当前位置:网站首页>Improvement 13 of yolov5: replace backbone network C3 with lightweight network efficientnetv2
Improvement 13 of yolov5: replace backbone network C3 with lightweight network efficientnetv2
2022-07-28 22:49:00 【Artificial Intelligence Algorithm Research Institute】
front said : As the current advanced deep learning target detection algorithm YOLOv5, A large number of trick, But there is still room for improvement , For the detection difficulties in specific application scenarios , There are different ways to improve . Subsequent articles , Focus on YOLOv5 How to improve is introduced in detail , The purpose is to provide their own meager help and reference for those who need innovation in scientific research or friends who need to achieve better results in engineering projects .
solve the problem :YOLOv5 The backbone feature extraction network adopts C3 structure , Bring a large number of parameters , The detection speed is slow , Limited application , In some real application scenarios, such as mobile or embedded devices , Such a large and complex model is difficult to be applied . The first is that the model is too large , Facing the problem of insufficient memory , Second, these scenarios require low latency , In other words, the response speed should be fast , Imagine the pedestrian detection system of self driving cars. What terrible things will happen if the speed is slow? . therefore , Research small and efficient CNN Models are crucial in these scenarios , At least for now , Although the hardware will be faster and faster in the future . This paper attempts to replace the backbone feature extraction network with a lighter EfficientNetV2 The Internet , To realize the lightweight of the network model , Balance speed and accuracy .
The following is a history blog post .
YOLOv5 Improvement Xi : Backbone network C3 Replace with lightweight network MobileNetV3_ AI algorithm engineer 0301 The blog of -CSDN Blog
YOLOv5 Improvement 12 : Backbone network C3 Replace with lightweight network ShuffleNetV2_ AI algorithm engineer 0301 The blog of -CSDN Blog
principle :
Address of thesis :https://arxiv.org/abs/2104.0029
Google's MingxingTan And Quov V.Le Yes EfficientNet An upgrade , The purpose is to maintain the efficient use of parameters and improve the training speed as much as possible . stay EfficientNet On the basis of , Introduced Fused-MBConv Into search space ; At the same time, adaptive regularization intensity adjustment mechanism is introduced for incremental learning . The combination of the two improvements gives the result of this paper EfficientNetV2, It has achieved... On multiple benchmark datasets SOTA performance , And training faster . such as EfficientNetV2 made 87.3% Of top1 Precision and fast training speed 5-11 times .

