当前位置:网站首页>一种用于实体关系抽取的统一标签空间
一种用于实体关系抽取的统一标签空间
2022-07-26 20:31:00 【JakeSun】

UNIRE: A Unified Label Space for Entity Relation Extraction
UNIRE:一种用于实体关系抽取的统一标签空间
https://github.com/Receiling/UniRE
Abstract
(Zhong and Chen,ACL2020) 使用pipeline方法为实体检测和关系分类设置了两个独立的标签空间,并取得了SOTA。由于pipeline方法不能共享实体抽取和关系抽取的信息,因此作者为了促进两个任务的交互提出了一种可以共享标签空间的方法。作者采用表填充的方法实现,具体来说:输入一张大小的表,这张表包含一个句子中所有的单词对,实体和关系由表格中的正方形和矩形表示(实体:实体内部所有字符都是相同的实体类型标签例如PER;关系:有关系的两个实体的字符都有相同的关系标签),实体都在对角线,关系在非对角线。作者实现了SOTA并且只用了一半的参数,而且速度更快
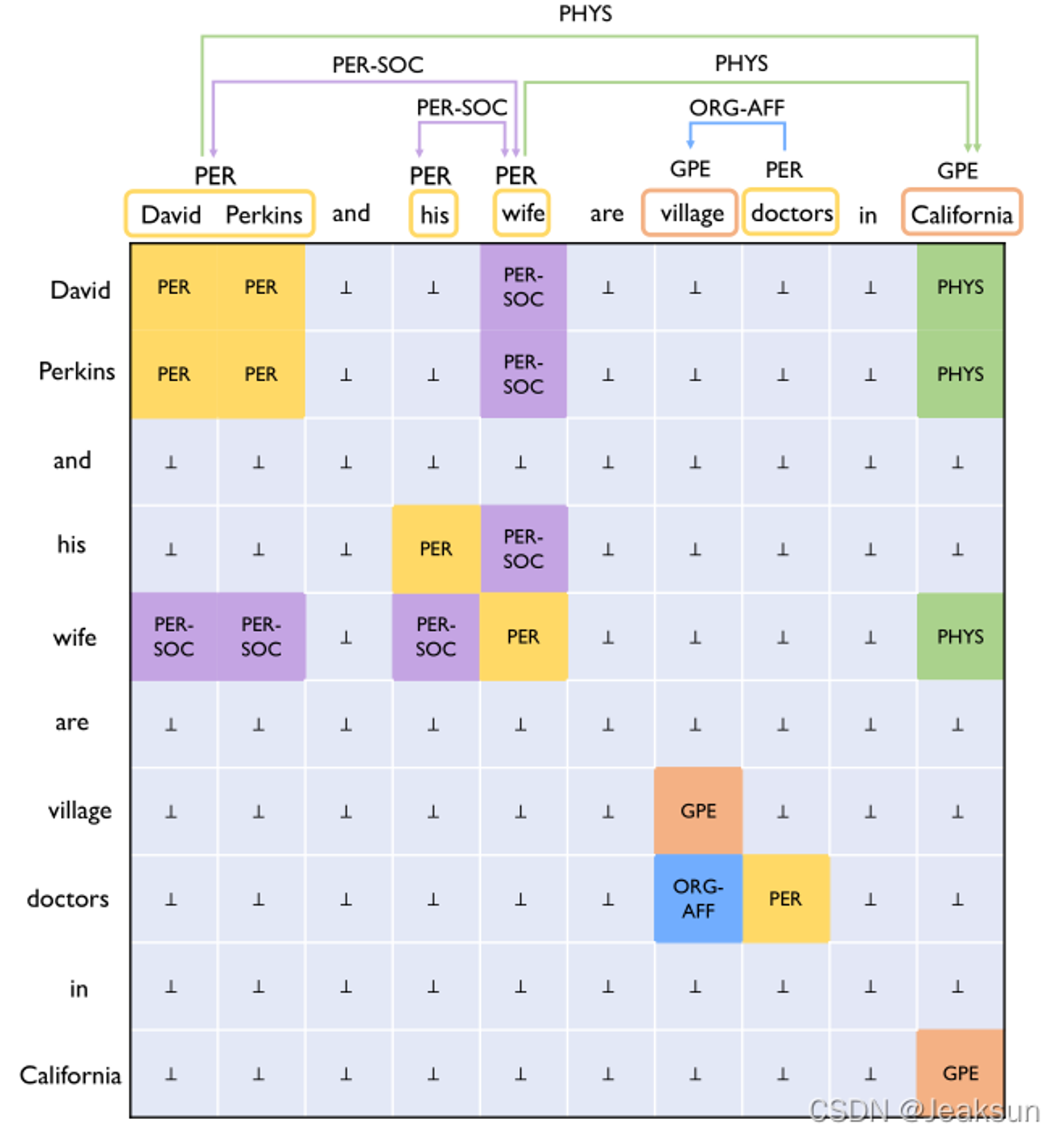
Figure 1:联合实体关系提取表的示例。每个单元格对应一个单词对。实体是对角线上的正方形,关系是对角线外的矩形。请注意,PER-SOC是无向(对称)关系类型,而PHY和ORG-AFF是有向(非对称)关系类型。
该表准确地表示重叠的关系,例如,PER实体“David Perkins”参与两个关系和。对于每个units,一个相同的双仿射模型预测其标签。联合解码器被设置为寻找最佳正方形和矩形
1 Introduction
人们认为联合模型可能会更好,因为它们可以减轻子模型之间的误差传播,具有更紧凑的参数集,并且统一地编码关于两个任务的先验知识。本文将已有的单独的标签空间转化为统一的标签空间,存在的难点:两个子任务通常被表述不同的学习问题(例如:作为序列标签的实体检测,作为多类分类的关系分类),并且它们的标签被放置在不同的事物上(例如,词与词对)。
==先前的一次尝试(郑等人,2017年)是用一个序列标记模型处理这两个子任务。 设计了一个复合标签集来同时对实体和关系进行编码。然而,该模型的表现力被牺牲了:它既**不能检测重叠关系(即,参与多个关系的实体),也不能检测孤立的实体(即,没有出现在任何关系中的实体).==
作者定义一个新的统一标号空间的关键思想:==将实体检测看作关系分类的特例==。输入空间是一个二维表,每个条目对应于句子中的一个词对(图1)。联合模型从统一的标签空间(实体类型集和关系类型集的并集)为每个单元指定标签。在图形上,实体是对角线上的正方形,关系是对角线外的矩形。该公式保留了关于现有提取场景(例如,重叠关系、有向关系、无向关系)的完整模型表达能力。
基于表格形式,联合实体关系提取器执行两个操作:填充和解码。首先,填表是预测每个词对的标签,类似于依存句法分析中的弧形预测任务。采用双仿射注意机制(Dozat和Manning,2016)来学习词对之间的互动。本文还对表施加了两个结构约束。然后,给出带有标签日志的表填充,本文设计了一种近似联合解码算法来输出最终提取的实体和关系。基本上,它高效地在表中找到分割点来识别正方形和矩形(这也与现有的表填充模型不同,现有的表填充模型仍然应用某些顺序解码并递增地填充表)。
在三个基准测试(ACE04,ACE05,SciERC)上的实验结果表明,与目前最先进的提取器(zhong和Chen,2020)相比,该联合方法取得了与之相当的性能:在ACE04和Science ERC上性能更好,在ACE05.1上更具竞争力;同时,我们的新联合模型在解码速度上更快(比确切的流水线实现快10倍,与近似流水线相当,但性能较低)。它还有一个更紧凑的参数集:与单独的编码器相比,共享编码器只使用一半的参数。
2 Approach
2.1 Task Definition
