当前位置:网站首页>数据湖(十九):SQL API 读取Kafka数据实时写入Iceberg表
数据湖(十九):SQL API 读取Kafka数据实时写入Iceberg表
2022-07-31 11:31:00 【Lanson】
SQL API 读取Kafka数据实时写入Iceberg表
从Kafka中实时读取数据写入到Iceberg表中,操作步骤如下:
一、首先需要创建对应的Iceberg表
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tblEnv = StreamTableEnvironment.create(env);
env.enableCheckpointing(1000);
//1.创建Catalog
tblEnv.executeSql("CREATE CATALOG hadoop_iceberg WITH (" +
"'type'='iceberg'," +
"'catalog-type'='hadoop'," +
"'warehouse'='hdfs://mycluster/flink_iceberg')");
//2.创建iceberg表 flink_iceberg_tbl
tblEnv.executeSql("create table hadoop_iceberg.iceberg_db.flink_iceberg_tbl3(id int,name string,age int,loc string) partitioned by (loc)");
二、编写代码读取Kafka数据实时写入Iceberg
public class ReadKafkaToIceberg {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tblEnv = StreamTableEnvironment.create(env);
env.enableCheckpointing(1000);
/**
* 1.需要预先创建 Catalog 及Iceberg表
*/
//1.创建Catalog
tblEnv.executeSql("CREATE CATALOG hadoop_iceberg WITH (" +
"'type'='iceberg'," +
"'catalog-type'='hadoop'," +
"'warehouse'='hdfs://mycluster/flink_iceberg')");
//2.创建iceberg表 flink_iceberg_tbl
// tblEnv.executeSql("create table hadoop_iceberg.iceberg_db.flink_iceberg_tbl3(id int,name string,age int,loc string) partitioned by (loc)");
//3.创建 Kafka Connector,连接消费Kafka中数据
tblEnv.executeSql("create table kafka_input_table(" +
" id int," +
" name varchar," +
" age int," +
