当前位置:网站首页>MKD [anomaly detection: knowledge disruption]
MKD [anomaly detection: knowledge disruption]
2022-07-28 22:41:00 【It's too simple】
Preface
The blog is from 2020.11CVPR A paper on , Take knowledge distillation as the main idea , Innovative way of adding multi-scale distillation , Make information transmission more sufficient .
background
Previous models only used the last layer of output as the way of knowledge distillation , This model also distills the middle layer output . The higher the number of layers , The richer the image semantic information , Using only the last layer will cause the model to converge to irrelevant regions . Knowledge can be understood as the value and direction of the vector in the middle layer . Use the Euclidean distance as the loss function for the value ( See interesting knowledge for explanation ), See the formula in the original paper (1), The loss function is set before the activation function . Use cosine similarity measure to do loss function for direction , See the formula in the original paper (3), Only using Euclidean distance here will cause the activation function to erase some vectors used to extract features , See formula for explanation (2) It's about for instance Description after .
VGG The network performs better in classification and migration tasks . Here, the network selects the last pooling layer of each convolution block as the key layer .

Model principle
During training ,VGG-16 The network ImageNet Pre trained on large natural data sets . Then input the normal diagram VGG Source network and clone network , Compare the characteristic diagram of the middle key layer , Update clone network ( Fewer clone network channels ), Complete the training process . Verification time , Abnormal image input ,VGG Vector of source network and clone network at the middle layer , The total loss obtained by the sum of distance loss and direction loss is obtained by gradient algorithm ( Find the pixel that has the greatest impact on the gradient ) Combined with Gaussian filtering ( Eliminate the influence of noise ) And open morphological filtering to generate segmentation location map .
Popular speaking , The source network has been pre trained on large natural data sets , Not sensitive to abnormal data , But because the clone network has not seen the abnormal figure , So clone network will be sensitive to abnormal data , The difference between the two networks locates the abnormal area . Equivalent to the teacher only handed in part of the students' knowledge , Encountered variant , The teacher knows more , Be able to learn and use flexibly , Students can only stare .
Interesting knowledge
Using deviation is easy to produce constant value function , When the network is trained with a normal graph with high similarity , Cause the network not to converge , Impact effect , See the source paper references for explanation 【33】. So clone networks don't use bias . When producing layers with similar output , take l The layer weight is set to 0, And adjust l+1 Layer deviation .
Euclid distance ( The actual distance between two points ): In information or multidimensional space , It is often measured by some relative distance or measure , That is, the distance similarity between vectors .
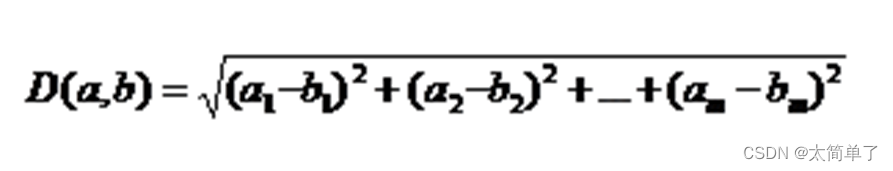
Cosine similarity measure : Judge the similarity based on the angle between vectors , That is, the closer the cosine value is to 1, The included angle degree is close to 0 degree .

The composition of the network : Network architecture 、 Loss function 、 Interpretability algorithm ( The explained loss function helps to segment and locate ), During training , The loss function comes out after forward propagation , Using loss function back propagation to update clone network . Verification time , Forward propagating loss function , The interpretable algorithm locates the exception .
Yes S-T The Internet ( Original papers 【8】) Evaluation comparison :(1) All adopt knowledge distillation , but MKD Distill features into clone Networks ,ST Pre training with distillation .(2) Both adopt dual network training , but MKD Compare the middle layer ,ST Compare the output of the last layer .(3) All adopt pre training network , Using the features of natural images . Compare disadvantages :(1) Only imitate the last layer , Not making full use of teachers' network knowledge , Complicate the model (2) Adopt complementary technology , Self supervised learning , Increase cost (3) Depending on the size of the small block , Make it into different pieces , Increase training costs .
experiment
Ablation Experiment
Choose a different number of middle layers ; Select a smaller number of channels to compare with the same clone network , There are obvious abnormal figures in some local areas , Networks with fewer channels perform better , Other types of anomaly diagrams are approaching ; Comparison between selecting two loss functions and selecting a single loss function respectively ; Use different interpretative algorithms (Gradients/SmoothGrad/GBP) Comparison with Gauss filtering .
Comparative experiments
Comparison between different data sets and the same model ; Comparison between different models and the same data set ; It is worth noting that the network effect after using data enhancement is a little better .
边栏推荐
- Wechat applet uses canvas drawing, round avatar, network background, text, dotted line, straight line
- JS implementation generates a random key of specified length
- Paddlenlp is based on ernir3.0 text classification. Take the traditional Chinese medicine search and retrieval semantic map classification (kuake-qic) as an example [multi classification (single label
- Remember the first line segment tree (corresponding to Luogu 3372)
- Redis related
- [connect your mobile phone wirelessly] - debug your mobile device wirelessly via LAN
- [CVPR 2021] cylinder3d: cylindrical asymmetric 3D convolution network for LIDAR point cloud segmentation
- PUA in the workplace, but it makes sense
- JVM -- custom class loader
- fatal error: io. h: No such file or directory
猜你喜欢

6K6w5LiA5qyh5pS75Ye75YiG5p6Q

【转载】token令牌在登录场景使用

Vscode ROS configuration GDB debugging error record

Att & CK preliminary understanding

(翻译)图技术简明历史

GD32F303固件库开发(10)----双ADC轮询模式扫描多个通道

STM32 - advanced control timer (time base unit, functional block diagram, input, capture, output, open circuit)

STM32 board level support package for keys

JVM -- custom class loader

Solve Jupiter: the term 'Jupiter' is not recognized as the name of a cmdlet, function, script file
随机推荐
Sword finger offer II 057. the difference between the value and the subscript is within the given range (medium array bucket sort sliding window TreeSet)
Install PCL and VTK under the background of ROS installation, and solve VTK and PCL_ ROS conflict problem
[connect set-top box] - use ADB command line to connect ec6108v9 Huawei Yuehe box wirelessly
MySQL built-in functions
职场pua但有道理
JVM -- custom class loader
PaddleNLP基于ERNIR3.0文本分类以CAIL2018-SMALL数据集罪名预测任务为例【多标签】
Concise history of graphic technology
Lvs+keepalived high availability deployment practical application
20-09-27项目迁移到阿里折腾记录(网卡顺序导致服务无法通过haproxy连接到db)
The function of wechat applet to cut pictures
Win11 how to open software notification
Excel-vba quick start (XIII. Common usage of date)
redis相关
Kali source solution software cannot be installed correctly
GD32F303固件库开发(10)----双ADC轮询模式扫描多个通道
Summary of recent bugs
基于Ernie-3.0 CAIL2019法研杯要素识别多标签分类任务
BOM (location object, navigation object)
Att & CK preliminary understanding