当前位置:网站首页>(一)爬取Best Sellers的所有分类信息:爬取流程
(一)爬取Best Sellers的所有分类信息:爬取流程
2022-06-13 11:24:00 【第九棵树】
需要有一点的爬虫基础!!!这是基于实习期间爬取搜索列表商品信息,自己去分析best sellers的爬取过程!!!
再说一遍,没有爬虫基础先去看看别的基础
所需知识点
python的语法
html标签识别(xpath)
正则表达式(re)
真正的请求相关(requests)
解析html为一个etree对象。
本次主要开始分析best sellers的请求流程
网页内容概览
爬取亚马逊的bestseller,站点的url为/gp/bestsellers

将这个页面称为base页面,bestseller的各类别的页面都是从这里点进去的。

目的是爬取bestseller下的所有商品类别的商品。
测试直接爬取
测试base页面的爬取:
import requests
def main():
bestseller_url = '/gp/bestsellers'
res = requests.get(url=bestseller_url)
# <Response [200]>
print(res)
if __name__ == '__main__':
main()
得到的是200,说明没有加任何的请求头信息都可以访问这个页面。
测试各个类别的页面爬取:
拿第一个类别为例:url=/Best-Sellers-Amazon-Devices-Accessories/zgbs/amazon-devices
def other():
bestseller_url = 'Best-Sellers-Amazon-Devices-Accessories/zgbs/amazon-devices'
res = requests.get(url=bestseller_url)
# <Response [503]>
print(res)
503说明是不让访问的。
那么加一下ua试一下:
def other1():
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36',
}
bestseller_url = '/Best-Sellers-Amazon-Devices-Accessories/zgbs/amazon-devices'
res = requests.get(url=bestseller_url, headers=headers)
# <Response [200]>
print(res)
发现加了个头部ua就可以解决了!
**但是这真的解决了吗?**将返回的内容存起来在网页上打开,仔细看类别的网页,发现是一个瀑布流的,前一百分为了两页,每一页只会加载前三十个商品的信息,每页的后面二十条商品信息是还需要再请求的。

到这里的最重要的问题来了,我们怎么解决抓取瀑布流的内容?
解决瀑布流
定位到请求
既然是瀑布流的内容,那么在滚动鼠标的时候肯定发了请求,首先需要定位到哪个请求发了获取后面二十条商品信息。

发现有三个nextPage的请求,这或许就是需要的请求。
点进去一个nextPage的请求,发现携带了请求参数:

可以简单的从indexes中猜到这个nextPage是拿到排名31-38的商品内容,那么就是排名31-50的商品信息分为了三次nextPage请求拿到。
测试一下能否拿到数据
其次应该测试一下这个网页到底返回了什么,或者也可以在"预览"tab中看到,确实是我们要的内容。
那么我们先拿curl测试一下,