" loc varchar" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'flink-iceberg-topic'," +
" 'properties.bootstrap.servers'='node1:9092,node2:9092,node3:9092'," +
" 'scan.startup.mode'='latest-offset'," +
" 'properties.group.id' = 'my-group-id'," +
" 'format' = 'csv'" +
")");
//4.配置 table.dynamic-table-options.enabled
Configuration configuration = tblEnv.getConfig().getConfiguration();
// 支持SQL语法中的 OPTIONS 选项
configuration.setBoolean("table.dynamic-table-options.enabled", true);
//5.写入数据到表 flink_iceberg_tbl3
tblEnv.executeSql("insert into hadoop_iceberg.iceberg_db.flink_iceberg_tbl3 select id,name,age,loc from kafka_input_table");
//6.查询表数据
TableResult tableResult = tblEnv.executeSql("select * from hadoop_iceberg.iceberg_db.flink_iceberg_tbl3 /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/");
tableResult.print();
}
}
启动以上代码,向Kafka topic中生产如下数据:
1,zs,18,beijing
2,ls,19,shanghai
3,ww,20,beijing
4,ml,21,shanghai
我们可以看到控制台上有对应实时数据输出,查看对应的Icberg HDFS目录,数据写入成功。
边栏推荐
- redis-enterprise use
- Android studio connects to MySQL and completes simple login and registration functions
- MySQL 的 limit 分页查询及性能问题
- 3D激光SLAM:LeGO-LOAM论文解读---点云分割部分
- 面试、工作中常用sql大全(建议收藏备用)
- IBM SPSS Statistics 28软件安装包下载及安装教程
- 使用内存映射加快PyTorch数据集的读取
- 新人学习小熊派华为iot介绍
- 7 天能找到 Go 工作吗?学学 Go 数组和指针试试
- Initial JDBC programming
猜你喜欢

KVM virtualization job
![AtCoder—E - Σ[k=0..10^100]floor(X/10^k](/img/be/82cfab00950c1f28d426e76a792906.png)
