当前位置:网站首页>Disk troubleshooting of kubernetes node
Disk troubleshooting of kubernetes node
2022-07-27 14:43:00 【New titanium cloud suit】

The new titanium cloud service has been accumulatively shared with you 667 Technical dry goods
Through this paper , You will learn about Kubernetes The correct handling method when the node encounters disk pressure , Including the cause of disk pressure and every step of troubleshooting .
No matter what application you are running , All need some basic resources .CPU、 Memory and disk space are common , Will be used for all applications . Most engineers are interested in how to deal with CPU And memory have a correct understanding , But not everyone takes the time to understand how to use disks correctly .

stay Kubernetes Environment , as time goes on , This could be catastrophic , Because once overloaded ,Kubernetes Will start “ save ” own . This is by killing pod To achieve , Thus reducing the load on the node . If the application does not know how to handle sudden exceptions correctly , This can lead to problems , Or it may result in insufficient resources to handle a given load .
Through this paper , We can well understand and deal with similar disk failures .
What is? Node Disk Pressure
Node disk pressure, seeing the name of a thing one thinks of its function , The disk connected to the node is under pressure . You are unlikely to encounter Node disk pressure, because Kubernetes Some measures are built in to avoid it , But it does happen from time to time . Although there are many factors that can lead to Node disk pressure, But you may encounter two main reasons .
You may encounter Node disk pressure The first reason is Kubernetes Unused images are not cleaned up in time . By default , It shouldn't have happened , because Kubernetes Regularly check whether there are unused images , And then delete it . This is unlikely to be the source of node disk pressure ; however , This should be kept in mind .
Another problem you are likely to encounter is the accumulation of logs .Kubernetes The default behavior in is to save the log in two cases : It will save the log of any running container , And save the log of the recently exited container , To help troubleshoot . This is an attempt to strike a balance between keeping important logs and deleting useless logs over time . however , If you have a long-running container with a large number of logs , Then these logs may accumulate enough to overload the capacity of the node disk .
Find out exactly what the problem is , You need to find out which files take up the most space .
Troubleshooting node disk pressure
To solve the problem of node disk pressure , You need to figure out which files take up the most space . because Kubernetes stay Linux Up operation , So you can run du The command is done easily . You can manually go through SSH Connect to each Kubernetes node , You can also use DaemonSet(https://www.containiq.com/post/using-kubernetes-daemonsets-effectively).
Deployment and understanding DaemonSet
To deploy DaemonSet, You can use DaemonSet Of GitHub Gist(https://gist.githubusercontent.com/omerlh/cc5724ffeea17917eb06843dbff987b7/raw/1e58c8850aeeb6d22d8061338f09e5e1534ab638/daemonset.yaml) , You can also create a file that contains the following :
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: disk-checker
labels:
app: disk-checker
spec:
selector:
matchLabels:
app: disk-checker
template:
metadata:
labels:
app: disk-checker
spec:
hostPID: true
hostIPC: true
hostNetwork: true
containers:
- resources:
requests:
cpu: 0.15
securityContext:
privileged: true
image: busybox
imagePullPolicy: IfNotPresent
name: disk-checked
command: ["/bin/sh"]
args: ["-c", "du -a /host | sort -n -r | head -n 20"]
volumeMounts:
- name: host
mountPath: "/host"
volumes:
- name: host
hostPath:
path: "/"Now you can run the following command :
$ kubectl apply -f https://gist.githubusercontent.com/omerlh/cc5724ffeea17917eb06843dbff987b7/raw/1e58c8850aeeb6d22d8061338f09e5e1534ab638/daemonset.yamlIn the use of DaemonSet Before troubleshooting , It is important to understand what happened . If you look at the manifest file above , You will notice that it is actually a very simple service . Many of them are template files , But the important thing to note is command and args Field . This is the setup du Where the command runs , Then before printing 20 results . following , You can also see that the host volume is in the path /host Bind to container at .
Use DaemonSet
First , You need to make sure DaemonSet Deployed correctly , You can run kubectl get pods -l app=disk-checker To complete . This should produce and output the following :
$ kubectl get pods -l app=disk-checker
NAME READY STATUS RESTARTS AGE
disk-checker-bwkbj 1/1 Running 0 2s What you see here pod The number depends on the number of nodes running in the cluster . After confirming that the node is running , You can perform kubectl logs -l app=disk-checker Start checking the running pod Log . This may take some time , But finally you should see a list of files and their sizes , This will give you a deeper understanding of what takes up space on the node . What you want to do next depends on the file that takes up space —— You need to check DaemonSet And understand what is happening , And whether it is a log file 、 Application files or other files that are using your disk space .
Possible solutions
Analysis and understanding DaemonSet The output of is very important , We can solve the current problem from it . There are two possible solutions .
You may find that the problem is caused by application data , Therefore, the file cannot be deleted . under these circumstances , You will have to increase the size of the node disk to ensure that there is enough space to store application files . This is a relatively simple solution , But it will increase the cost of running the cluster . therefore , A better way is to first look at the structure of the application , See if you can find ways to reduce dependence on application files , Thus reducing the overall demand for disk usage .
On the other hand , You may find that your application generates a large number of files that are no longer needed . under these circumstances , It's as simple as deleting unnecessary files . According to the way your application is set up in terms of availability , You may just need to restart pod, Which leads to Kubernetes Automatically clean up any files in the container . Please note that , This is only done when using temporary volumes , Instead of using persistent volumes .
Last
up to now , You should know what this means when you encounter node disk pressure problems , And what your immediate thoughts should be when you encounter problems : Collect relevant error logs .
You may have to upgrade the size of the disks in the cluster , Or clean up unused files . No matter the problem or the solution , You can now better understand this problem .
Learn about the new titanium cloud service
Previous technical dry goods
· Ten thousand words long text : Cloud Architecture Design Principles | attach PDF download
· Ten thousand words long text | Use RBAC Restricted pair Kubernetes Access to resources
· Ten thousand words long text | oriented k8s Programming , How to write a Operator
· Terraform actual combat | Ten thousand words long text
· CephFS Performance benchmarking and cluster optimization | Ten thousand word summary
· Low code development , Development by the whole people , Eliminate professional programmers !
· Domestic mainstream public cloud VPC Use comparison and summary
· Ceph OSD Troubleshooting | Ten thousand words experience summary
· IT Hybrid cloud strategy : What is it? 、 Why? , How to build ?

