当前位置:网站首页>姿态估计之2D人体姿态估计 - Simple Baseline(SBL)
姿态估计之2D人体姿态估计 - Simple Baseline(SBL)
2022-06-10 15:27:00 【light169】
论文地址:Simple Baselines for Human Pose Estimation and Tracking
代码地址:GitHub - leoxiaobin/pose.pytorch: Simple Baselines for Human Pose Estimation and Tracking
Simple Baselines,是2018年MSRA的工作,网络结构如下图所示。之所以叫这个名字,是因为这个网络真的很简单。该网络就是在ResNet的基础上接了一个head,这个head仅仅包含几个deconvolutional layer,用于提升ResNet输出的feature map的分辨率,我们提到过多次高分辨率是姿态估计任务的需要。这里的deconvolutional layer是一种不太严谨的说法,阅读源代码可知,deconvolutional layer实际上是将transpose convolution、BatchNorm、ReLU封装成了一个结构。所以关键之处在于transpose convolution,可以认为是convolution的逆过程。
从图中看可以发现Simple Baselines的网络结构有点类似Hourglass中的一个module,但可以发现:①该网络没有使用类似Hourglass中的skip connection;②该网络是single-stage,Hourglass是multi-stage的。但令人惊讶的是,该网络的效果却超过了Hourglass。我个人认为有两点原因,一是Simple Baselines以ResNet作为backbone,特征提取能力相比Hourglass更强。二是Hourglass中上采样使用的是简单的nearest neighbor upsampling,而这里使用的是deconvolutional layer,后者的效果更好(后面可以看到在MSRA的Higher-HRNet中依旧使用了这种结构)。
SBL网络结构
SBL(Simple Baseline) [7] 为人体姿态估计提供了一套基准框架。SBL 在主干网络后接逆卷积模块来预测热图,就是在ResNet后加上几层Deconvolution直接生成热力图。相比于其他模型,就是使用Deconvolution替换了上采样结构。将上采样和卷积参数以一种更简单的方式组合到反卷积层中,而不使用跳跃层连接。
Hourglass、CPN、SBL共同点是,采用三个上采样步骤和三个水平的非线性(来自最深处的特征)来获得高分辨率的特征图和heatmap

- 上图中a是Hourglass网络,b是CPN,c是本文的SimplePose,可以直观看出结构的复杂度对比
- 前两种结构需要构造金字塔特征结构,如FPN或从Resnet构建
- SimplePose则不需要构建金字塔特征结构,它是直接在Resnet后面设计反卷积模块并输出结果,是从deep和low分辨率特征生成热图的最简单方法
- 具体结构:首先:在Resnet的基础上,取最后残差模块输出特征层(命名C5)然后:后面接上三个反卷积模块(每个模块为:Deconv + batchnorm + relu,反卷积参数,256通道,4X4卷积核,stride为2,pad为1),最后:用1X1卷积层生成 k个关键点输出热力图
 。
。 - 均方误差(MSE)被用作预测热图和目标热图之间的损失
- 通过应用以第 k 个关节的GT位置为中心的2D高斯函数,生成 k 关节的目标热图
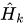 。
。
在这些模型中,可以看出如何生成高分辨率特征图是姿态估计的一个关键,SimplePose采用Deconv扩大特征图的分辨率,Hourglass,CPN中采用的是upsampling+skip方式;当然我们很难就这一个实例就判定那种方式好
姿态追踪问题描述
ICCV’17 PoseTrack Challenge[2]的获胜者[11]解决了这个多人位姿跟踪问题,首先使用Mask RCNN[12]在帧中估计人体位姿,然后使用贪婪二部图匹配算法逐帧进行在线跟踪。
这个贪婪匹配算法,简单来说就是,在视频第一帧中每个检测到的人给一个id,然后之后的每一帧检测到的人都和上一帧检测到的人通过某种度量方式(文中提到的是计算检测框的IOU)算一个相似度,将相似度大的(大于阈值)作为同一个id,并删去。重复以上步骤,直到没有与当前帧相似的实例,此时给剩下的实例分配一个新的id。