AtCoder—E - Σ[k=0..10^100]floor(X/10^k

Redis-基础
【Web技术】1397- 深入浅出富文本编辑器
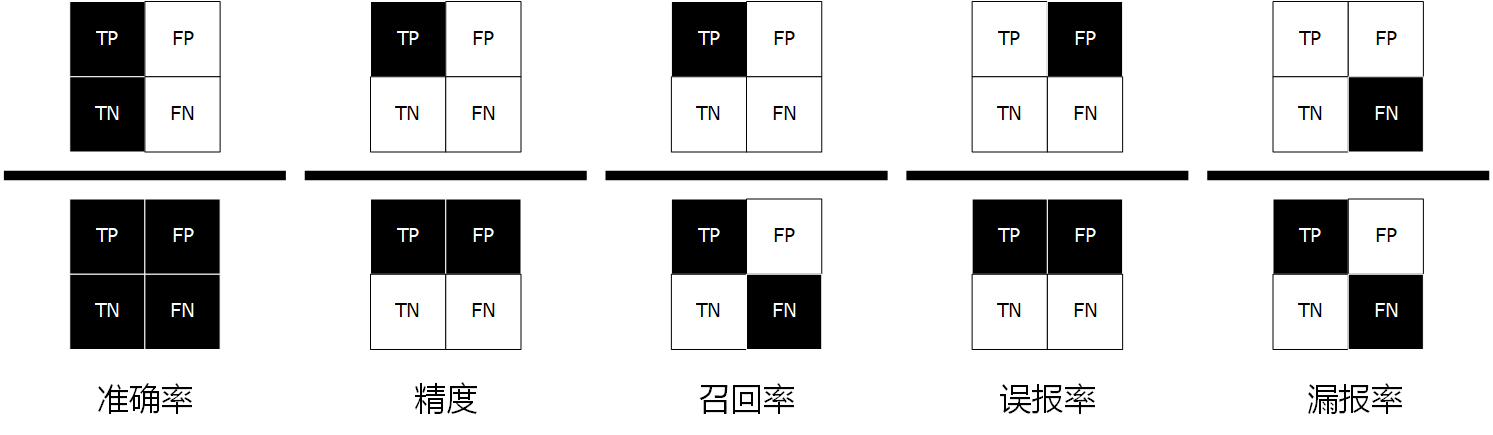
准确率(Accuracy)、精度(Precision)、召回率(Recall)和 mAP 的图解

Distributed Transactions - Introduction to Distributed Transactions, Distributed Transaction Framework Seata (AT Mode, Tcc Mode, Tcc Vs AT), Distributed Transactions - MQ
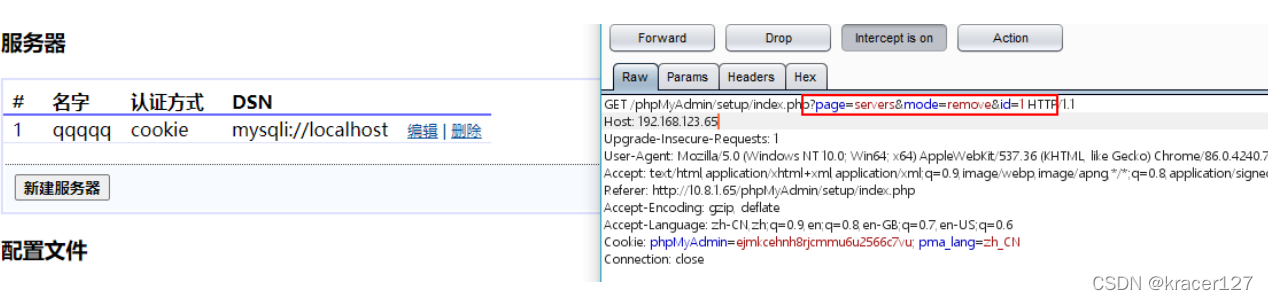
The most complete phpmyadmin vulnerability summary

Experience innovation and iteration through the development of lucky draw mini-programs
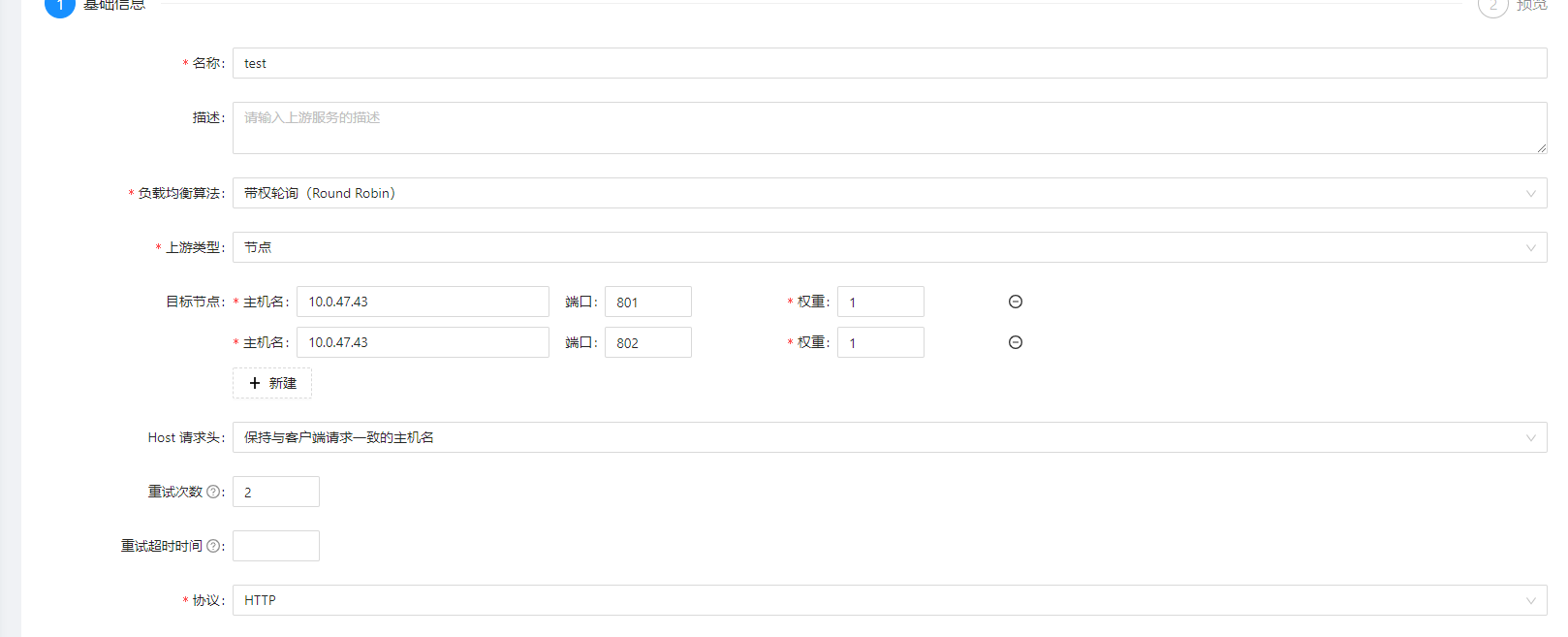
apisix-入门使用篇
《JUC并发编程 - 高级篇》06 - 共享模型之不可变(不可变类的设计 | 不可变类的使用 | 享元模式)
随机推荐
Distributed id solution
IBM SPSS Statistics 28软件安装包下载及安装教程
MySQL百万数据优化总结 一
KVM virtualization job
7 days to learn Go, Go structure + Go range to learn
7 天找个 Go 工作,Gopher 要学的条件语句,循环语句 ,第3篇
应用层基础 —— 认识URL
file contains vulnerabilities
Power BI----几个常用的分析方法和相适应的视觉对象
《云原生的本手、妙手和俗手》——2022全国新高考I卷作文
「R」使用ggpolar绘制生存关联网络图
The item 'node.exe' was not recognized as the name of a cmdlet, function, script file, or runnable program.
SQLServer2019 installation (Windows)
WSL2安装.NET 6
Intranet Penetration Learning (IV) Domain Lateral Movement - SMB and WMI Service Utilization
1161. 最大层内元素和 (二叉树的层序遍历)
面试、工作中常用sql大全(建议收藏备用)
The most complete phpmyadmin vulnerability summary
LeetCode - 025. 链表中的两数相加
台达PLC出现通信错误或通信超时或下载时提示机种不符的解决办法总结