给定一个句子(是word),目的是提取一组实体和一组关系。对于关系三元组,其中是预定义的关系类型,、表示预定义的实体类型和关系类型的集合。
对于句子维护一个表格,其中表示句子长度。对于表中的每个单元格,为其分配一个标签,其中,(表示没有关系)
对于每个实体e:对应的标签 应填写成 对于每个关系 :对应的标签 应填写成 对于其他的单元格填写
本文将解码实体和关系转化为一个矩形查找问题,查找问题采用联合译码方法来解决。
2.2 Biaffine Model
通过BERT获取上下文表示
为了捕获长范围依存关系,将句子扩展成固定的窗口大小(本文设为200),为了更好的编码表中单词的方向信息,采用了深度双仿射注意力机制。
span start和end:
计算每个词span的得分:
其中 , ,2.3 Table Filling
将馈送到Softmax中预测相应标签,从标签空间上产生概率分布:
实验中发现对利用dropout可以进一步提高性能,作者称为
使用交叉熵最小化目标函数:,其中是gold label
2.4 Constraints
目标函数简化了训练过程,实际上还存在一些结构上的约束,实体和关系对应于表中的正方形和矩形,但是目标函数没有显示该约束,本文提出了两个直观的约束,对称和隐含,本文用记号表示句子中所有单词对的堆叠
**Symmetry(对称)**与实体对应的正方形必须在对角线上,对于对称关系如和是等价的,因此在表格上对称关系也是关于对角线对称的(Figure 1所示 and 的矩形关于对角线对称)。
标签集分为对称标签集和非对称标签集
对于矩阵应该关于每个标签的对角线对称,损失为:
Implication蕴含、包含一个关系存在,那么一定存在两个实体,反之就是,没有两个对应的实体,那么一定不可能存在。从概率的角度看,关系的概率大于每个实体的概率。通过蕴含思想,本文对施加如下约束:对于对角线上的每个单词,其在实体类型空间 上的最大可能性不得低于关系类型空间 上同一行或同一列中的其他单词的最大可能性。
蕴含损失表示为: 其中是hinge loss.
总的损失:
2.5 Decoding
在测试阶段,给定句子s的概率张量,从中解码实体的正方形和关系的矩形。受到sun et al 2019的启发,本文提出了一个三步解码算法:1. 解码span(实体或实体间span)。2. 解码每个span的实体类型。3.解码实体对的关系类型。 
span decoding:一个实体包含的词的行列是相同的,如果相邻的两行/列不同,说明在此处一定有实体边界
从行的角度出发将 展平为 ,然后计算行的欧几里得距离 类似的,从列的角度出发根据 ,然后计算列的欧几里得距离 将两个距离的平均值作为最终距离 如果距离大于默认的阈值 ( )则此位置为分割位置(实体边界),span解码的时间复杂度变成了
Entity Type Decoding通过span encoding得出,将得到的生成正方形来解码实体类型,如果则解码为一个实体,如果则不是实体。在表格中是一个正方形,利用取出正方形中所有分数的最大值作为当前span的分数。
Relation Type Decoding在实体类型解码后,给定一个实体和另一个实体,解码一个关系,如果,表示没有关系。
形式上表现为:,,如果,解码为一个关系,如果则没有关系。将得到的span两两匹配,得到实体对之间的关系矩形,将矩形中最大的那个位置对应的关系标签作为最终的关系标签。
3 Experiments
句子长度设置为200,对于MLP层,将隐藏大小设置为d=150,并使用Gelu作为激活函数。我们使用了β1=0.9和β2=0.9的AdamW优化器。批大小为32,学习率为5e-5,权值衰减为1e-5,线性预热学习率调度器,预热率为0.2。用最多200个epochs(对于SciERC为300个纪元)训练模型,并采用提前停止策略。在Intel(R)Xeon(R)W-3175X CPU和NVIDIA Quadro RTX 8000 GPU上进行所有实验。

