当前位置:网站首页>Watermelon book chapter 3 - linear model learning notes
Watermelon book chapter 3 - linear model learning notes
2022-07-27 07:07:00 【Dr. J】
1. The basic form of linear model
- Definition : Given a dataset D, The samples are d Attributes ,
 It's No i Values of attributes , So the linear model can learn a function of linear combination of attributes through such a combination to predict :
It's No i Values of attributes , So the linear model can learn a function of linear combination of attributes through such a combination to predict :
 It's No i Values of attributes , So the linear model can learn a function of linear combination of attributes through such a combination to predict :
It's No i Values of attributes , So the linear model can learn a function of linear combination of attributes through such a combination to predict : 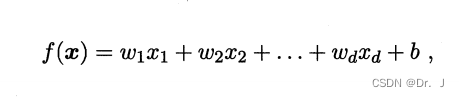
In vector form, that's  , In determining w and b after , You can get the final model .
, In determining w and b after , You can get the final model .
2. Linear regression
Univariate linear regression ( Single attribute )
- Property value conversion : If there is an ordered relationship between the values of discrete attributes , That is, the relationship between values can be found by sorting , Then you can directly convert the value of this attribute into a continuous value , For example, tall, short, fat and thin , Total assets and other attributes ; If you cannot find the numerical relationship by sorting , You need to convert the attribute value into the form of numeric vector , For example, classify melons ,“ watermelon ”,“ pumpkin ”,“ cucumber ” Can be converted to (0,0,1),(0,1,0),(1,0,0)
- Parameters w and b The solution of : The core idea is to minimize the loss function
Specific solution method , Minimize the mean square error :

The mathematical method used is the least square method , That is, trying to find a straight line , Minimize the sum of Euclidean distances from all samples to a straight line :
- First pair w and b To derive separately

- Equal the above two equations to 0 Then set up the equations , To solve the , available :


Multiple linear regression
- The form of the objective function to be learned is :

- The optimization goal is similar to monism , And the mathematical method is also the least square method
summary
The structure of linear model is simple , The solution is also easy to understand , And it has many changes , For example, the logistic regression model in the next chapter
3. Logical regression ( It is called logarithmic probability regression )
- principle : Suppose that the real value of the sample changes on the exponential scale , Then the logarithm of the output marker can be used as the approximation target of the linear model :
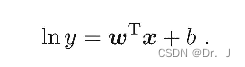
The above formula is still linear regression in form , But the prediction result is a nonlinear mapping from input space to output space

Activation function ( The connection function ): Activation function g(x) It is a function that approximates the predicted value and the real value , above lnx Is a kind of activation function , Thrill The basic properties of a living function need to be monotonically differentiable and always smooth . Therefore, the principle of logical regression classification is to find a suitable activation function to make a more effective connection between the real value and the predicted value
2. Choice of activation function of logistic regression
- Because the real value of the second category is only 0,1 Two options , So the goal is to find an activation function to map the value obtained by linear regression to 0,1 value , As shown in the figure below

According to the requirement that the activation function is monotonically differentiable and smooth enough , Select the logarithmic probability function as  , The final image effect is shown in the above figure , Logistic regression is to use the value of the linear model to approximate the logarithmic probability
, The final image effect is shown in the above figure , Logistic regression is to use the value of the linear model to approximate the logarithmic probability 
3. The advantages of logical regression
- The classification problem can be modeled without first assuming the distribution of data
- While predicting the category, the approximate probability is also calculated
- It can be solved directly by numerical optimization algorithm
summary
Logistic regression has many advantages and the modeling process is simple , See Chapter 3 of watermelon book for specific optimization process
4. Linear discriminant analysis (LDA)
- The core idea : Given a training set , Use some methods to project the data in the training set onto a straight line , The specific task is to make the distance between the projections of similar sample points as close as possible , The projections of different sample points are as far as possible , Here's the picture :

- Definition : The projection of the center of the two types of samples on a straight line is
 and
and  , The covariance of the two sample points is
, The covariance of the two sample points is 
 and
and  , The covariance of the two sample points is
, The covariance of the two sample points is 
and  , Intra class divergence matrix and inter class divergence matrix
, Intra class divergence matrix and inter class divergence matrix