Fang Law :
Step 1 modify common.py, increase MobileNetV3 modular .
class stem(nn.Module):
def __init__(self, c1, c2, kernel_size=3, stride=1, groups=1):
super().__init__()
self.conv = nn.Conv2d(c1, c2, kernel_size, stride, padding=padding, groups=groups, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=1e-3, momentum=0.1)
self.act = nn.SiLU(inplace=True)
def forward(self, x):
# print(x.shape)
x = self.conv(x)
x = self.bn(x)
x = self.act(x)
return x
def drop_path(x, drop_prob: float = 0., training: bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class SqueezeExcite_efficientv2(nn.Module):
def __init__(self, c1, c2, se_ratio=0.25, act_layer=nn.ReLU):
super().__init__()
self.gate_fn = nn.Sigmoid()
reduced_chs = int(c1 * se_ratio)
self.conv_reduce = nn.Conv2d(c1, reduced_chs, 1, bias=True)
self.act1 = act_layer(inplace=True)
self.conv_expand = nn.Conv2d(reduced_chs, c2, 1, bias=True)
def forward(self, x):
x_se = self.avg_pool(x)
x_se = self.conv_reduce(x_se)
x_se = self.act1(x_se)
x_se = self.conv_expand(x_se)
x_se = self.gate_fn(x_se)
x = x * (x_se.expand_as(x))
return x
class FusedMBConv(nn.Module):
def __init__(self, c1, c2, k=3, s=1, expansion=1, se_ration=0, dropout_rate=0.2, drop_connect_rate=0.2):
super().__init__()
assert s in [1, 2]
self.has_shortcut = (s == 1 and c1 == c2)
expanded_c = c1 * expansion
if self.has_expansion:
self.expansion_conv = stem(c1, expanded_c, kernel_size=k, stride=s)
self.project_conv = stem(expanded_c, c2, kernel_size=1, stride=1)
else:
self.project_conv = stem(c1, c2, kernel_size=k, stride=s)
self.drop_connect_rate = drop_connect_rate
if self.has_shortcut and drop_connect_rate > 0:
self.dropout = DropPath(drop_connect_rate)
def forward(self, x):
if self.has_expansion:
result = self.expansion_conv(x)
result = self.project_conv(result)
else:
result = self.project_conv(x)
if self.has_shortcut:
if self.drop_connect_rate > 0:
result = self.dropout(result)
result += x
return result
class MBConv(nn.Module):
def __init__(self, c1, c2, k=3, s=1, expansion=1, se_ration=0, dropout_rate=0.2, drop_connect_rate=0.2):
super().__init__()
assert s in [1, 2]
self.has_shortcut = (s == 1 and c1 == c2)
# print(c1, c2, k, s, expansion)
expanded_c = c1 * expansion
self.dw_conv = stem(expanded_c, expanded_c, kernel_size=k, stride=s, groups=expanded_c)
self.se = SqueezeExcite_efficientv2(c1, expanded_c, se_ration) if se_ration > 0 else nn.Identity()
self.project_conv = stem(expanded_c, c2, kernel_size=1, stride=1)
self.drop_connect_rate = drop_connect_rate
if self.has_shortcut and drop_connect_rate > 0:
self.dropout = DropPath(drop_connect_rate)
def forward(self, x):
# print(x.shape)
result = self.expansion_conv(x)
result = self.dw_conv(result)
result = self.se(result)
result = self.project_conv(result)
if self.has_shortcut:
if self.drop_connect_rate > 0:
result = self.dropout(result)
result += x
return result
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5, e=0.5, ratio=1.0): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
# c_ = c1 // 2 # hidden channels
c_ = int(c1 * e)
c2 = int(c2 * ratio)
c2 = make_divisible(c2, 8)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))The second step : take yolo.py Registration module in .
if m in [Conv,MobileNetV3_InvertedResidual,ShuffleNetV2_InvertedResidual, ]:
The third step : modify yaml file
backbone:
[[-1, 1, stem, [24, 3, 2]], # 0-P1/2
[-1, 2, FusedMBConv, [24, 3, 1, 1, 0]], # 1-p2/4
[-1, 1, FusedMBConv, [48, 3, 2, 4, 0]], # 2
[-1, 3, FusedMBConv, [48, 3, 1, 4, 0]], # 3
[-1, 1, FusedMBConv, [64, 3, 2, 4, 0]], # 4
[-1, 3, FusedMBConv, [64, 3, 1, 4, 0]], # 5
[-1, 1, MBConv, [128, 3, 2, 4, 0.25]], # 6
[-1, 5, MBConv, [128, 3, 1, 4, 0.25]], # 7
[-1, 1, MBConv, [160, 3, 2, 6, 0.25]], # 8
[-1, 8, MBConv, [160, 3, 1, 6, 0.25]], # 9
[-1, 1, MBConv, [256, 3, 2, 4, 0.25]], # 10
[-1, 14, MBConv, [256, 3, 1, 4, 0.25]], # 11
[-1, 1, SPPF, [1024, 5]], #12
# [-1, 1, SPP, [1024, [5, 9, 13]]],
]
# YOLOv5 v6.0 headjunction fruit : I have done a lot of experiments on multiple data sets , For different data sets, the effect is different ,map Value down , But the size of the weight model decreases , The parameter quantity decreases .
Let me know : The next article will continue to share network lightweight methods ghost The share of . Interested friends can pay attention to me , If you have questions, you can leave a message or chat with me in private
PS: The replacement of backbone network is not only applicable to improvement YOLOv5, You can also improve others YOLO Network and target detection network , such as YOLOv4、v3 etc. .
Last , I hope I can powder each other , Be a friend , Learn and communicate together .
边栏推荐
- Fastflow [abnormal detection: normalizing flow]
- Awk blank line filtering
- 770. Word replacement
- JS get the current time (year month day hour minute second)
- PaddleNLP基于ERNIR3.0文本分类以中医疗搜索检索词意图分类(KUAKE-QIC)为例【多分类(单标签)】
- 基于Ernie-3.0 CAIL2019法研杯要素识别多标签分类任务
- 842. 排列数字
- [3D target detection] 3dssd (I)
- PC side special effects - animation function
- Ngx+sql environment offline installation log (RPM installation)
猜你喜欢
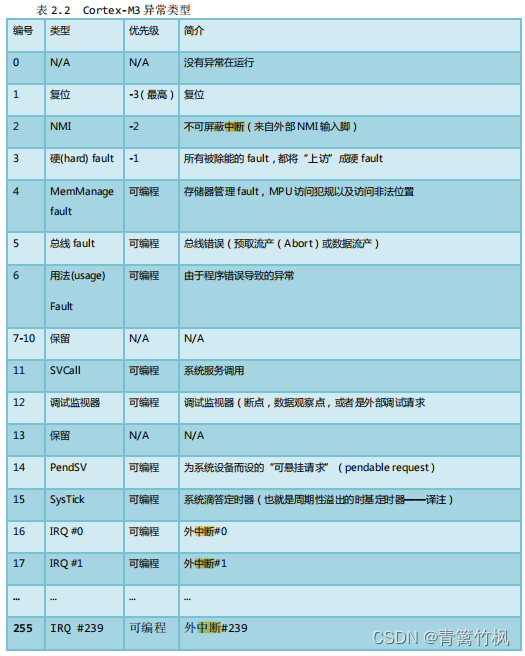
STM32 - interrupt overview (interrupt priority)
![MKD [anomaly detection: knowledge disruption]](/img/15/10f5c8d6851e94dac764517c488dbc.png)
MKD [anomaly detection: knowledge disruption]

