当前位置:网站首页>Detailed interpretation of hole convolution (input and output size analysis)
Detailed interpretation of hole convolution (input and output size analysis)
2022-07-26 12:28:00 【Midnight rain】
Cavity convolution
Void convolution is proposed mainly to solve the problem of information loss in image segmentation , Previous image segmentation algorithms often use deep convolution neural networks , The convolution layer is often mixed with a pool layer to increase the receptive field , Finally, through a series of up sampling operations, the small-size feature pattern is transformed into the size output of the input image . The use of pool layer can certainly increase the receptive field , But a lot of information will be lost during this operation , This and hinton The idea of pooling layer coincides . In the same way, in the process of upper sampling , There is a problem of accuracy loss when changing from small size to large size , This can be seen in the process of image reduction and restoration . Therefore, we need a method that does not use pooling ( Down sampling ) And upsampling , You can increase the operation of receptive field to replace the original pool + Up sampling operation . Void convolution came into being .
Void convolution and ordinary convolution
There is little difference between void convolution and ordinary convolution , Just one more "dilation rate" Parameters of , This parameter defines the distance between two adjacent elements in the convolution kernel . In ordinary convolution, different elements in convolution kernel are closely connected , In the convolution kernel of hole convolution, the distance between different elements can be different 1, The larger the distance, the larger the receptive field of void convolution ; Or it can also be considered as an ordinary convolution with the same receptive field size , It's just filled with many zero values whose weights are not updated . The schematic diagram of ordinary convolution and void convolution is as follows 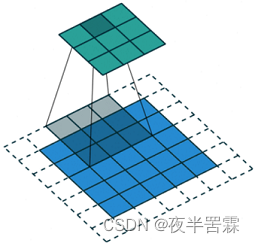

The above figure is ordinary convolution , The following figure for dilation rate=2 Void convolution of time , You can see a 3 × 3 3\times3 3×3 The size of the hole convolution in the convolution operation , The distance between the elements in the core pinch is 2, In fact, it is equivalent to a 5 × 5 5\times 5 5×5 The normal convolution of size only has non-zero value in the checkerboard area .
Ordinary convolution can pass padding The operation makes the size of the input and output characteristic patterns the same , Therefore, hole convolution has the following two advantages .1
- Expand the feeling field : Using hole convolution can make the parameters the same , Increase the receptive field of convolution , Original 3 × 3 3\times3 3×3 The convolution kernel of can only cover an area of 9 Region , The hole convolution with the same parameter can cover an area of 25 Feeling field of . And with dilation rate The promotion of , The receptive field will further increase . It plays the role of the original pool layer .
- Maintain image resolution : Because the hole convolution can be considered as a sparse ordinary convolution , In the process of calculation, we can pass paddding Make the resolution of input and output characteristic patterns the same . Thus, in the image segmentation task , It avoids the loss of information caused by down sampling and up sampling .
The above two advantages make void convolution better suitable for image segmentation tasks , You can abandon the original pooling and upsampling operations . According to the author's description in the paper , By setting up different dilation rate, Convolution has receptive fields of different sizes , Multi scale information can be obtained 2. Therefore, the author uses continuous 7 layer dilation rate The incomplete phases are {1, 1, 2, 4, 8, 16, 1, 1} The void convolution layer of ” Context module (context module)", Thus, multi-scale context information can be aggregated 3.( Tell the truth , I don't see the relationship between this and multi-scale , The author believes that multi-scale information should refer to the operation of characteristic patterns with different resolutions , Such as FPN; Or use convolution of different sizes to check the same characteristic pattern for operation , Splicing again , Such as GoogLeNet, But the void convolution here is connected , Basically, it is similar to a series of convolution layer cascades of different sizes , I don't see the connection with multi-scale , There is no explanation , Perhaps the author means that as long as convolution kernels of different sizes are used, it is even multiscale .)
Calculation of cavity convolution receptive field
The calculation of cavity convolution receptive field is the same as that of ordinary convolution , Just use the real convolution kernel size dilataionn rate Just make up . The size of the common convolution receptive field after stacking is 4:
r n = r n − 1 + ( k n − 1 ) ∏ n = 1 n − 1 s i r_n=r_{n-1}+(k_n-1)\prod^{n-1}_{n=1}s_i rn=rn−1+(kn−1)n=1∏n−1si
among r n r_n rn Is the receptive field size of this layer , k n k_n kn Is the core size of this layer ( Actual coverage size , Void convolution needs to be considered dilation rate, The same is true for pool layer ), s i s_i si For the first time i i i The step size of the layer .
According to the above formula, we can calculate three consecutive stacked 3 × 3 3\times3 3×3,dilation rate ={1,2,4} The receptive fields of the cavity convolution layer are {3,7,15}, This is why the original author said that void convolution supports the exponential growth of receptive field size .
The deficiency of void convolution
Void convolution can certainly increase the receptive field , But it is not difficult to see that it actually ignores part of the inter pixel information , This brings about the following two problems :
- Local correlation is lost : Because the cavity convolution is calculated in a grid form , Elements smaller than the mesh resolution will not participate in the calculation , This means that we will not consider a small range of information when performing convolution . As shown in the following figure 3 × 3 , d = 1 3\times3,d=1 3×3,d=1 Cavity convolution :