- Optimization objectives : Make the covariance between the same species as small as possible , Make the projection points between different classes as far away as possible , So you get LDA The goal of optimization , It's written in :

perhaps

- computing method : Using Lagrange operator method , It can be solved w Value
5. Multi category learning
- The main idea : Convert multi classification into two classification , Train a classifier for each binary classification task , Then use these classifiers to predict at the same time , Compare the prediction accuracy of each classifier . The main data set splitting methods include one to many , one-on-one , Many to many
- One to one and one to many thoughts : One on one is to N Two species are paired , And then it explains N(N-1)/2 Two sub tasks ; One to many is to treat a class as positive , Others are negative , Training out N A classifier , The specific implementation process is shown in the following figure :

- Advantages and disadvantages of one-to-one and one to many : More classifiers need to be trained one-on-one , It will consume more storage overhead , But one-on-one training only uses two types of data at a time , And one to many, every training needs to use all the data , This will also lead to a lot of time overhead , So when there are many categories , The time cost of one-on-one is often smaller
6. Category imbalance
- It mainly refers to the classification task , There are great differences in the number of training samples in different categories , such as 1000 Samples , Yes 999 One is positive , Only one is the opposite , Then the learned model cannot predict the counterexample , It loses its predictive value
- But this phenomenon can be used in anomaly detection , For example, train a model to detect the quality of aircraft engines through a large number of good samples , In this way, it can learn many characteristics of good samples , Prefer good samples , So if you enter a bad test sample , Then this model will get an abnormal prediction result , At this time, it can be judged that there is a problem with the aircraft engine
边栏推荐
- The vscode run command reported an error: the mark "&" is not a valid statement separator in this version.
- ZnS-DNA QDs近红外硫化锌ZnS量子点改性脱氧核糖核酸DNA|DNA修饰ZnS量子点
- Deepsort工作原理分析
- DNA (deoxyribonucleic acid) supply | carbon nanotube nucleic acid loaded dna/rna material | dna/rna nucleic acid modified magnetic nanoparticles
- Why can cross entropy loss be used to characterize loss
- Future, futuretask and completable future are often asked in interviews
- How to make the minimum API bind the array in the query string
- The issuing process of individual developers applying for code signing certificates
- How to delete or replace the loading style of easyplayer streaming media player?
- [latex format] there are subtitles side by side on the left and right of double columns and double pictures, and subtitles are side by side up and down
猜你喜欢

DNA修饰贵金属纳米颗粒|脱氧核糖核酸DNA修饰纳米金(科研级)
How to delete or replace the loading style of easyplayer streaming media player?

Mysql database

Event capture and bubbling - what is the difference between them?

The vscode run command reported an error: the mark "&" is not a valid statement separator in this version.

【12】 Understand the circuit: from telegraph to gate circuit, how can we "send messages from thousands of miles"?
PNA polypeptide PNA TPP | GLT ala ala Pro Leu PNA | suc ala Pro PNA | suc AAPL PNA | suc AAPM PNA

Deepsort工作原理分析

Reasoning speed of model

Auto encoder (AE), denoising auto encoder (DAE), variable auto encoder (VAE) differences
随机推荐
银行业客户体验管理现状与优化策略分析
Pytorch uses data_ Prefetcher improves data reading speed
DNA modified noble metal nanoparticles | DNA modified gold nanoparticles (scientific research level)
Event capture and bubbling - what is the difference between them?
Boostrap
Vscode connection remote server development
How to make the minimum API bind the array in the query string
DNA modified zinc oxide | DNA modified gold nanoparticles | DNA coupled modified carbon nanomaterials
Cyclegan parsing
Consideration on how the covariance of Kalman filter affects the tracking effect of deepsort
Working principle analysis of deepsort
DataScience:数据生成之在原始数据上添加小量噪声(可自定义噪声)进而实现构造新数据(dataframe格式数据存储案例)
What is the reason why dragging the timeline is invalid when playing device videos on the easycvr platform?
仿真模型简单介绍
MangoDB
About the new features of ES6
Hospital reservation management system based on SSM
IoTDB 的C# 客户端发布 0.13.0.7
关于ES6的新特性
How can chrome quickly transfer a group of web pages (tabs) to another device (computer)