复制到powershell中,发现是可以得到200的

分析请求体内容
现在转移到python中使用requests请求:
分析一下请求体ids的信息:
"{\"id\":\"B07G61MF64\",\"metadataMap\":{\"render.zg.rank\":\"31\",\"render.zg.bsms.currentSalesRank\":\"\",\"render.zg.bsms.percentageChange\":\"\",\"render.zg.bsms.twentyFourHourOldSalesRank\":\"\"},\"linkParameters\":{}"
其中B07G61MF64是商品的asin,31是商品的排名,首先这些信息要在请求体里面,那么肯定之前是有的。
这个“之前”是指我们请求bestseller_url = '/Best-Sellers-Amazon-Devices-Accessories/zgbs/amazon-devicess'得到的页面。那么我们可以到这个页面找到是否含有排名31-50商品的asin信息。
我们在整个商品列表的标签前找到了: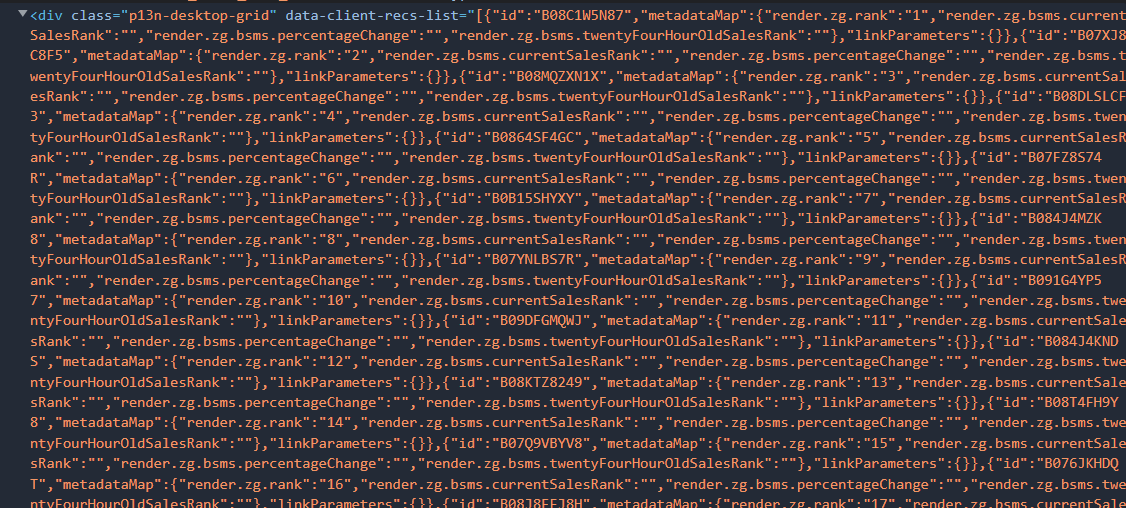
那么就需要先定位到这里,拿到我们后面31-50的asin信息。
# 要拿nextPage的请求体信息,从上面的页面中获取,使用正则匹配
script_list_string = re.match(r"[\s\S]*?data-client-recs-list=\"([\s\S]*?)\" data-index-offset", res.text).group(1)
script_list_string = script_list_string.replace(""", '"').replace(";", "")
# 这里没有过滤掉前面的三十个商品asin信息
script_list = json.loads(script_list_string)
构造请求体内容
indexes_list = []
ids_list = []
for asin_info in script_list:
if 30 <= script_list.index(asin_info) <= 37:
rank = asin_info['metadataMap']['render.zg.rank']
asin = asin_info["id"]
ids_string = "{\"id\":\"%s\",\"metadataMap\":{\"render.zg.rank\":\"%s\",\"render.zg.bsms.currentSalesRank\":\"\",\"render.zg.bsms.percentageChange\":\"\",\"render.zg.bsms.twentyFourHourOldSalesRank\":\"\"},\"linkParameters\":{}}" % (
asin, rank)
ids_list.append(ids_string)
indexes_list.append(int(rank))
print(ids_list)
print(indexes_list)
['{"id":"B07G61MF64","metadataMap":{"render.zg.rank":"31","render.zg.bsms.currentSalesRank":"","render.zg.bsms.percentageChange":"","render.zg.bsms.twentyFourHourOldSalesRank":""},"linkParameters":{}}', '{"id":"B0741WGQ36","metadataMap":{"render.zg.rank":"32","render.zg.bsms.currentSalesRank":"","render.zg.bsms.percentageChange":"","render.zg.bsms.twentyFourHourOldSalesRank":""},"linkParameters":{}}', '{"id":"B07PF1Y28C","metadataMap":{"render.zg.rank":"33","render.zg.bsms.currentSalesRank":"","render.zg.bsms.percentageChange":"","render.zg.bsms.twentyFourHourOldSalesRank":""},"linkParameters":{}}', '{"id":"B08FCWRXQR","metadataMap":{"render.zg.rank":"34","render.zg.bsms.currentSalesRank":"","render.zg.bsms.percentageChange":"","render.zg.bsms.twentyFourHourOldSalesRank":""},"linkParameters":{}}', '{"id":"B07H8WS1FT","metadataMap":{"render.zg.rank":"35","render.zg.bsms.currentSalesRank":"","render.zg.bsms.percentageChange":"","render.zg.bsms.twentyFourHourOldSalesRank":""},"linkParameters":{}}', '{"id":"B07VTK654B","metadataMap":{"render.zg.rank":"36","render.zg.bsms.currentSalesRank":"","render.zg.bsms.percentageChange":"","render.zg.bsms.twentyFourHourOldSalesRank":""},"linkParameters":{}}', '{"id":"B08F6DWKQP","metadataMap":{"render.zg.rank":"37","render.zg.bsms.currentSalesRank":"","render.zg.bsms.percentageChange":"","render.zg.bsms.twentyFourHourOldSalesRank":""},"linkParameters":{}}', '{"id":"B07FKR6KXF","metadataMap":{"render.zg.rank":"38","render.zg.bsms.currentSalesRank":"","render.zg.bsms.percentageChange":"","render.zg.bsms.twentyFourHourOldSalesRank":""},"linkParameters":{}}']
[31, 32, 33, 34, 35, 36, 37, 38]
输出的信息可以跟页面的列表对比一下是否准确,其实这里的indexes_list跟网页上的30-37不一致,发现也是可以拿到准确数据的,应该这里的请求体优先取ids_list字段。
最后可以拼接得到请求体:
# 偏置信息
off_set = str(len(ids_list))
xhr_post_prams = {
"faceoutkataname": "GeneralFaceout",
"ids": ids_list,
"indexes": indexes_list,
"linkparameters": "",
"offset": off_set,
"reftagprefix": "zg_bs_amazon-devices"
}
构造头部信息
整体看一下头部信息的内容有些是重要的,一般来说是cookie等一些字段比较重要,先验证带cookie的头部信息是否可以正常请求,再加其他的头部字段信息。