Share

Poke at
边栏推荐
- Group division and characteristic analysis of depression patients based on online consultation records
- PROFINET simulator tutorial
- JS什么是声明提前?函数与变量声明提前的先后顺序(执行上下文铺垫篇)
- Printf function buffer problem
- Unity3d learning note 10 - texture array
- Chapter 3 business function development (add clues and remarks, and automatically refresh the added content)
- User question understanding and answer content organization for epidemic disease Science Popularization
- Hdu1422 revisits the world cup [DP]
- Electronic bidding procurement mall system: optimize traditional procurement business and speed up enterprise digital upgrading
- Research on multi label patent classification based on pre training model
猜你喜欢
自动化配置SSH免密登录和取消SSH免密配置脚本
Rtl8762dk environment construction (I)

PROFINET 模拟器使用教程

DVWA full level customs clearance tutorial
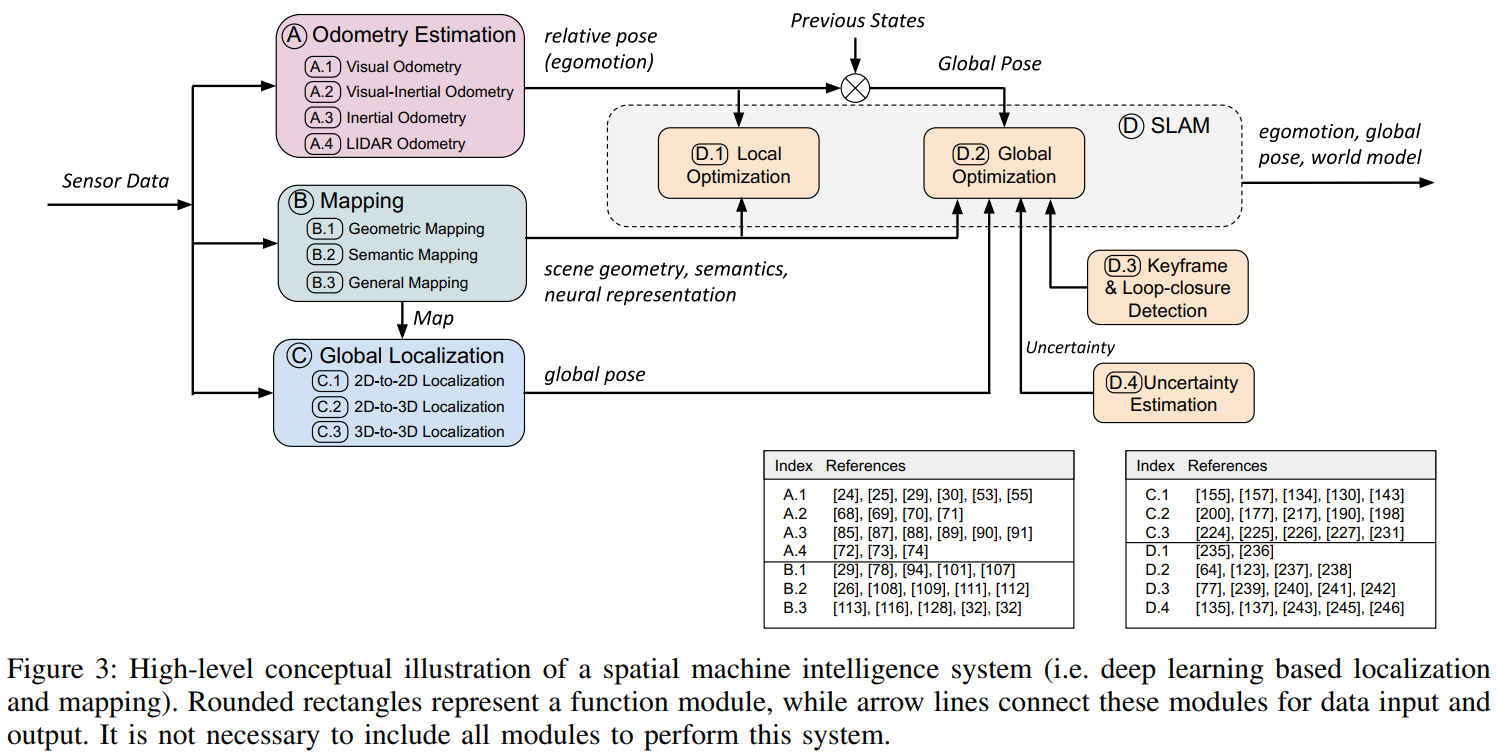
Slam overview Reading Note 4: a survey on deep learning for localization and mapping: towards the age of spatial 2020

