当前位置:网站首页>Benchmarking Lane-changing Decision-making for Deep Reinforcement Learning
Benchmarking Lane-changing Decision-making for Deep Reinforcement Learning
2022-08-03 19:31:00 【时代&信念】
摘要
近年来,自动驾驶的发展受到广泛关注,对自动驾驶性能的评价至关重要。然而,在路上进行测试既昂贵又低效。虚拟测试是验证和验证自动驾驶汽车的主要方式,虚拟测试的基础是构建模拟场景。在本文中,我们从深度强化学习的角度提出了用于车道变换任务的训练、测试和评估管道。首先,我们为训练和测试设计车道变换场景,其中测试场景包括随机和确定性部分。然后,我们部署了一组由学习和非学习方法组成的基准。我们在设计的训练场景中训练了几种最先进的深度强化学习方法,并在测试场景中提供了训练模型的基准指标评估结果。设计的换道场景和基准均开放,为换道任务提供一致的实验环境。
关键词:自动驾驶、强化学习、变道场景
1. LANE CHANGE SCENARIOS(变道场景)
我们使用 CARLA模拟器,它由一个可扩展的客户端-服务器架构组成。服务器负责模拟本身:传感器渲染、物理计算、世界状态及其参与者的更新等。客户端由一系列模块组成,这些模块控制逻辑并设置演员的世界条件(演员是任何场景中的模拟世界中的实体,例如车辆、传感器、交通灯等)。
1.1训练场景
动态训练场景由随机交通流构建,借助 CARLA 模拟器 0.9.9 版中的交通管理工具实现。我们首先构建一个三车道高速公路的地图,该地图可以导入到 CARLA,并选择一个部分用于训练场景生成。对于训练,算法控制的车辆称为自我车辆,其他车辆称为社会车辆。
由于训练场景中周围社会车辆的数量、位置和速度是随机的,并且会出现意想不到的变道行为,因此可以概括出一系列具有挑战性的实例。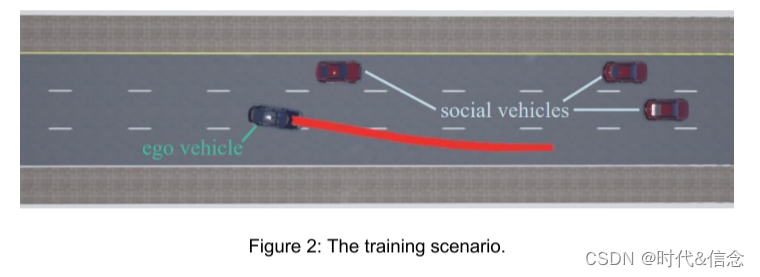
1.2测试场景
1.2.1随机测试
对于随机测试场景,其设置类似于训练场景。对于测试场景,如果周围车辆密度高,则自我车辆几乎无法变道。这样的测试场景意义不大。因此,将在自我车辆周围随机生成 4 到 9 辆社交车辆。同时,社交车辆不受随机变道的限制,将保持在初始车道上。
