当前位置:网站首页>(C语言)数据的存储
(C语言)数据的存储
2022-07-03 00:23:00 【epsilon279】
文章目录
release版本的优化功能
release版本会对代码大小和运行速度进行优化

上面这段代码在debug和x86的条件下会出现死循环打印hehe的情况
原因是局部数据是存储在栈区的

但是如果在release的版本下,循环了13次,没有出现死循环

观察数组首元素的地址和i的地址

可以发现在debug版本下i在高地址,数组在低地址。
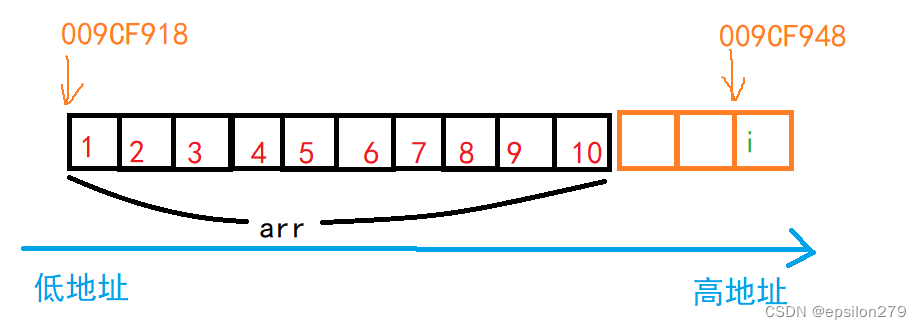
可以发现在release版本下数组在高地址,而i在低地址
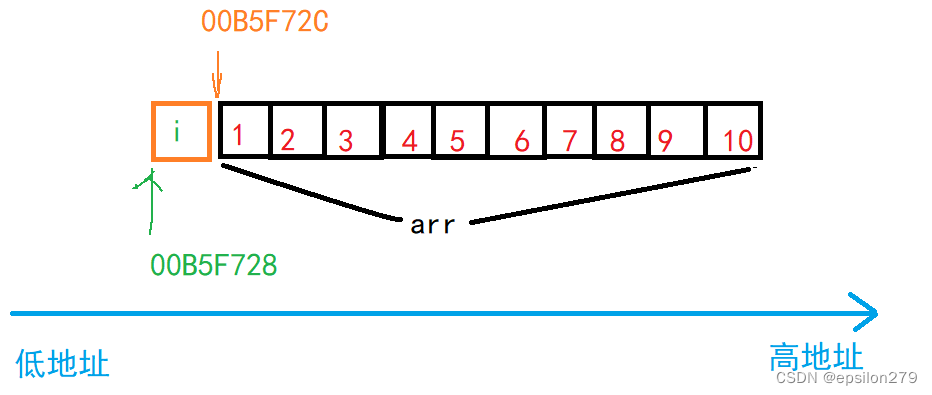
debug版本默认栈区先使用高地址后使用低地址,而release版本对栈区开辟内存方式不同。
1.数据类型介绍
C语言的内置类型
| 类型 | 介绍 | 所占存储空间的大小 (单位:字节) |
|---|---|---|
| char | 字符数据类型 | 1 |
| short | 短整型 | 2 |
| int | 整型 | 4 |
| long | 长整型 | 4/8 |
| long long | 更长的整形 (C99标准引入) | 8 |
| float | 单精度浮点数 | 4 |
| double | 双精度浮点数 | 8 |
注:C语言没有字符串类型。
sizeof(long)>=sizeof(int)
32位平台下long占4个字节,64位平台下占8个字节。
1.1类型的基本归类
整型家族:
char
unsigned char
signed char
short
unsigned short [int]
signed short [int]
int
unsigned int(无符号)
signed int(有符号)
long
unsigned long [int]
signed long [int]
long long
unsigned long long [int]
signed long long[int]
字符的本职是ASCII码值,是整型,所以划分到整型家族。
char有三种类型:
①char
②unsigned char
③signed char
平时写的int等价于signed int(有符号整型).
short,long,long long同理。
char到底是signed char还是unsigned char标准是未定义的,取决于编译器的实现。
符号位是0,表示正数;符号位是1,表示负数。
有符号数二进制序列中第一位表示符号正负,不参与数值运算;
无符号数二进制序列中第一位参与数值运算。
浮点数家族:
float
double
只要是表示小数,就可以使用浮点型。
float的精度低,存储的数值范围较小;double的精度高,存储的数值范围更大。
构造类型(自定义类型):我们可以自己创建出新的类型。
数组类型
结构体类型 struct
枚举类型 enum
联合类型 union
数组类型eg:
int arr1[5];->数组类型是int[5]
int arr2[8];->数组类型是int[8]
char arr3[5];->数组类型是char[5]
指针类型:
int pi;
char pc;
float pf;
void p
空类型
void 表示空类型(无类型)
通常应用于函数的返回类型、函数的参数、指针类型。
2.整型在内存中的存储
2.1原码、反码、补码
//数值有不同的表示形式
//2进制
//8进制
//10进制
//16进制
eg:十进制的21
//0b10101
//025
//21(2*10^1+1*10^0=21)
//0x15
整数的2进制表示也有三种形式
原码:直接通过正负的形式写出的二进制序列
反码:原码的符号位不变,其他位按位取反
补码:反码+1
三种表示方法均有符号位和数值位两部分,
正整数的原码,反码,补码相同
负整数的原码,反码,补码需要通过计算得来
int main()
{
int a=20;
//00000000000000000000000000010100
//二进制序列太长,为了方便起见,我们将4个二进制位写成一个16进制位
//0x00 00 00 14
//00000000000000000000000000010100
//00000000000000000000000000010100
int b=-10;
//10000000000000000000000000001010--原码
//0x80 00 00 0a
//11111111111111111111111111110101--反码
//0xff ff ff f5
//11111111111111111111111111110110--补码
//0xff ff ff f6
return 0;
}


