Do primary key , So every time the data is added B + At the end of the tree , Compared with every time you add B + The way in the middle of the tree , Add in the end can be effective
Reduce the problem of page splitting .
In the scenario of sub database and sub table , We can go through redis And other third-party components to obtain strictly self incrementing primary keys id. If you don't want to rely on redis, You can refer to the snowflake algorithm
Magic reform
,
It can ensure that the data trend increases , It can also well meet the dynamic expansion of database and table .
Autoincrement is not recommended for all databases id A primary key , such as
tidb It is recommended to use random id
, This can effectively avoid
Write hot spots
The problem of . And for some sensitive data , Such as user id, Order id etc. , If you use auto increment id As a primary key , External through packet capturing , It's easy to know the number of new users , Order quantity of this information , So we need to
Think carefully
Whether to continue to use the auto increment primary key .
The source code attachment has been packaged and uploaded to Baidu cloud , You can download it yourself ~
link : https://pan.baidu.com/s/14G-bpVthImHD4eosZUNSFA?pwd=yu27
Extraction code : yu27 Baidu cloud link is unstable , It may fail at any time , Let's keep it tight .
If Baidu cloud link fails , Please leave me a message , When I see it, I will update it in time ~
Open source address
Code cloud address :
http://github.crmeb.net/u/defu
Github Address :
http://github.crmeb.net/u/defu
原网站版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/172/202206211734186156.html