当前位置:网站首页>opencv神经网络库之SVM和ANN_MLP的使用
opencv神经网络库之SVM和ANN_MLP的使用
2022-06-10 15:08:00 【HNU_刘yuan】
opencv神经网络库之SVM和ANN_MLP
简介
opencv是计算机视觉最常用的库,里面集成了很多图像处理所需要的函数,最近又使用了其中的SVM(支持向量机)和ANN_MLP(手工设计的多层感知机),两者都是十分经典的“神经网络”,对于算力要求不那么高,并且使用起来十分的方便,速度也较快,同时是集成在opencv中的,不需要安装额外的库。
SVM
在机器学习中,支持向量机(英语:support vector machine,常简称为SVM,又名支持向量网络)是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。
SVM模型是将实例表示为空间中的点,这样映射就使得单独类别的实例被尽可能宽的明显的间隔分开。然后,将新的实例映射到同一空间,并基于它们落在间隔的哪一侧来预测所属类别。
对于一些低维、简单可分的特征一般使用线性核函数即可,对于复杂难分的特征,可以考虑使用非线性核函数,映射到线性可分的核函数。
其优化公式为: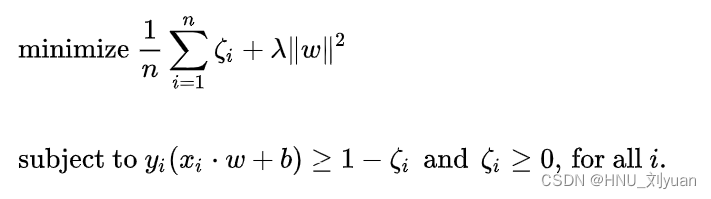
是一个凸优化问题,在此不做展开具体可以参考:SVM
MLP
多层感知器(Multilayer Perceptron,缩写MLP)是一种前向结构的人工神经网络,映射一组输入向量到一组输出向量。MLP可以被看作是一个有向图,由多个的节点层所组成,每一层都全连接到下一层。除了输入节点,每个节点都是一个带有非线性激活函数的神经元(或称处理单元)。
MLP也就是线性层搭建起来的神经网络,其中的激活函数一定是非线性的,比如ReLU、Sigmoid。多层感知机最底层是输入层,中间是隐藏层,最后是输出层。
MLP历史悠久,对于一些简单的分类任务,比如手写数字体识别,可以达到较好的效果。但是对于复杂的机器视觉任务,比如检测、跟踪等,就显得力不从心了。
MLP的详细介绍可以参考:多层感知机
数据读取
SVM和MLP所需要的数据格式都是基本相似的,对于这类监督学习,都需要输入特征和标签。特征可以看作是可观测表现的数据化形式,比如对于图片而言就是像素信息,对于文本而言,可以是其词向量。标签就是特征代表的属性,比如类别等信息。
以常用的MNIST数据集为例:
这是一张数字3的照片,数字3就对应着标签,这张图片的像素值就是数字3表现出的特征。
一般而言,特征的个数与标签的个数应该相同,每个特征对应着一个标签,但是特征的维度通常更高。假如上面的数字3的照片尺寸为16x16x1,以照片的像素作为特征向量,其特征维度就是256维,而其标签维度一般设置为10即可,对应0~9十个数字。
Python环境下的训练和数据读取都更加方便,在此给出其一般情况下数据预处理代码:
import cv2
import numpy as np
import os
import glob
# 以二分类为例
positive_dir = ""# 类别1的图片所在文件夹路径
negative_dir = ""#类别2的图片所在文件夹路径
# 遍历图片
positive_dir_imgs = glob.glob(positive_dir + "*.jpg")
negative_dir_imgs = glob.glob(negative_dir + "*.jpg")
img_size = 40 # 设置图片大小
train_mat=[] # 特征矩阵
labels_label = np.zeros((len(positive_dir_imgs) + len(negative_dir_imgs), 2), np.float32) # 标签矩阵
# 类别1
for positive_dir_img in positive_dir_imgs:
pso_img=cv2.imread(positive_dir_img,0) # 读取灰度图
pso_img = cv2.resize(pso_img, (img_size,img_size)) #处理成固定尺寸
Vect=np.zeros(img_size*img_size) #先行后列
for i in range(img_size):
for j in range (img_size):
Vect[img_size*i+j]=pso_img[i][j] # 将二维图像转化为一维信息
train_mat.append(Vect) # 加入到特征矩阵
print(len(train_mat)) # 类别1数量图片个数
# 类别2
for negative_dir_img in negative_dir_imgs:
nega_img=cv2.imread(negative_dir_img,0)
nega_img = cv2.resize(nega_img, (img_size,img_size))
Vect=np.zeros(img_size*img_size) #先行后列
for i in range(img_size):
for j in range (img_size):
Vect[img_size*i+j]=nega_img[i][j]
train_mat.append(Vect)
print(len(train_mat))
train_mat = np.array(train_mat, dtype=np.float32)
# 标签采用one-hot编码,对于二分类,类别1的标签就是[1,0],类别2是[0,1]
for i in range(len(train_mat)):
if i <= len(positive_dir_imgs):
labels_label[i][0] = 1
labels_label[i][1] = 0
else:
labels_label[i][0] = 0
labels_label[i][1] = 1
自此就完成了数据的处理操作,得到了特征(train_mat)和特征对应的标签(lables_label)
SVM训练和预测
具体可以参考:[SVM文档]
训练
(https://docs.opencv.org/3.4.7/d1/d2d/classcv_1_1ml_1_1SVM.html)
#创建SVM
svm=cv.ml.SVM_create()
#SVM类型
svm.setType(cv.ml.SVM_C_SVC)
#线性核函数
svm.setKernel(cv.ml.SVM_LINEAR)
svm.setC(0.01)
#开始训练(数据,类型,标签)
result = svm.train(train_mat,cv.ml.ROW_SAMPLE,labels_num)
#保存训练模型
svm.save("svm100.xml")
打开保存的xml文件:
可以看出xml文件中保存着SVM的参数,其中的关键信息有输入特征维度为1600,输出标签的维度为2,后面就是SVM具体的网络参数。
python版SVM预测
svm=cv.ml.SVM_load("svm100.xml")# 之前训练保存的数据
test_mat=train_mat[-10:]#SVM预测数据与训练数据处理方法一致,以训练数据为例
print(test_mat)
(P1,P2) = svm.predict(test_mat)#输出结果
print(P1, P2)
C++版SVM预测
稍后再补充。。。
MLP训练和预测
具体可以参考:MLP文档
MLP训练
ann = cv2.ml.ANN_MLP_create()# 创建MLP
ann.setLayerSizes(np.array([img_size*img_size, 64, 2])) #设置MLP的每一层维度,最前面是输入层,中间是隐藏层,最后的输出层维度
ann.setActivationFunction(cv2.ml.ANN_MLP_SIGMOID_SYM, 0.6, 1.0)# 激活函数设置
ann.setTrainMethod(cv2.ml.ANN_MLP_BACKPROP, 0.1, 0.1)# 训练方式
ann.setTermCriteria((cv2.TERM_CRITERIA_MAX_ITER | cv2.TERM_CRITERIA_EPS, 1000, 0.01))
ann.train(train_mat, 0, labels_label)
ann.save("MLP")
打开保存的MLP文件:
和SVM类似,也是包含所有层的维度信息,以及每个神经元的参数。
python版MLP预测
ann = cv2.ml.ANN_MLP_load("MLP")# 加载MLP模型参数
test_mat=train_mat[-10:]#MLP预测数据
(P1,P2) = ann.predict(test_mat)#输出结果
print(P1, P2)
C++版MLP预测
using namespace std;
#define RESIZE 40
int main()
{
std::string xml_path = "MLP";
cv::Ptr<cv::ml::ANN_MLP> ann = cv::ml::ANN_MLP::load(xml_path);
std::string img_path = "/";
cv::Mat frame, frame_resize;
std::vector<std::string> img_paths;