我们可以发现整型在内存中存的是补码的二进制序列(小端存储)
为什么呢?
在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统
一处理;
同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程
是相同的,不需要额外的硬件电路。
eg:1-1相当于1+(-1)
//如果用原码进行计算
//1
//00000000000000000000000000000001
//-1
//10000000000000000000000000000001
----------------------------------
//1+(-1)
//10000000000000000000000000000010
//-2
//err
//但是用补码可以计算
//1
//00000000000000000000000000000001
//-1
//11111111111111111111111111111111
----------------------------------
//1+(-1)
//100000000000000000000000000000000
//得到33位,首位‘1’舍弃,结果为
//00000000000000000000000000000000
//0
原码取反+1可以得到补码
补码取反+1也可以得到原码
//eg:-10
//11111111111111111111111111110110--补码
//10000000000000000000000000001001
//10000000000000000000000000001010--原码
2.2大小端介绍
大端(存储)模式,是指数据的低位字节序保存在内存的高地址中,而数据的高位字节序,保存在内存的低地址
中;
小端(存储)模式,是指数据的低位字节序保存在内存的低地址中,而数据的高位字节序,保存在内存的高地
址中。

VS2019编译器是小端存储。
1个字节以上的类型才有大小端顺序存放的问题。
我们常用的 X86 结构是小端模式,而 KEIL C51 则
为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式
还是小端模式
一道笔试题:请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序。
//eg:
int a=1;
//0x00 00 00 01


2.3练习
1.
//输出什么?
#include <stdio.h>
int main()
{
char a= -1;
signed char b=-1;
unsigned char c=-1;
//unsigned char的范围是0~255,-1不在范围内
//?
printf("a=%d,b=%d,c=%d",a,b,c);
return 0;
}




2.
int main()
{
//char -128~127
char a = -128;
//10000000000000000000000010000000
//11111111111111111111111101111111
//11111111111111111111111110000000 - 截断
//10000000 - a
//11111111111111111111111110000000 - 提升
//无符号数相当于正数,原码反码补码一样
printf("%u\n", a);
printf("%d\n", a);
//11111111111111111111111110000000
//10000000000000000000000001111111
//10000000000000000000000010000000
//-128
//%u 打印无符号整数
return 0;
}

3.
int main()
{
char a = 128;
printf("%u\n", a);
printf("%d\n", a);//-128
return 0;
}

4.
int main()
{
int i = -20;
unsigned int j= 10;
printf("%d\n", i + j);
return 0;
}

5.
unsigned int i;
for(i = 9; i >= 0; i--)
{
printf("%u\n",i);
}
结果是死循环
6.
int main()
{
char a[1000];
int i;
for(i=0; i<1000; i++)
{
a[i] = -1-i;
}
printf("%d",strlen(a));
return 0;
}

