当前位置:网站首页>torch. utils. data. Dataloader() details [pytoch getting started manual]
torch. utils. data. Dataloader() details [pytoch getting started manual]
2022-06-10 15:53:00 【Classmate K】
List of articles
The function prototype
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)
function
Encapsulate the data into... According to the custom format Tensor.
Parameter description
dataset (Dataset)– dataset from which to load the data.
The dataset from which to load data .batch_size (int, optional)– how many samples per batch to load (default: 1).
How many samples should be loaded in each batchshuffle (bool, optional)– set to True to have the data reshuffled at every epoch (default: False).
Set to True So that the data will be reshuffled in each periodsampler (Sampler or Iterable, optional)– defines the strategy to draw samples from the dataset. Can be any Iterable with len implemented. If specified, shuffle must not be specified.
Define a strategy for extracting samples from a datasetbatch_sampler (Sampler or Iterable, optional)– like sampler, but returns a batch of indices at a time. Mutually exclusive with batch_size, shuffle, sampler, and drop_last.
Similar to sampler , But return a batch of indexes at a time . And batch_size,shuffle,sampler and drop_last Mutually exclusive .num_workers (int, optional)– how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process. (default: 0)
How many sub processes are used for data loading . 0 Indicates that data will be loaded in the main process . ( The default value is :0)collate_fn (callable, optional)– merges a list of samples to form a mini-batch of Tensor(s). Used when using batched loading from a map-style dataset.
Merge sample lists to form small batches of tensors .pin_memory (bool, optional)– If True, the data loader will copy Tensors into CUDA pinned memory before returning them. If your data elements are a custom type, or your collate_fn returns a batch that is a custom type.
If True, The data loader copies the tensor to before returning it CUDA Fixed memory . If your data element is a custom type , Or your collate_fn What is returned is a custom type batchdrop_last (bool, optional)– set to True to drop the last incomplete batch, if the dataset size is not divisible by the batch size. If False and the size of dataset is not divisible by the batch size, then the last batch will be smaller. (default: False)
If the dataset size cannot be divided by the batch size , Is set to True To delete the last incomplete batch . If False And the size of the data set cannot be divided by the batch size , The last batch will be smaller .timeout (numeric, optional)– if positive, the timeout value for collecting a batch from workers. Should always be non-negative. (default: 0)
If is positive , Is the timeout value of collecting batches from staff . Should always be non negative . ( The default value is :0)worker_init_fn (callable, optional)– If not None, this will be called on each worker subprocess with the worker id (an int in [0, num_workers - 1]) as input, after seeding and before data loading. (default: None)prefetch_factor (int, optional, keyword-only arg)– Number of samples loaded in advance by each worker. 2 means there will be a total of 2 * num_workers samples prefetched across all workers. (default: 2)
The number of pre loaded samples per sub process . 2 Indicates that a total of... Will be prefetched in all subprocesses 2 * num_workers Samples . ( The default value is :2)persistent_workers (bool, optional)– If True, the data loader will not shutdown the worker processes after a dataset has been consumed once. This allows to maintain the workers Dataset instances alive. (default: False)
If True, After the data set is used once , The data loader will not shut down the worker process . This will enable Worker Dataset Instance remains active . ( The default value is :False)
🦪 Practical cases
- Deep learning 100 example | The first 1 example : Cat and dog recognition - PyTorch Realization
- Deep learning 100 example | The first 2 example : Facial expression recognition - PyTorch Realization
- Deep learning 100 example | The first 3 God : Traffic sign recognition - PyTorch Realization
- Deep learning 100 example | The first 4 example : Fruit recognition - PyTorch Realization
边栏推荐
- Vins theory and code explanation 0 -- theoretical basis in vernacular
- 【第七节 函数的作用】
- 智能电网终极Buff | 广和通模组贯穿“发、输、变、配、用”全环节
- [high code file format API] Shanghai daoning provides you with the file format API set Aspose, which can create, convert and operate more than 100 file formats in just a few lines of code
- 【对象】。
- Comply with medical reform and actively layout -- insight into the development of high-value medical consumables under the background of centralized purchase 2022
- Solution to some problems of shadow knife RPA learning and meeting Excel
- ORB_ Slam2 visual inertial tight coupling positioning technology route and code explanation 1 - IMU flow pattern pre integration
- CAP 6.1 版本发布通告
- QT 基于QScrollArea的界面嵌套移动
猜你喜欢