The more to the left, the higher the number of floors , It can be seen that the highest level information comes from the mesh vertices 9 Elements , And this 9 Each element calculates the lower level 25 Elements , But this 25 The relationship between elements is not very close , The distance from the top floor is 2 The local connection between the upper left element and the upper middle element in the lower layer has been very weak , Not to mention exploring further . Therefore, it is difficult to capture the local correlation of elements by using void convolution .
2. Small scale detection is weak
This point is actually an extension of the previous point , Since the investigation of local relevant information is insufficient , If there are small objects , This detection method may be skipped .
Follow up improvement plan
For the lack of local correlation of hole convolution , The follow-up study produced two schemes .
1. blend
The hybrid scheme is to think about empty convolution from another angle , It can be considered as down sampling the image at different positions , After ordinary convolution on the down sampled image, it is stitched back to the original size , As shown in the figure below :
The reason for the lack of correlation is that splicing is just a simple matter of time , There is no information fusion for values in different positions . So the hybrid scheme is very simple , Different sampling convolution results can be fused :
2. Standardized construction
Since the problem lies in dialation rate The setting of makes the high-level elements only use some elements within the receptive field , Then we just need to design properly dialation rate All elements in the feeling field can be used .HDC(Hyperbrid dilation Convolution) Thus born , The difference in context module The point is that it uses different dilation rate, And they should conform to certain rules as follows :
- Between different layers dilation rate You can't have anything except 1 Common factor other than . This is easier to understand , If set to [2,4,4] This form , The nature of the grid receptive field has not changed .
- The maximum distance between two non-zero elements on the lower level M 2 < k 2 M_2<k_2 M2<k2. The maximum distance of a non-zero element M i M_i Mi It refers to the maximum distance between two utilized elements when we push back the receptive field , That is, the maximum length of the cavity . k i k_i ki Is the convolution kernel size actually used ( Don't consider dilation). When satisfied M 2 < k 2 M_2<k_2 M2<k2 On this condition , We can at least use a size of k 2 × k 2 k_2\times k_2 k2×k2 To achieve full coverage of receptive field by ordinary convolution . Assume that n A void convolution , M n = r n M_n=r_n Mn=rn, We can find out by backward inference M 2 M_2 M2. Among them the first i i i The maximum distance of non-zero elements in the layer M i M_i Mi The formula is :
M i = m a x [ r i , M i + 1 − 2 r i , M i + 1 − 2 ( M i + 1 − r i ) ] M_i=max[r_i,\ M_{i+1}-2r_i,\ M_{i+1}-2(M_{i+1}-r_i)] Mi=max[ri, Mi+1−2ri, Mi+1−2(Mi+1−ri)]
among r i r_i ri For the first time i Layer of dilation rate. The whole is actually describing the possible distance between the boundary points of the receptive field , It is relatively simple to analyze with a graph , as follows :
Use the above two guidelines , We can design a group of feasible cavity convolution layers in reverse order , Then repeat this set of parameter design . For example, using {1,2,5,1,2,5},{1,2,5} The coverage effect of is as follows , The darker the color, the more the location element participates in the calculation .
Reference resources
边栏推荐
- Knowledge points of C language documents
- Pytest interface automated testing framework | pytest obtains execution data, and pytest disables plug-ins
- UE5 官方案例Lyra 全特性详解 7.资源管理
- 连锁店收银系统如何帮助鞋店管理好分店?
- Redis为什么这么快?Redis的线程模型与Redis多线程
- Why is redis so fast? Redis threading model and redis multithreading
- Backtracking - 131. Split palindrome string
- 酷早报:7月25日Web3加密行业新闻大汇总
- 尤雨溪向初学者推荐Vite 【为什么使用Vite】
- Redis主从复制原理
猜你喜欢
Introduction to FPGA (I) - the first FPGA project

代码报错解决问题经验之二:YOLOv5中的test报错

【Map】万能的Map使用方法 & 模糊查询的两种方式

Jsj-3/ac220v time relay

The difference between JVM memory overflow and memory leak

什么是物联网?常见IoT协议最全讲解

Backtracking - 46. Full arrangement

Hit the blackboard and draw the key points: a detailed explanation of seven common "distributed transactions"
[map] universal map usage & two ways of fuzzy query

Problems and solutions in the learning process of file class
随机推荐
回溯——131. 分割回文串
Use and optimization of MySQL composite index (multi column index)
敲黑板画重点:七种常见“分布式事务”详解
Ubenwa, a start-up under Mila, received an investment of US $2.5 million to study the AI diagnosis of infant health
C语言文件知识点
Customize browser default right-click menu bar
FPGA入门学习(三)- 38译码器
Flink's real-time data analysis practice in iFLYTEK AI marketing business
Why BGP server is used in sunflower remote control? Automatic optimal route and high-speed transmission across operators
Industry case | how does the index help the sustainable development of Inclusive Finance in the banking industry
2022.7.23-----leetcode.剑指offer.115
The difference between JVM memory overflow and memory leak
Ssj-21b time relay
美容院管理系统统一管理制度?
Tencent cloud and smart industry business group (CSIG) adjusted the organizational structure and established the digital twin product department
14.2 byte stream learning
2022 年要了解的新兴安全供应商
Data query of MySQL (aggregate function)
Introduction to FPGA (III) - 38 decoder
酷早报:7月25日Web3加密行业新闻大汇总