headers_params = {
'cookie': 'session-id=141-4038987-9284415; session-id-time=2082787201l; i18n-prefs=USD; ubid-main=135-3835860-6573666; lc-main=en_US; sp-cdn="L5Z9:CN"; skin=noskin; session-token="pg7wCihwkADzuQ0YvTFDLENZJixW6hv01quNCOnRAJhJEdtuaCTxbpcmEV2/QT0T6C8ZEuuiqiXNRDzZ/QZ9KhNHGJux/di0TgTiJuADAFAyCd0xhkM1J+a9WB8pWFG4ZgCc3HfkamC1vqm7QA6Ix7SjerpFp1bjCBpLq0B39N50oTh81aspWjvg8ME5jRpEHXNaHATbQn8yiymQewBXdw=="; csm-hit=tb:6BC3XEKYE3RB8WM0V8M0+s-6BC3XEKYE3RB8WM0V8M0|1653742608103&t:1653742608103&adb:adblk_no'
}
next_page_url = '/acp/p13n-zg-list-grid-desktop/qqw1dr01f0cvb9mu/nextPage?'
res = requests.post(url=next_page_url, headers=headers_params, data=json.dumps(xhr_post_prams))
# <Response [400]>
print(res)
发现被400了,说明头部信息还是不完全,发现下面的头部信息:

