当前位置:网站首页>Technical dry goods Shengsi mindspire dynamic transformer with variable sequence length has been released!
Technical dry goods Shengsi mindspire dynamic transformer with variable sequence length has been released!
2022-07-03 07:44:00 【Shengsi mindspire】

be engaged in AI Algorithm research friends all know , With Transformer Neural networks based on self attention mechanism, represented by, have been used in large-scale text modeling 、 Text emotional understanding 、 Machine translation and other fields have achieved significant performance improvement and a wide range of practical applications . In recent years ,Transformer Series of models to effectively enhance CNN The lack of long-distance dependency modeling ability , It has also achieved great success in the field of vision , It is widely used . Practical application , As the size of the dataset increases , because Transformer Usually, all input samples are characterized as a fixed number tokens, Expenses have also increased dramatically . The research team found that the fixed length token It is inefficient and suboptimal to represent all the images in the data set !
So , The research team of Mr. Huang Gao of Tsinghua University and the central media Technology Institute of Huawei jointly studied the trends Transformer The latest job of Not All Images are Worth 16x16 Words: Dynamic Transformers for Efficient Image Recognition (https://arxiv.org/pdf/2105.15075.pdf, Has been NeurIPS 2021 receive ), The most appropriate... Can be used adaptively for each sample token Number to characterize , And in Github Publish on MindSpore Training reasoning code implemented :
https://github.com/blackfeather-wang/Dynamic-Vision-Transformer-MindSpore, It can make the training accuracy of the model equal , Average reasoning acceleration 1.6-3.6 times ! dynamic Transformer The model will be synchronized to MindSpore ModelZoo
(https://gitee.com/mindspore/models/tree/master) in , It can be obtained and used directly .

chart 1 Dynamic Vision Transformer(DVT) Example
● Background technology ●
In recent years ,Google The job of Vision Transformer(ViT) A series of visual models have received extensive attention , These models usually divide the image data into a fixed number of objects patch, And will each patch The corresponding pixel values are embedded into one-dimensional images by means of linear mapping token, As Transformer Model input , Schematic diagram 2 Shown .

chart 2 Vision Transformer(ViT) Representation of input
Suppose the model structure is fixed , each token The dimension size is fixed , Characterize the input as more token It can realize more fine-grained modeling of images , It can often effectively improve the test accuracy of the model ; However, in contrast , because Transformer The computational overhead varies with token The number increases to the power of two , An increase in token It will lead to a large increase in computing overhead . In order to strike a proper balance between accuracy and efficiency , The existing ViT The model will generally token The number is set to 14x14 or 16x16.
The paper proposes , A more suitable method should be , According to the specific characteristics of each input , Set the most appropriate... For each picture token number . In an effort to 3 For example , The apple picture on the left is simple in composition and large in size , The picture on the right contains a complex crowd 、 Architecture 、 Lawn and other contents, and the object size is small . obviously , The former requires only a small amount of token Can effectively characterize its content , The latter requires more token Describe the complex relationship between different composition elements .

chart 3 Determine according to specific input token number
This problem is very critical to the reasoning efficiency of the network . From the table 1 Can be seen in , If the token Number set to 4x4, The accuracy has only decreased 15.9%(76.7% v.s. 60.8%), But the computational overhead has decreased 8.5 times (1.78G v.s. 0.21G). This result shows that , Correctly identify the relatively large part of the data “ Simple ” A sample of just 4x4 Or less token, Quite a lot of computation is wasted on using a system with a lot of redundancy 14x14 token Represent them !
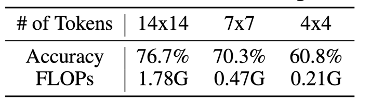
surface 1 T2T-ViT-12 Use less token Test accuracy and calculation overhead
● Algorithm principle ●
dynamic ViT Reasoning training process
Inspired by the above phenomena , This paper presents a dynamic vision system Transformer frame (Dynamic Vision Transformer,DVT), It is intended to select an appropriate number of... For each sample token To represent .
First introduced DVT The process of reasoning , Pictured 4 Shown , For any test sample , Firstly, it is roughly characterized as the smallest number token, Judge whether the prediction result is credible , If credible , Then the current result is directly output and the reasoning is terminated ; If it's not credible , Then activate the next Transformer Represent the input image as more token, More granular 、 But the more computationally expensive reasoning , After getting the result, judge again whether it is credible , And so on . It is worth noting that , Downstream Transformer The depth features generated by the upstream model can be reused ( Feature reuse mechanism ) And attention map ( Relationship reuse mechanism ), To avoid redundant and repeated calculations as much as possible .

chart 4 Dynamic Vision Transformer(DVT)
The training network achieves correct prediction results at all exits , The training objectives are as follows . among

And represent data and labels respectively , On behalf of exit softmax Prediction probability , Represents the cross entropy loss .