[ ] 没卡的还是看个乐呵吧 
总的来说,UNIRE在ACE04和SciERC上取得了最好的性能,在ACE05上取得了可比的结果。与之前最好的联合模型(Wang and Lu,2020)相比,该模型在ACE04和ACE05上显著提高了实体和关系的性能,即实体的绝对F1分别为+0.9和+0.7,关系的绝对F1分别为+3.4和+1.7。
对于最好的流水线模型(钟和陈,2020)(当前的SOTA),该模型在ACE04和SciERC上取得了优异的性能,在ACE05上取得了相当的性能。与ACE04/ACE05相比,SciERC的规模要小得多,因此在SciERC上的实体性能大幅下降。由于(钟和陈,2020)是一种流水线方法,其关系绩效受到较差的实体绩效的严重影响。然而,我们的模型在这种情况下受到的影响较小,并且获得了更好的性能。此外,在ACE04上,即使实体结果较差,我们的模型也能获得较好的关系性能。实际上,我们的基础模型(BERTBASE)已经实现了竞争关系绩效,甚至超过了之前基于BERTLARGE(Li et al.,2019)和ALBERTXXLARGE(Wang and Lu,2020)的模型。
3.1 Ablation Study

具体地说,本文实现了一种朴素的比较解码算法,即“硬解码”算法,它以“中间表”作为输入。“中间表”是双仿射模型输出的概率张量P的硬形式,即选择概率最高的类作为每个单元的标签。
为了找到对角线上的实体正方形,它首先尝试判断最大的正方形()是否为实体。标准只是计算出现在正方形中的不同实体标签的数量,并选择出现频率最高的一个。如果最常用的标签是⊥,我们将正方形的大小缩小1,然后在两个正方形上执行相同的工作,依此类推。为避免实体重叠,如果实体与标识的实体重叠,则将丢弃该实体。为了找到关系,每个实体对都用对应矩形中最频繁的关系标签进行标记。
从消融研究中,我们得到了以下观察结果:
移除其中一个额外损失后,性能将随不同程度下降(第2-3行)。具体地说,对称性损失对SCERC有显著影响(实体和关系绩效分别下降1.1分和1.4分)。而去除蕴涵损失会明显损害ACE05(1.0分)的关系绩效。它表明,这两种损失所包含的结构信息对这项任务是有用的。 与“Default”相比,“w/o logit Dropout”和“w/o CrossStatement Context”的性能下降幅度更大(第4-5行)。logit dropout可以防止模型过度拟合, 而跨句上下文为这项任务提供了更多的上下文信息,特别是对于像SciERC这样的小型数据集。 hard decoding的性能最差(其关系性能几乎是“default”的一半)(第6行)。最主要的原因是“硬解码”将实体和关系分开解码。