1.2.2确定性测试
我们参考组标准进行确定性测试场景设计。我们设计了5大变道测试逻辑场景,通过参数实例化得到400多个具体测试场景。对于确定性测试,变道算法控制的车辆称为测试车辆,其他环境车辆称为目标车辆。在训练场景中训练的变道模型在测试场景中使用统计指标进行测试。
设计的变道逻辑场景的演示如图 3 所示。测试车辆 (TV) 以目标速度 𝑉 在直线道路上行驶。虚线表示可以更改的车道,实线表示不能更改的车道,车道宽度为𝑋0。图 3 中的 𝑑 和 𝐷 表示 TV 和目标车辆 𝐺𝑉 之间的距离。
这里我们以子图 为例来解释图 3 中的参数。对于 ,目标车辆 𝐺𝑉1 沿车道中心线以 𝑉1 的速度行驶,放置在 TV 前面,两者之间的纵向距离TV和𝐺𝑉1 是𝐷。 TV 左侧的相邻车道放置一辆目标车辆𝐺𝑉2 沿车道中心线以速度𝑉2 行驶,TV 和𝐺𝑉2 之间的纵向距离为𝑑。这些测试场景提供了一系列不同的示例来测试TV代理的智能。例如,(c)是一个三车道场景,左侧车道有车辆,右侧车道没有车辆,TV需要决定换道的方式。 (e) 是双车道场景,TV需要对突然出现的静止车辆做出及时反应。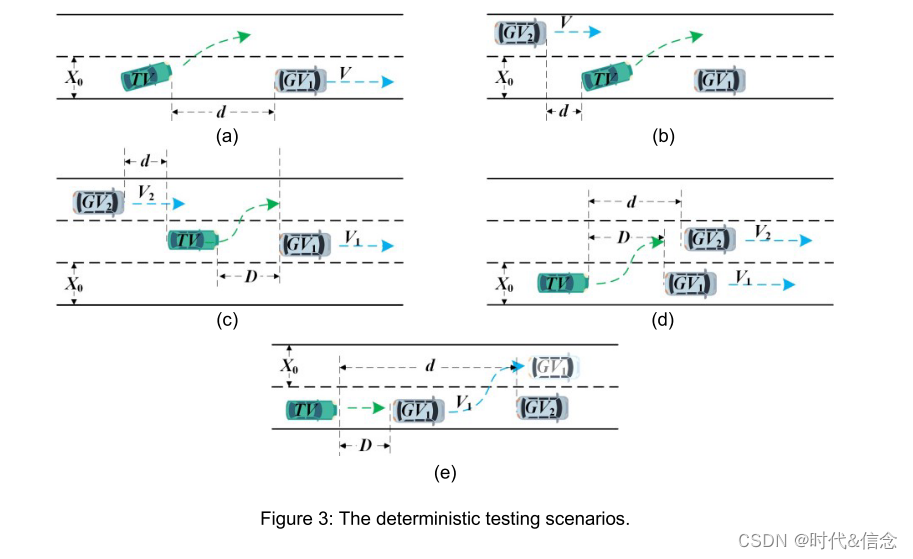
2.强化学习公式
将自我车辆感知范围的鸟瞰图像作为算法的输入,算法的输出是高级换道命令。基于图像的车道变更决策任务被建模为马尔可夫决策过程(MDP)。 MDP 是以下形式的元组:*𝑆,𝐴,𝑃,𝑅*,其中𝑆 是状态的有限集,𝐴 是动作的有限集,𝑃 动态转换模型𝑃(𝑠𝑡+1 = 𝑠′|𝑠𝑡 = 𝑠, 𝑎𝑡 = 𝑎) 对于每个动作,𝑅 奖励函数 𝑅(𝑠𝑡 = 𝑠, 𝑎𝑡 = 𝑎) = 𝔼(𝑟𝑡|𝑠𝑡 = 𝑠, 𝑎𝑡 = 𝑎, 𝑾] 折扣因子.状态转换模型𝑃和奖励𝑅受特定行为𝑎的影响。 RL 的目标是学习最大化累积奖励的策略 𝜋∗(𝑎|𝑠) 𝐽𝜋 = argmax𝜋𝔼 ∑𝑡 𝛾𝑡−1𝑟𝑡。考虑一个环境𝐸,其中代理通过一组状态、动作和奖励与其交互。在本文中,状态、动作空间和奖励函数设置如下。
2.1 State
状态输入是大小为 64×64 的三通道 RGB 图像,对应于自我车辆前方 50 m 和后方 25 m 范围内的架空交通流。自我车辆是蓝色的;社会车辆是绿色的;车道线是红色的;马路两边各有一条单车道宽的人行道,满是灰色。自我车辆在图像中的位置是相对固定的。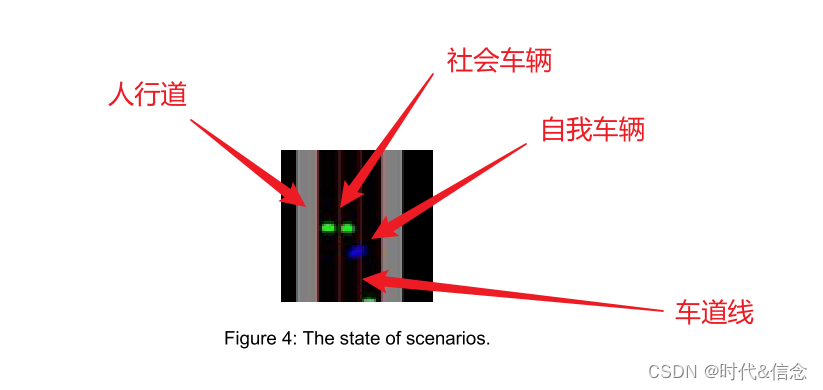