【三维目标检测】3DSSD(一)

842. 排列数字

Using PCL to batch display PCD point cloud data flow
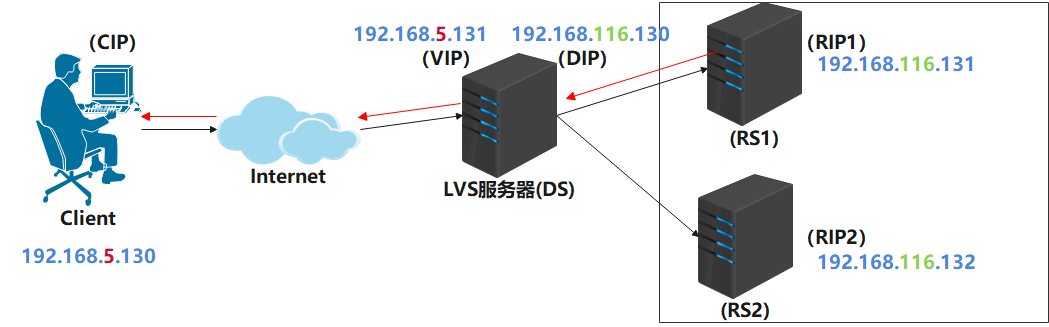
Lvs+keepalived high availability deployment practical application

STM32CUBEIDE(10)----ADC在DMA模式下扫描多个通道

STM32 single chip microcomputer drive L298N
![Fastflow [abnormal detection: normalizing flow]](/img/5e/984e5bd34c493039e3c9909fc4df05.png)
Fastflow [abnormal detection: normalizing flow]
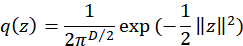
Anomaly detection summary: intensity_ based/Normalizing Flow
随机推荐
Simple es highlight practice
WinForm jump to the second form case
es个人整理的相关面试题
职场pua但有道理
How to use sprintf function
[reprint] the token token is used in the login scenario
PUA in the workplace, but it makes sense
ES6, deep copy, shallow copy
hp proliant dl380从U盘启动按哪个键
Using PCL to batch display PCD point cloud data flow
Fastflow [abnormal detection: normalizing flow]
Detection and tracking evaluation index
C language to realize string reverse order arrangement
Anomaly detection summary: intensity_ based/Normalizing Flow
OSV-q The size of tensor a (3) must match the size of tensor b (320) at non-singleton dimension 3
Image is referred in multiple repositories
Ngx+sql environment offline installation log (RPM installation)
(重要)初识C语言 -- 函数
There will be a black line on the border when the button in the wechat applet is clicked
[get mobile information] - get mobile information through ADB command