本文提出的方法保留了这一方法的主要流程,并且在此之上提出了两点改进:
一是除了检测网络之外,还使用光流法补充一些检测框,用以解决检测网络的漏检问题(比如图2中最左边的人就没有被检测网络检测到)。
二是使用 Object Keypoint Similarity (OKS)代替检测框的IOU来计算相似度。这是因为当人的动作比较快时,用IOU可能并不合理。
OKS是关键点距离的一种度量方式,计算方式如下:
文中提出的新的相似度计算方式具体是使用光流法计算某一帧的关键点会出现在的另外一帧的位置,然后用这个计算出来的位置和这一帧检测出来的关键点之间计算OKS,以此作为两帧之间的不同人的相似度值。
Joint Propagation using Optical Flow
如果在视频中简单地使用单一图像级的检测器(如fast - rcnn [27], R-FCN[16]),由于视频帧引入了运动模糊和遮挡,可能会导致漏检和误检。如图2所示,由于快速运动,探测器错过了左边的黑人。时间信息经常被用来产生更可靠的检测[36,35]。
我们建议使用以光流表示的时间信息,从附近的帧为处理帧生成行人框。
具体的方法是: 给定 帧处的一个实例 i ,有关键点集合
帧处的一个实例 i ,有关键点集合  以及 和
以及 和 之间的光流场
之间的光流场  ,我们可以估计出相应的关键点坐标集合
,我们可以估计出相应的关键点坐标集合 。具体的说,就是对于中的 joints 位置 (x,y),下一帧可能在 ( x + δ x , y + δ y ),其中 δ x 和 δ y 是在(x,y) 处的流场值( flow field values )。当我们计算出的边界,并对其进行扩展后得到的Box 作为 candidated box 。实验使用的扩充值是 15 % 。
。具体的说,就是对于中的 joints 位置 (x,y),下一帧可能在 ( x + δ x , y + δ y ),其中 δ x 和 δ y 是在(x,y) 处的流场值( flow field values )。当我们计算出的边界,并对其进行扩展后得到的Box 作为 candidated box 。实验使用的扩充值是 15 % 。
当由于运动模糊或遮挡,导致行人检测器对当前帧产生了漏检后,我们可以使用从以前帧传播过来的 Boxes ,漏掉的人会被这些框检测到。如图2 (c ) 所示,对于图中左边的黑人,由于我们在图2(a)中有前一帧的跟踪结果,所以传播的box成功地包含了这个人。
Flow-based Pose Similarity
使用边界框IoU (Intersection-over-Union) 作为相似度度量 ( ) 来连接实例可能出现问题,一是当实例移动得很快时,这些框不会重叠;二是在拥挤的场景中,离得近的框中实例不一定有联系。更细粒度的度量可以是姿态相似性 (
) 来连接实例可能出现问题,一是当实例移动得很快时,这些框不会重叠;二是在拥挤的场景中,离得近的框中实例不一定有联系。更细粒度的度量可以是姿态相似性 (  ) ,它使用对象关键点相似性(OKS)计算两个实例之间的身体关节距离。当不同帧时,同一个人的姿势可能会改变,此时姿势相似性也会产生问题。所以,我们建议使用基于流的姿态相似性度量。
) ,它使用对象关键点相似性(OKS)计算两个实例之间的身体关节距离。当不同帧时,同一个人的姿势可能会改变,此时姿势相似性也会产生问题。所以,我们建议使用基于流的姿态相似性度量。
给定 帧处的一个实例关键点  和
和  l 帧处的实例
l 帧处的实例  ,基于流的姿态相似度度量表示为:
,基于流的姿态相似度度量表示为:
其中OKS表示两个人体姿态之间的 Object Keypoint Similarity (OKS) 计算。对于 实例,我们根据光流场 计算帧时的对应,记为
计算帧时的对应,记为
由于与他人或物体的遮挡,行人经常会消失,然后再次出现。考虑连续两帧是不够的。因此,我们有考虑多帧的基于流的位姿相似性,记为  ,这意味着传播
,这意味着传播  来自多个之前帧。通过这种方式,我们甚至可以重新链接在中间帧中消失的实例。
来自多个之前帧。通过这种方式,我们甚至可以重新链接在中间帧中消失的实例。
Flow-based Pose Tracking Algorithm


首先解决姿态估计问题。对于当前处理帧,检测框由行人检测器和之前帧利用光流得到的框组成,并进行非极大抑制(NMS)操作。然后将剪裁和缩放的图片送入姿态估计网络进行姿态估计。
解决跟踪问题。我们将已经跟踪到的实例存储在一个双端队列(Deque) Q 中:![Q=\left[\mathcal{P}_{k-1}, \mathcal{P}_{k-2}, \ldots, \mathcal{P}_{k-L_{Q}}\right]](http://img.inotgo.com/imagesLocal/202205/19/202205191705550781_9.gif)