结果是255.
7.
#include <stdio.h>
unsigned char i = 0;
int main()
{
for(i = 0;i<=255;i++)
{
printf("hello world\n");
}
return 0;
}
结果是死循环
unsigned char 的范围是0~255,i不可能等于256

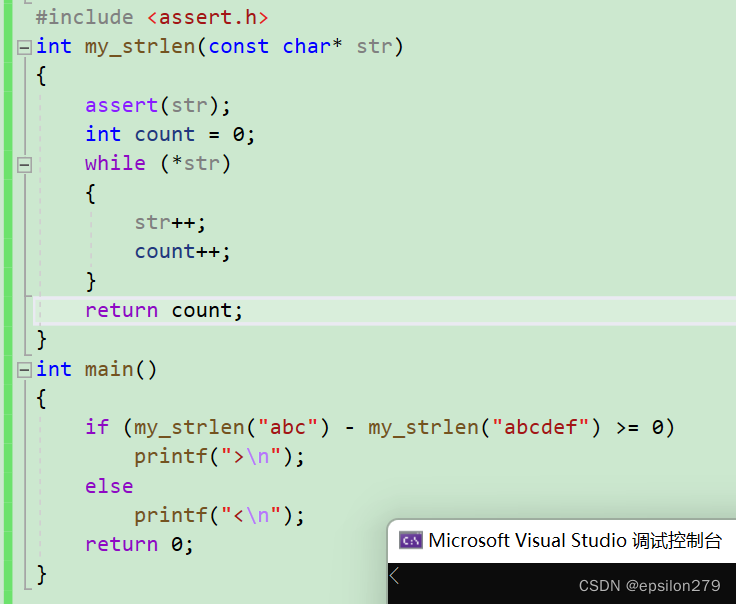
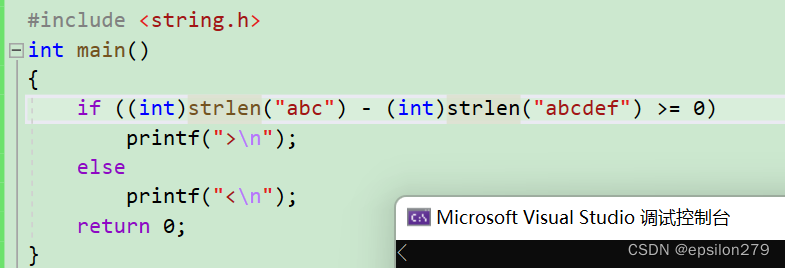
从常理上来讲,strlen是求字符串长度,是求\0之前的所有字符个数。strlen(“abc”)-strlen(“abcdef”)=3-6=-3<0,结果不应该是输出<?
但是结果却输出>
size_t strlen( const char *string );