结果表明,该译码算法综合考虑了实体和关系,对译码具有重要意义
3.2 Error Analysis
我们进一步分析了用于关系提取的其余错误,并给出了五种错误的分布情况:
跨度拆分错误(SSE)、**实体未找到(ENF)、实体类型错误(ETE)、关系未找到(RNF)**、和关系类型错误(RTE) 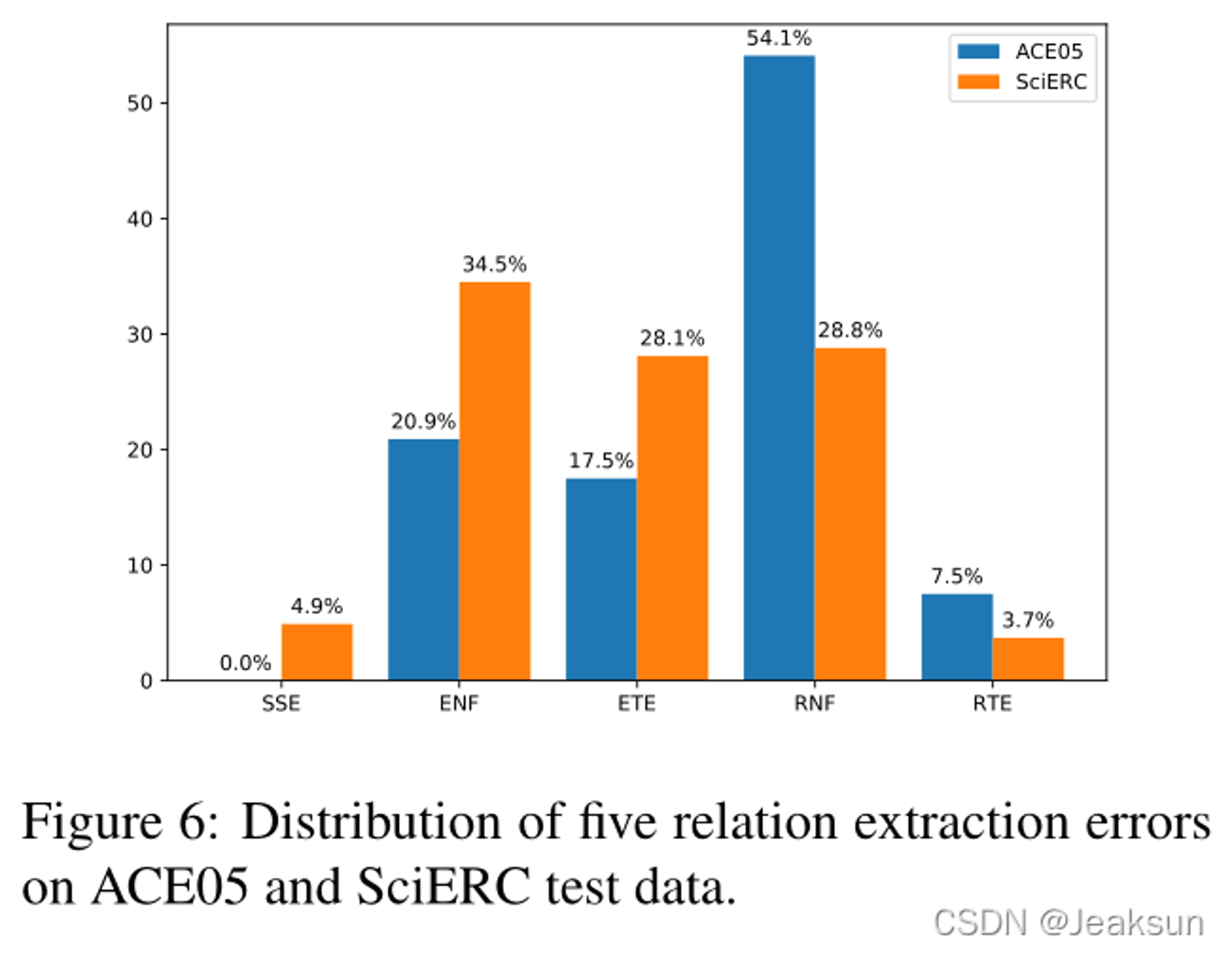
SSE”所占的比例相对较小,这证明了我们的跨度解码方法的有效性。
此外,无论是实体还是关系,“未发现错误”的比例都明显大于“类型错误”的比例。最主要的原因是填表存在类不平衡问题,即⊥的数量远远大于其他类。
边栏推荐
- 没有网络怎么配置传奇SF登陆器自动读取列表
- MySQL -count: the difference between count (1), count (*), and count (column name)
- Sign up now: July 29 recommendation system summit 2022
- 苹果官网罕见打折,iPhone13全系优惠600元;国际象棋机器人弄伤对弈儿童手指;国内Go语言爱好者发起新编程语言|极客头条
- Custom annotation (I)
- Flash source code outline
- Leetcode hash table class
- GOM login configuration free version generate graphic tutorial
- Go+mysql+redis+vue3 simple chat room, the sixth bullet: use vue3 and element plus to call the interface
- Arm TZ hardware support
猜你喜欢
![[Oracle training] - deploy Ogg known as zero downtime migration](/img/bc/4ee0493129d5abab931ca50dbdce6f.png)
[Oracle training] - deploy Ogg known as zero downtime migration
![[HCIA security] user authentication](/img/6f/0ab6287eac36a4647dc2a0646ba969.png)
[HCIA security] user authentication