那么添加这个头部信息:
headers_params = {
'cookie': 'session-id=141-4038987-9284415; session-id-time=2082787201l; i18n-prefs=USD; ubid-main=135-3835860-6573666; lc-main=en_US; sp-cdn="L5Z9:CN"; skin=noskin; session-token="pg7wCihwkADzuQ0YvTFDLENZJixW6hv01quNCOnRAJhJEdtuaCTxbpcmEV2/QT0T6C8ZEuuiqiXNRDzZ/QZ9KhNHGJux/di0TgTiJuADAFAyCd0xhkM1J+a9WB8pWFG4ZgCc3HfkamC1vqm7QA6Ix7SjerpFp1bjCBpLq0B39N50oTh81aspWjvg8ME5jRpEHXNaHATbQn8yiymQewBXdw=="; csm-hit=tb:6BC3XEKYE3RB8WM0V8M0+s-6BC3XEKYE3RB8WM0V8M0|1653742608103&t:1653742608103&adb:adblk_no',
"x-amz-acp-params": "tok=VMyVqM6MJtas2HLq26vuYeJrj0UbGZp7J9pQ1K_xXBw;ts=1653742048886;rid=6BC3XEKYE3RB8WM0V8M0;d1=415;d2=0"
}
next_page_url = '/acp/p13n-zg-list-grid-desktop/qqw1dr01f0cvb9mu/nextPage?'
res = requests.post(url=next_page_url, headers=headers_params, data=json.dumps(xhr_post_prams))
# <Response [200]>
print(res)
其实经过测试,cookie是可以不要的,而且发现x-amz-acp-params含有时间戳。
加了返回200,那么就说明x-amz-acp-params很重要。后面的一系列操作都是为了获取这个x-amz-acp-params的信息。
写在文后
写的不咋地,有需求的凑合看吧。
可以先试试解决一下x-amz-acp-params这个字段的所有信息,其中最重要的是rid这个,后文继续咯。
边栏推荐
- ue5 小知识点 random point in Bounding Boxf From Stream
- 求组合数四种方法
- 【TcaplusDB知识库】Tmonitor系统升级介绍
- [tcapulusdb knowledge base] tcapulusdb cluster management introduction
- Will it be a great opportunity for entrepreneurs for Tiktok to attach so much importance to live broadcast sales of takeout packages?
- 文本纠错--CRASpell模型
- 【TcaplusDB知识库】TcaplusDB常规单据介绍
- break algorithm---dynamic planning(dp-func)
- Environ. Sci. Technol.(IF=9.028) | 城市绿化对大气环境的影响
- 轻量级实时语义分割:ENet & ERFNet
猜你喜欢
![[tcapulusdb knowledge base] tcapulusdb doc acceptance - Introduction to creating game area](/img/b7/2358e8cf1cdaeaba77e52d04cc74d4.png)
[tcapulusdb knowledge base] tcapulusdb doc acceptance - Introduction to creating game area

【TcaplusDB知识库】Tmonitor后台一键安装介绍(二)

What is the appropriate setting for the number of database connections?

我是如何解决码云图床失效问题?

【TcaplusDB知识库】TcaplusDB新增机型介绍

领导说要明天上线,这货压根不知道开发流程

手动加密 ESP 设备量产固件并烧录的流程
![[tcapulusdb knowledge base] Introduction to tmonitor background one click installation (I)](/img/c7/18f3fe9626d2bac32fab7ca0c6463d.png)
[tcapulusdb knowledge base] Introduction to tmonitor background one click installation (I)

文本纠错--CRASpell模型
![[tcapulusdb knowledge base] tcapulusdb doc acceptance - table creation approval introduction](/img/a8/f99765c381bdd84ca3acd18a62dbf7.png)
[tcapulusdb knowledge base] tcapulusdb doc acceptance - table creation approval introduction
随机推荐
Necessary for Architects: system capacity status checklist
Socket programming (Part 1)
fastapi 如何响应文件下载
VSCode 如何将已编辑好的文件中的 tab 键转换成空格键
Vivo large scale kubernetes cluster automation operation and maintenance practice
21世纪以来的历次“粮食危机”,发生了什么?
Similarities and differences between commonAPI and AUTOSAR AP communication management
Multithreading starts from the lockless queue of UE4 (thread safe)
查询当前电脑cpu核心数
Apache apisik v2.14.1 exploratory release to expand into more fields
[tcapulusdb knowledge base] Introduction to tmonitor background one click installation (II)
【TcaplusDB知识库】TcaplusDB单据受理-建表审批介绍
【TcaplusDB知识库】TcaplusDB常规单据介绍
Nim游戏阶梯 Nim游戏和SG函数应用(集合游戏)
[tcapulusdb knowledge base] Introduction to tmonitor stand-alone installation guidelines (II)
(幼升小信息-04)如何用手机WPS在PDF上进行电子签名
TS advanced condition type
Tamidog knowledge | a comprehensive analysis of the meaning and role of mergers and acquisitions of state-owned enterprises
2020 ICPC Asia Taiwan Online Programming Contest C Circles
Will it be a great opportunity for entrepreneurs for Tiktok to attach so much importance to live broadcast sales of takeout packages?