原来strlen的返回值是size_t
typedef unsigned int size_t;
//无符号整型
//>=0
如果strlen的返回值是int,结果就是<
3.浮点型在内存中的存储
常见的浮点数:
3.14159
1E10
//1.0*10^10
浮点数家族包括: float、double、long double 类型。
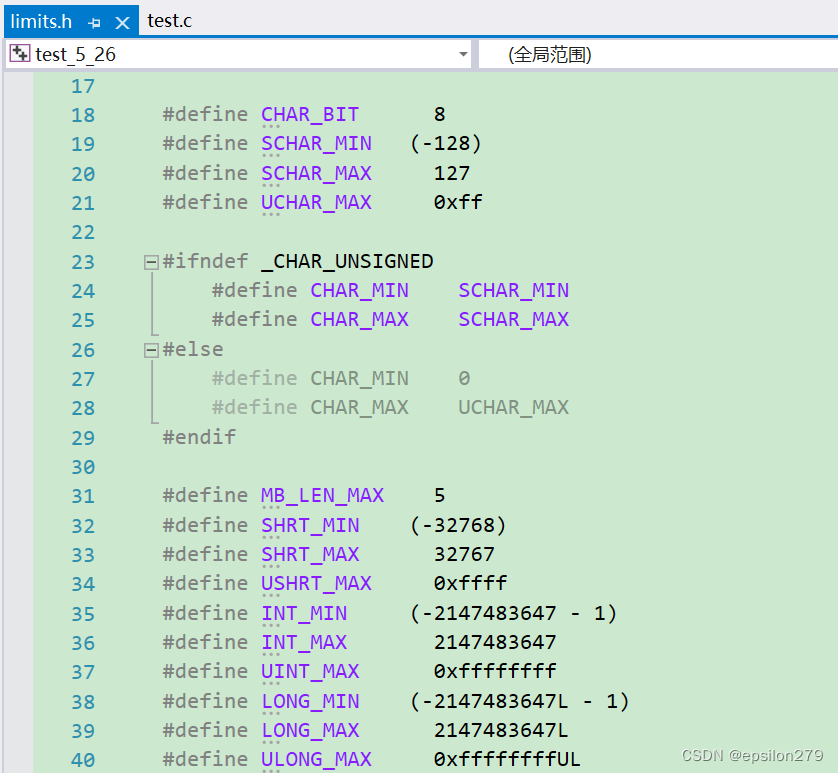
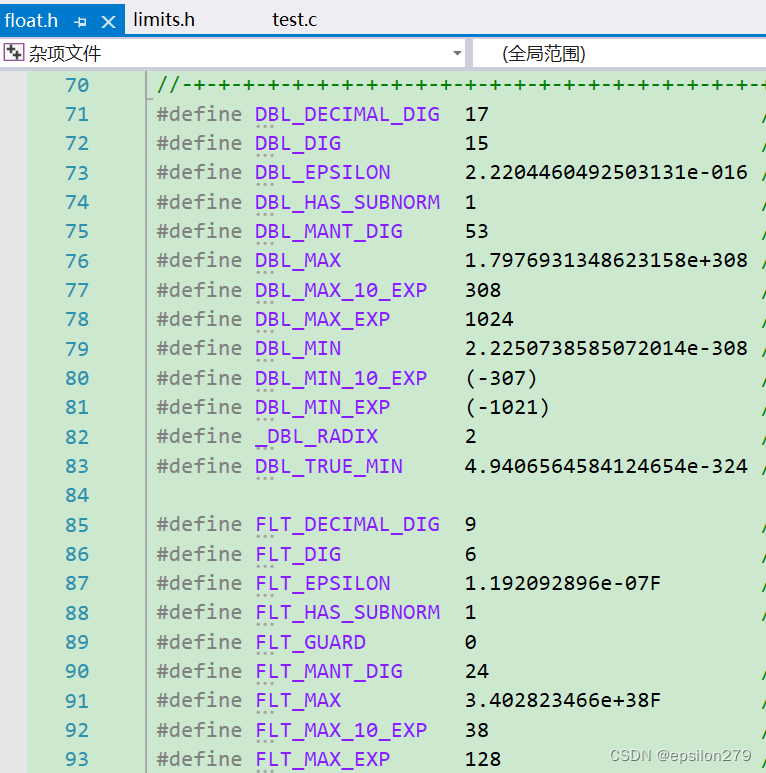
浮点数表示的范围:float.h中定义
char
short
int
long
long long
这些类型的取值范围定义在limits.h
float
double
long double
这些类型的取值范围定义在float.h
3.1 一个例子