- 首先,我们解决了姿态估计问题。
- 对于视频中的处理帧,使用bbox非最大抑制(NMS)操作来统一来自人类探测器的box和使用optical flow从先前帧传播关节生成的box。由progagating joints产生的boxes作为检测器缺失检测的补充
- 然后通过我们提出的位姿估计网络,利用这些boxes对经过裁剪和调整大小的图像进行人体姿态估计
- 其次,解决了跟踪问题。我们将被跟踪的实例存储在具有固定长度LQ的双端队列(Deque)中,表示为
![]()
- 其中
 表示在前一帧
表示在前一帧 中设置的被跟踪实例, Q的长度
中设置的被跟踪实例, Q的长度  表示执行匹配时考虑的前帧数量。
表示执行匹配时考虑的前帧数量。 - Q可以用来捕捉先前的多帧链接关系,在视频的第一帧初始化。对于第 k 帧
 ,我们计算未跟踪的身体关节
,我们计算未跟踪的身体关节  (id为none)与Q中先前实例集之间flow基于流的姿势相似性矩阵
(id为none)与Q中先前实例集之间flow基于流的姿势相似性矩阵 。然后通过贪婪匹配和 为 中的每个bodyjoints实例 J分配id ,得到指定的实例集
。然后通过贪婪匹配和 为 中的每个bodyjoints实例 J分配id ,得到指定的实例集 。最后,我们通过添加第 k帧实例集合 来更新跟踪的实例Q。
。最后,我们通过添加第 k帧实例集合 来更新跟踪的实例Q。
 表示在前一帧
表示在前一帧 中设置的被跟踪实例, Q的长度
中设置的被跟踪实例, Q的长度  表示执行匹配时考虑的前帧数量。
表示执行匹配时考虑的前帧数量。 (id为none)与Q中先前实例集之间flow基于流的姿势相似性矩阵
(id为none)与Q中先前实例集之间flow基于流的姿势相似性矩阵 。然后通过贪婪匹配和
。然后通过贪婪匹配和 。最后,我们通过添加第 k帧实例集合
。最后,我们通过添加第 k帧实例集合 边栏推荐
- 竟然還有人說ArrayList是2倍擴容,今天帶你手撕ArrayList源碼
- Click to unlock "keyword" of guanghetong 5g module
- Fast detection of short text repetition rate
- Recommend an easy-to-use designer navigation website
- How to realize ERP extranet connection?
- rk3399_ 9.0 first level menu Network & Internet without setting
- We media video Hot Ideas sharing
- ORB_SLAM2视觉惯性紧耦合定位技术路线与代码详解2——IMU初始化
- Several reasons and solutions of virtual machine Ping failure
- Unified certification center oauth2 certification pit
猜你喜欢

Information theory and coding 2 final review BCH code

ORB_ Slam2 visual inertial tight coupling positioning technology route and code explanation 0 - overall framework and theoretical basic knowledge

【MySQL基础】

推荐一个好用的设计师导航网址
![[high code file format API] Shanghai daoning provides you with the file format API set Aspose, which can create, convert and operate more than 100 file formats in just a few lines of code](/img/43/086da4950da4c6423d5fc46e46b24f.png)
[high code file format API] Shanghai daoning provides you with the file format API set Aspose, which can create, convert and operate more than 100 file formats in just a few lines of code

Sanzi chess (implemented in C language)

Technology sharing | quick intercom, global intercom

Cube 技术解读 | Cube 渲染设计的前世今生

How to build a customer-centric product blueprint: suggestions from the chief technology officer

After class assignment for module 8 of phase 6 of the construction practice camp
随机推荐
Using GDB to quickly read the kernel code of PostgreSQL
Day10/11 recursion / backtracking
Problems with database creation triggers
How the autorunner automated test tool creates a project -alltesting | Zezhong cloud test
【高代码文件格式API】上海道宁为您提供文件格式API集——Aspose,只需几行代码即可创建转换和操作100多种文件格式
Information theory and coding 2 final review BCH code
如何构建以客户为中心的产品蓝图:来自首席技术官的建议
广和通高算力智能模组为万亿级市场5G C-V2X注智
Docket command
Guanghetong high computing power intelligent module injects intelligence into 5g c-v2x in the trillion market
MySQL8安装详细步骤
Get to know RPC
rk3399_ 9.0 first level menu Network & Internet without setting
Vins theory and code explanation 4 - initialization
CAP 6.1 版本发布通告
Cube 技术解读 | Cube 渲染设计的前世今生
凸函数的Hessian矩阵与高斯牛顿下降法增量矩阵半正定性的理解
Sword finger offer 06 Print linked list from end to end
How does CRM help enterprises and salespeople?
如何写一个全局的 Notice 组件?