Feature reuse mechanism
When one is in the downstream position Transformer When activated , They should be trained in previous Transformer Based on the characteristics of , Not entirely from 0 Start re extracting features . Based on this , This paper proposes a feature reuse mechanism to make training more efficient , Here's the picture 5 Shown . Will be upstream Transformer Feature extraction of the output of the last layer , After multilayer perceptron transformation and up sampling , As a context, it is embedded and integrated into the multi-layer perceptron module of each layer of the downstream model .

chart 5 Characteristics of reuse (Feature Reuse) Mechanism
Relationship reuse mechanism
In addition to the feature reuse mechanism , The downstream model can also use the upstream model Transformer The attention map has been obtained to model the global attention relationship more accurately , Based on this , Propose relationship reuse mechanism , The schematic diagram is shown in the figure below 6 Shown . The full attention map of the upstream model is shown as logits In the form of integration , the MLP After transform and upsampling , Add to the bottom of each attention map logits in . such , Of each layer of the downstream model attention All modules can flexibly reuse all data in different depths of the upstream model attention Information , And this reuse of information “ Strength ” By changing MLP The parameters of are automatically adjusted .

chart 6 Relationship reuse (Relationship Reuse) Mechanism
MindSpore Experimental results
MindSpore It only needs two lines of code to call general dynamics ViT(DVT) frame , Pictured 7 Shown , Input two types token Of ViT The Internet , And set whether feature reuse and relationship reuse are enabled , After training , Pictured 8 Shown , Can be in ImageNet Get on 1.6-3.6 Times of reasoning speed up !

chart 7 MindSpore DVT Calling method

chart 8 MindSpore+DVT(DeiT) stay ImageNet Computational efficiency on
chart 9 Simple and difficult visual sample results are given .

chart 9 Visualization results
● summary ●
The following summarizes the value of this study :
(1) For visual Transformer A natural 、 Universal 、 An effective adaptive reasoning framework , Both theoretical and practical effects are remarkable .
(2) This paper puts forward an enlightening idea , Divide all pictures in a fixed way patch The way of representation , Is not flexible enough and suboptimal , A more reasonable strategy is , The characterization mode should be dynamically adjusted according to the input data . This may be for the development of efficient 、 Strong explanatory ability 、 General vision with good mobility Transformer Provides a new direction .
(3) This dynamic reasoning of dynamically adjusting the representation according to the input data also provides a good direction for the application to dynamic training .
Finally, I would like to thank Professor Huang Gao of Tsinghua University, doctoral student Wang Yulin and experts from the Central Academy of media technology for their contributions , Link to the author's home page :www.rainforest-wang.cool.
Reference material :
[1] Wang Y, Huang R, Song S, et al. Not All Images are Worth 16x16 Words: Dynamic Vision Transformers with Adaptive Sequence Length[J]. arXiv preprint arXiv:2105.15075, 2021.
[2] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[3] https://www.mindspore.cn/
[4] https://github.com/blackfeather-wang/Dynamic-Vision-Transformer-MindSpore

MindSpore Official information
GitHub : https://github.com/mindspore-ai/mindspore
Gitee : https : //gitee.com/mindspore/mindspore
official QQ Group : 871543426
边栏推荐
- PDO and SDO concepts
- [MySQL 11] how to solve the case sensitive problem of MySQL 8.0.18
- 在浏览器输入url后执行什么
- 技术干货|昇思MindSpore算子并行+异构并行,使能32卡训练2420亿参数模型
- [Development Notes] cloud app control on device based on smart cloud 4G adapter gc211
- Industrial resilience
- Read config configuration file of vertx
- Partage de l'expérience du projet: mise en œuvre d'un pass optimisé pour la fusion IR de la couche mindstore
- Go language foundation ----- 02 ----- basic data types and operators
- Pgadmin 4 v6.11 release, PostgreSQL open source graphical management tool
猜你喜欢

项目经验分享:实现一个昇思MindSpore 图层 IR 融合优化 pass

Analysis of the eighth Blue Bridge Cup single chip microcomputer provincial competition

Lucene hnsw merge optimization

技术干货|昇思MindSpore创新模型EPP-MVSNet-高精高效的三维重建
![[MySQL 11] how to solve the case sensitive problem of MySQL 8.0.18](/img/9b/db5fe1a37e0de5ba363f9e108310a5.png)
[MySQL 11] how to solve the case sensitive problem of MySQL 8.0.18
技术干货|关于AI Architecture未来的一些思考
Usage of requests module

PAT甲级 1029 Median

Go language foundation ----- 11 ----- regular expression

密西根大学张阳教授受聘中国上海交通大学客座教授(图)
随机推荐
Go language - loop statement
Leetcode 198: house raiding
C2 several methods of merging VCF files
static关键字
Segment read
yarn link 是如何帮助开发者对 NPM 包进行 debug 的?
PAT甲级 1029 Median
【MySQL 11】怎么解决MySQL 8.0.18 大小写敏感问题
Go language foundation ----- 06 ----- anonymous fields, fields with the same name
Lucene skip table
Go language foundation ------17 ----- channel creation, read-write, security shutdown, multiplexing select
PAT甲级 1028 List Sorting
PHP微信抢红包的算法
Epoll related references
Hello world of vertx
Go language foundation ----- 15 ----- reflection
技术干货|百行代码写BERT,昇思MindSpore能力大赏
华为交换机基础配置(telnet/ssh登录)
Logging log configuration of vertx
Go language foundation ----- 03 ----- process control, function, value transfer, reference transfer, defer function