我们可以发现:
用整数(浮点数)的形式放进去,用整数(浮点数)的形式拿出来,打印出的结果不变
而用整数的形式放进去,用浮点数的形式拿出来结果变化
用浮点数的形式放进去,用整数的形式拿出来结果变化
3.2 浮点数存储规则
num 和 *pFloat 在内存中明明是同一个数,为什么浮点数和整数的解读结果会差别这么大?
要理解这个结果,一定要搞懂浮点数在计算机内部的表示方法。
详细解读:
根据国际标准IEEE(电气和电子工程协会) 754,任意一个二进制浮点数V可以表示成下面的形式:
(-1)^S * M * 2^E
(-1)^S表示符号位,当S=0,V为正数;当S=1,V为负数。
M表示有效数字,大于等于1,小于2。
2^E表示指数位。
举例来说:
十进制的5.0,写成二进制是 101.0 ,相当于 1.01×2^2 。
那么,按照上面V的格式,可以得出S=0,M=1.01,E=2。
十进制的-5.0,写成二进制是 -101.0 ,相当于 -1.01×2^2 。那么,S=1,M=1.01,E=2。
IEEE 754规定:
对于32位的浮点数,最高的1位是符号位s,接着的8位是指数E,剩下的23位为有效数字M。

对于64位的浮点数,最高的1位是符号位S,接着的11位是指数E,剩下的52位为有效数字M。
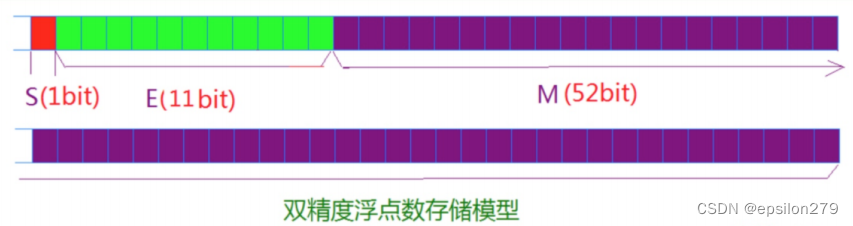
IEEE 754对有效数字M和指数E,还有一些特别规定。
前面说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中xxxxxx表示小数部分。
IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的
xxxxxx部分。比如保存1.01的时
候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。以32位
浮点数为例,留给M只有23位,
将第一位的1舍去以后,等于可以保存24位有效数字。
至于指数E,情况就比较复杂。
首先,E为一个无符号整数(unsigned int)
这意味着,如果E为8位,它的取值范围为0255;如果E为11位,它的取值范围为02047。但是,我们
知道,科学计数法中的E是可以出
现负数的,所以IEEE 754规定,存入内存时E的真实值必须再加上一个中间数,对于8位的E,这个中间数
是127;对于11位的E,这个中间
数是1023。比如,2^10的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即
10001001。
然后,指数E从内存中取出还可以再分成三种情况:
E不全为0或不全为1
这时,浮点数就采用下面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将
有效数字M前加上第一位的1。
比如:
0.5(1/2)的二进制形式为0.1,由于规定正数部分必须为1,即将小数点右移1位,则为
1.0*2^(-1),其阶码为-1+127=126,表示为
01111110,而尾数1.0去掉整数部分为0,补齐0到23位00000000000000000000000,则其二进
制表示形式为:0 01111110 00000000000000000000000
E全为0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值,
有效数字M不再加上第一位的1,而是还原为0.xxxxxx的小数。这样做是为了表示±0,以及接近于
0的很小的数字。
E全为1
这时,如果有效数字M全为0,表示±无穷大(正负取决于符号位s);
解释前面的题目

边栏推荐
- lex && yacc && bison && flex 配置的問題
- An excellent orm in dotnet circle -- FreeSQL
- leetcode-241:为运算表达式设计优先级
- Gan model architecture in mm
- The "2022 China Digital Office Market Research Report" can be downloaded to explain the 176.8 billion yuan market in detail
- Win10 can't be installed in many ways Problems with NET3.5
- Extension of flutter
- [AUTOSAR eight OS]
- 使用jenkins之二Job
- Web2.0 giants have deployed VC, and tiger Dao VC may become a shortcut to Web3
猜你喜欢
Initial order of pointer (basic)

Unity learns from spaceshooter to record the difference between fixedupdate and update in unity for the second time
![[AUTOSAR 11 communication related mechanism]](/img/bf/834b0fad3a3e5bd9c1be04ba150f98.png)
[AUTOSAR 11 communication related mechanism]

In the first half of 2022, there are 10 worth seeing, and each sentence can bring you strength!
指针初阶(基础)
Shell implements basic file operations (cutting, sorting, and de duplication)
![[love crash] neglected details of gibaro](/img/d6/baa4b5185ddaf88f3df71a94a87ee2.jpg)
[love crash] neglected details of gibaro

【AutoSAR 一 概述】
【AutoSAR 十二 模式管理】

【案例分享】让新时代教育发展与“数”俱进
随机推荐
飞凌搭载TI AM62x的ARM核心板/开发板首发上市,亮相Embedded World 2022
Vulkan performance and refinement
指针进阶(一)
深度剖析数据在内存中的存储
The difference between tail -f, tail -f and tail
Leetcode-2280: represents the minimum number of line segments of a line graph
Shell implements basic file operations (SED edit, awk match)
Web2.0 giants have deployed VC, and tiger Dao VC may become a shortcut to Web3
Nacos+openfeign error reporting solution
Set up nacos2 X cluster steps and problems encountered
瑞萨电子RZ/G2L开发板上手评测
Detailed explanation of pod life cycle
如何系统学习机器学习
Gan model architecture in mm
测试右移:线上质量监控 ELK 实战
Vulkan practice first bullet
Shell 实现文件基本操作(sed-编辑、awk-匹配)
【案例分享】让新时代教育发展与“数”俱进
数组与集合性能比较
Arduino开发之按键检测与正弦信号输出