getFiles(img_path, img_paths);
cv::Mat responseMat;
for (int i = 0; i < img_paths.size(); i++)
{
frame = cv::imread(img_paths[i], 0);
cv::resize(frame, frame_resize, cv::Size(RESIZE, RESIZE));
cv::Mat testMat = frame_resize.clone().reshape(1, 1);
testMat.convertTo(testMat, CV_32F);
ann->predict(testMat, responseMat);
float* p = responseMat.ptr<float>(0);
cout << img_paths[i];
if (p[0] > p[1])
{
cout << "predict label 1" << endl;
}
else
{
cout << "predict label 0" << endl;
}
}
return 0;
}
代码汇总
SVM
import cv2
import numpy as np
import os
import glob
positive_dir = "./crop_plane/"
negative_dir = "./random_crop/"
positive_dir_imgs = glob.glob(positive_dir + "*.jpg")
negative_dir_imgs = glob.glob(negative_dir + "*.jpg")
img_size = 100
train_mat=[]
labels_label = np.zeros((len(positive_dir_imgs) + len(negative_dir_imgs), 1), np.int32)
for positive_dir_img in positive_dir_imgs:
pso_img=cv2.imread(positive_dir_img,0)
pso_img = cv2.resize(pso_img, (img_size,img_size))
Vect=np.zeros(img_size*img_size) #先行后列
for i in range(img_size):
for j in range (img_size):
Vect[img_size*i+j]=pso_img[i][j]
train_mat.append(Vect)
train_mat = np.array(train_mat, dtype=np.float32)
print(len(train_mat))
for negative_dir_img in negative_dir_imgs:
nega_img=cv2.imread(negative_dir_img,0)
nega_img = cv2.resize(nega_img, (img_size,img_size))
Vect=np.zeros(img_size*img_size) #先行后列
for i in range(img_size):
for j in range (img_size):
Vect[img_size*i+j]=nega_img[i][j]
train_mat.append(Vect)
print(len(train_mat))
for i in range(len(train_mat)):
if i <= len(positive_dir_imgs):
labels_label[i][0] = 1
else:
labels_label[i][0] = -1
svm=cv2.ml.SVM_create()#SVM类型
svm.setType(cv2.ml.SVM_C_SVC)#线性核函数
svm.setKernel(cv2.ml.SVM_LINEAR)
svm.setC(0.01)#开始训练(数据,类型,标签)
result = svm.train(train_mat,cv2.ml.ROW_SAMPLE,labels_label)#创建列表存放测试样本
svm.save("svm100.xml")
test_mat=train_mat[-10:]#SVM预测
print(test_mat)
(P1,P2) = svm.predict(test_mat)#输出结果
print(P1, P2)
MLP
import cv2
import numpy as np
import os
import glob
positive_dir = "./crop_plane/"
negative_dir = "./random_crop/"
positive_dir_imgs = glob.glob(positive_dir + "*.jpg")
negative_dir_imgs = glob.glob(negative_dir + "*.jpg")
img_size = 40
train_mat=[]
labels_label = np.zeros((len(positive_dir_imgs) + len(negative_dir_imgs), 2), np.float32)
for positive_dir_img in positive_dir_imgs:
pso_img=cv2.imread(positive_dir_img,0)
pso_img = cv2.resize(pso_img, (img_size,img_size))
Vect=np.zeros(img_size*img_size) #先行后列
for i in range(img_size):
for j in range (img_size):
Vect[img_size*i+j]=pso_img[i][j]
train_mat.append(Vect)
print(len(train_mat))
for negative_dir_img in negative_dir_imgs:
nega_img=cv2.imread(negative_dir_img,0)
nega_img = cv2.resize(nega_img, (img_size,img_size))
Vect=np.zeros(img_size*img_size) #先行后列
for i in range(img_size):
for j in range (img_size):
Vect[img_size*i+j]=nega_img[i][j]
train_mat.append(Vect)
print(len(train_mat))
train_mat = np.array(train_mat, dtype=np.float32)
for i in range(len(train_mat)):
if i <= len(positive_dir_imgs):
labels_label[i][0] = 1
labels_label[i][1] = 0
else:
labels_label[i][0] = 0
labels_label[i][1] = 1
ann = cv2.ml.ANN_MLP_create()
ann.setLayerSizes(np.array([img_size*img_size, 64, 2]))
ann.setActivationFunction(cv2.ml.ANN_MLP_SIGMOID_SYM, 0.6, 1.0)
ann.setTrainMethod(cv2.ml.ANN_MLP_BACKPROP, 0.1, 0.1)
ann.setTermCriteria((cv2.TERM_CRITERIA_MAX_ITER | cv2.TERM_CRITERIA_EPS, 1000, 0.01))
print(train_mat.shape)
print(labels_label.shape)
ann.train(train_mat, 0, labels_label)
ann.save("MLP")
test_mat=train_mat[-10:]
print(test_mat)
(P1,P2) = ann.predict(test_mat)#输出结果
print(P1, P2)
边栏推荐
- 洞見科技入選「愛分析· 隱私計算廠商全景報告」,獲評金融解决方案代錶廠商
- Blogger Confessions
- Create a space of local value together. In 2022, China successfully held the "one hundred cities tour · Ningbo Station" for commercial distribution
- 2022第十四届南京国际人工智能产品展会
- Golang beep package playback MP3 cannot get the total length streamer Len() is 0, but other formats can
- 微信小程序 滑动到顶部
- 4、再遇Panuon.UI.Silver之窗体标题栏
- 自推荐-深入理解RUST标准库内核
- Golang []byte 转 File
- JMeter 中如何实现接口之间的关联?
猜你喜欢