测试用例千万不能随便,记录由一个测试用例异常引起的思考

立即报名:7 月 29 日推荐系统峰会 2022
![[question] browser get request with token](/img/95/f0b7186f930c014495414c3fcdaa6e.png)
[question] browser get request with token

idea中检索此方法中有哪些参数以便我们使用——1.类图。2.双击shift

Redis hash和string的区别

Flutter Performance Optimization Practice - UI chapter

Deepfake pinches his face. It's hard to tell whether it's true or false. Tom Cruise is more like himself than himself!

TCP的粘包拆包问题解决方案
随机推荐
洛谷-线段覆盖-(区间排序问题总结)
[Oracle training] - deploy Ogg known as zero downtime migration
银河证券场内基金低佣金开户靠谱吗,可靠安全吗
2022-7-26 the seventh group of abstractions and interfaces
功能尝鲜 | 解密 Doris 复杂数据类型 ARRAY
和月薪3W的字节程序员聊过后,才知道自己一直在打杂...
We were tossed all night by a Kong performance bug
Summary of 4 years of software testing experience and interviews with more than 20 companies after job hopping
JVM learning - memory structure - program counter & virtual machine stack & local method stack & heap & method area
详解西部数据SMR叠瓦式硬盘的190二级编译器(译码表)模块
Custom annotation (I)
Sprinboot interview questions
2022 open atom global open source summit agenda express | list of sub forum agenda on July 27
Basic use of livedatade
Leetcode linked list class
Increased uncertainty in BTC and eth due to the approaching interest rate hike? The US economy will face more pain
Flutter性能优化实践 —— UI篇
[OBS] solve the problem of OBS pushing two RTMP streams + timestamp
How to use multiple languages in a project?
Redis hash和string的区别