【科普】精度和分辨率的区别与联系

Windows10 installing SQL Server 2019
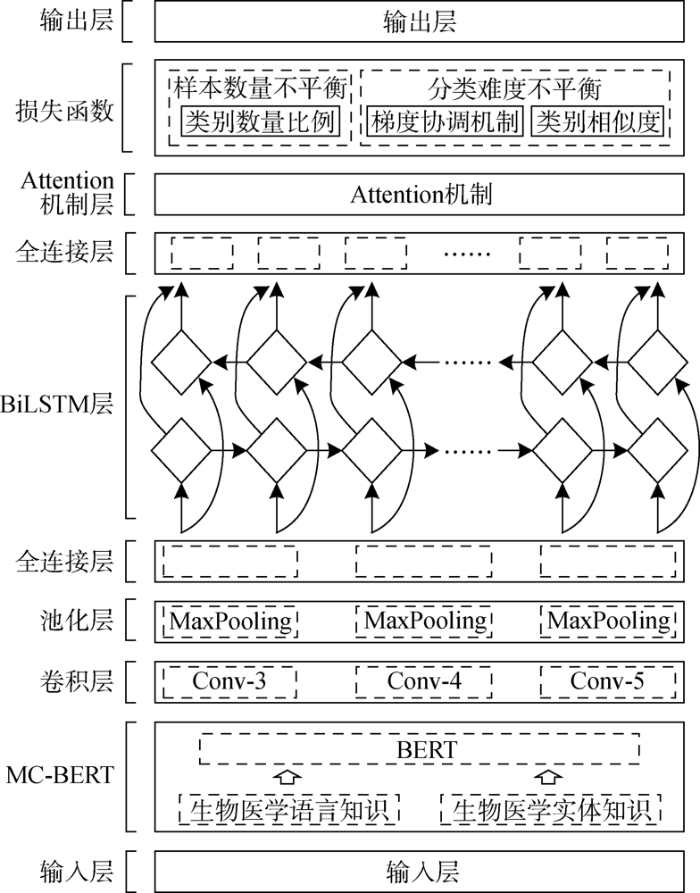
Research on automatic classification of electronic medical records based on unbalanced data

Shell programming specifications and variables

arduino+ZE08-CH2O甲醛模块,输出甲醛含量
随机推荐
知识关联视角下金融证券知识图谱构建与相关股票发现
poj3461 Oulipo【KMP】
How to return to the parent directory with commands
Chinese character style transfer --- antagonistic discriminative domain adaptation (L1)
np. Usage and difference of range() and range()
正则表达式:邮箱匹配
va_ List usage summary
User question understanding and answer content organization for epidemic disease Science Popularization
FPGA timing constraint sharing 04_ Output delay constraint
Blocking queue
DVWA full level customs clearance tutorial
10 practical uses of NFT
Cultural tourism and data collection | travel to Yunnan in an artistic way
Group division and characteristic analysis of depression patients based on online consultation records
MySQL advanced II. Logical architecture analysis
面试官问:如何判断一个元素是否在可视区域?
软件产品第三方测试费用为什么没有统一的报价?
The difference between [x for X in list_a if not np.isnan (x)] and [x if not np.isnan (x) else none for X in list_a]
Research on Chinese idiom metaphorical knowledge recognition and relevance based on transfer learning and text enhancement
【科普】精度和分辨率的区别与联系