【LogoDetection 数据集处理】(1)将数据集切分为训练集和验证集

CVPR 2022 oral | SCI: fast, flexible and robust low light image enhancement

二分查找详解

Super practical operation! Calibration and registration of Kinect depth map and RGB camera for hands-on teaching

Day10/11 递归 / 回溯

Consumption mode of Message Oriented Middleware

作为程序员,对于底层原理真的有那么重要吗?

如何实现erp外网连接?

Meta公司新探索 | 利用Alluxio数据缓存降低Presto延迟

信息论与编码2 期末复习-BCH码
随机推荐
How the autorunner automated test tool creates a project -alltesting | Zezhong cloud test
小程序实现全局数据共享
一款完整的多用户微信公众平台开发源码,带文档免费分享
CANN的接口调用流程概述
Jaeger引入了对OpenTelemetry的原生支持
Sanzi chess (implemented in C language)
svn外网打不开url地址怎么解决
2022第十五届南京国际数字化工业博览会
4. Meet panuon again UI. Title bar of silver form
Super practical operation! Calibration and registration of Kinect depth map and RGB camera for hands-on teaching
反“内卷”,消息称 360 企业安全云将上线“一键强制下班”功能,电脑自动关闭办公软件
Day10/11 递归 / 回溯
Kubernetes 1.24:statefulset introduces maxunavailable copies
数据湖(六):Hudi与Flink整合
如何構建以客戶為中心的產品藍圖:來自首席技術官的建議
Several reasons and solutions of virtual machine Ping failure
Orgin framework notes
2022 the 14th Nanjing International artificial intelligence product exhibition
One-way hash function
2022 the 14th Nanjing International artificial intelligence product exhibition