Méthodes couramment utilisées dans uniapp - TIMESTAMP et Rich Text Analysis picture
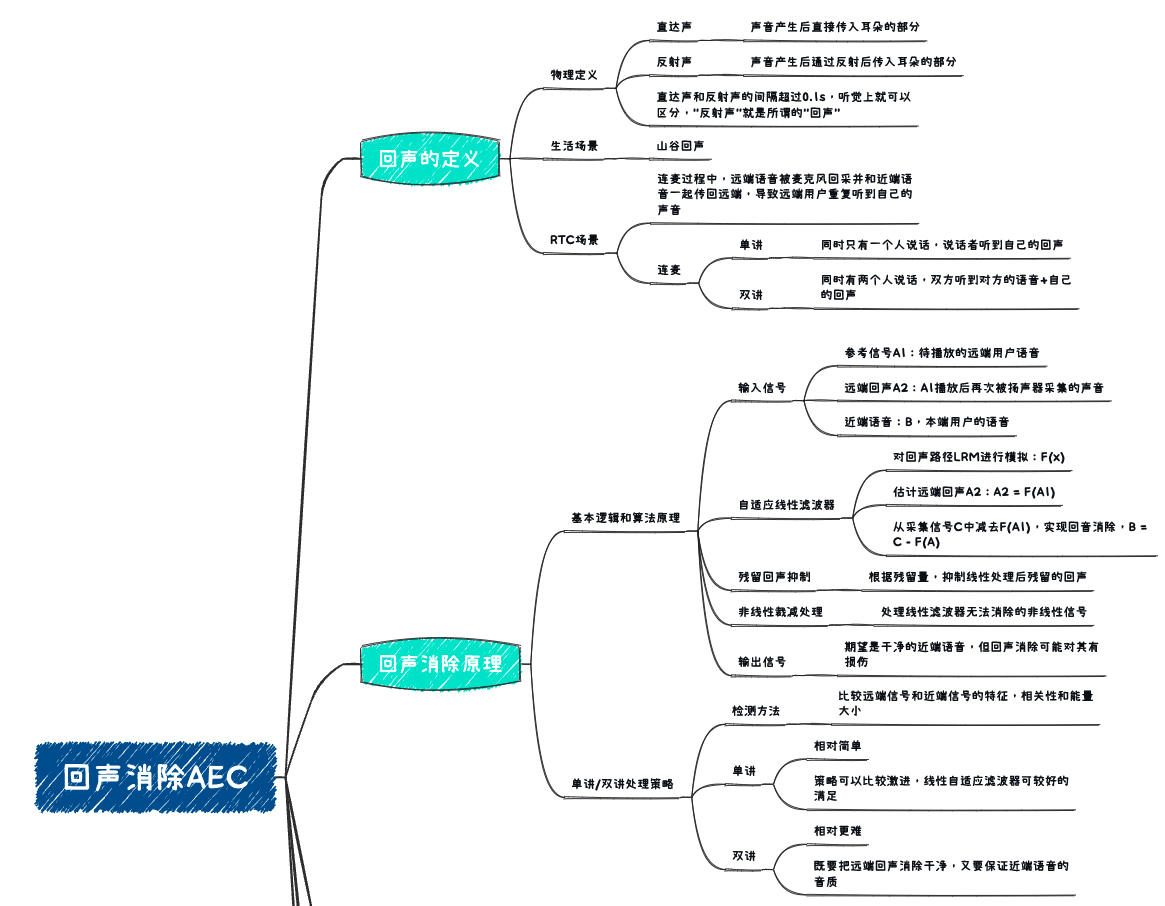
AEC of the three swordsmen in audio and video processing: the cause of echo generation and the principle of echo cancellation

Recommend an easy-to-use designer navigation website

姿态估计之2D人体姿态估计 - Simple Baseline(SBL)
我用 MATLAB 复刻了抖音爆火小游戏 苹果蛇

Vins theory and code explanation 0 -- theoretical basis in vernacular

Interpretation of cube technology | past and present life of cube Rendering Design

作用域和闭包

排序与分页

CentOS Linux is dead! Oracle Linux may be a better alternative
随机推荐
2290. Minimum Obstacle Removal to Reach Corner
顺应医改,积极布局——集采背景下的高值医用耗材发展洞察2022
竟然還有人說ArrayList是2倍擴容,今天帶你手撕ArrayList源碼
企业如何提升文档管理水平
idea新建项目报错org.codehaus.plexus.component.repository.exception.ComponentLookupException:
Opencv 4 handwriting recognition: perfect self built training set
智能电网终极Buff | 广和通模组贯穿“发、输、变、配、用”全环节
【无标题】
"Bloom Cup" 5g Application Award grand slam! Several joint projects of guanghetong won the first, second and third prizes in the general product theme competition
【无标题】
Méthodes couramment utilisées dans uniapp - TIMESTAMP et Rich Text Analysis picture
terminator如何设置字体显示不同颜色
Beginner pytorch step pit
2D human posture estimation for posture estimation - numerical coordinate progression with revolutionary neural networks (dsnt)
姿态估计之2D人体姿态估计 - Numerical Coordinate Regression with Convolutional Neural Networks(DSNT)
ORB_SLAM2视觉惯性紧耦合定位技术路线与代码详解2——IMU初始化
姿态估计之2D人体姿态估计 - Simple Baseline(SBL)
HKU and NVIDIA | factuality enhanced language models for open ended text generation
How to improve document management
Unified certification center oauth2 certification pit