2.2 Action
DRL 算法的输出是一个横向变道命令,对应一个离散的动作空间集为{ 保持当前车道,向左改变车道,向右改变车道}。
2.3 Reward
定义了正奖励𝑟𝑣 = 0.2 ⋅ 𝑣/𝑣𝑇,其中𝑣 是自我速度,𝑣𝑇 = 60 km/h 是自我车辆的期望速度。另一方面,当发生变道时,将给代理一个负奖励𝑟𝑙 = -1.0,此时将不再应用速度奖励。安全主要体现在不会发生碰撞,如果在决策周期内发生本车与其他车辆的碰撞,将在上述奖励的基础上给予-1.0的惩罚,并且碰撞奖励定义为𝑟𝑐。总之,总奖励函数定义为
3.BASELINE
非学习方法 MOBIL(最小化由车道变化引起的整体制动)
D3QN(Dueling Double DQN)
PPO (近端策略优化)
A2C(Advantage Actor-Critic)
4. 评估指标
许多指标可用于衡量代理的行为。对于自动驾驶系统而言,安全性和效率是最受关注的性能指标。
对于随机测试场景,定义的指标包括𝑆𝑎𝑓𝑒𝑡𝑦𝑅𝑎𝑡𝑒,即所有不碰撞的情节的百分比,以及𝐴𝑣𝑔_𝑣,𝐴𝑣𝑔_𝑙𝑐,𝐴𝑣𝑔_𝑚𝑎𝑥𝑎𝑐𝑐,𝐴𝑣𝑔_𝑡和𝐴𝑣𝑔_𝑙𝑒𝑛,分别指的是:平均速度,平均换道次数,平均最大加速度,成功运行的平均episode时间和所有测试episode平均通过距离。
对于确定性测试方案,我们使用车道更改安全率𝑆𝑎𝑓𝑒𝑡𝑦𝑅𝑎𝑡𝑒,车道更改成功率𝑆𝑢𝑐𝑐𝑒𝑠𝑠𝑅𝑎𝑡𝑒和平均最大加速度𝐴𝑣𝑔_𝑚𝑎𝑥𝑎𝑐𝑐作为指标来评估测试剂的性能。
变道安全率是安全变道场景𝑆𝑎𝑓𝑒𝐶𝑜𝑢𝑛𝑡相对于所有场景测试实例𝑇𝑜𝑡𝑎𝑙𝐶𝑜𝑢𝑛𝑡的百分比: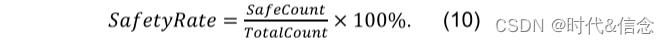
变道成功率是成功变道场景𝑆𝑢𝑐𝑐𝑒𝑠𝑠𝐶𝑜𝑢𝑛𝑡占所有场景测试实例数量𝑇𝑜𝑡𝑎𝑙𝐶𝑜𝑢𝑛𝑡的百分比: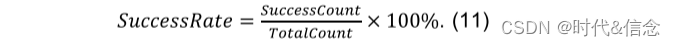
平均最大加速度是所有场景下被测车辆最大加速度的平均值。
5. 模拟实验
5.1 Training
训练场景任务中 RL 基线的学习曲线如图 5 所示。表明 A2C 和 PPO 比 D3QN 具有更快的学习效率,但在训练场景中,这三者的最终学习性能相似。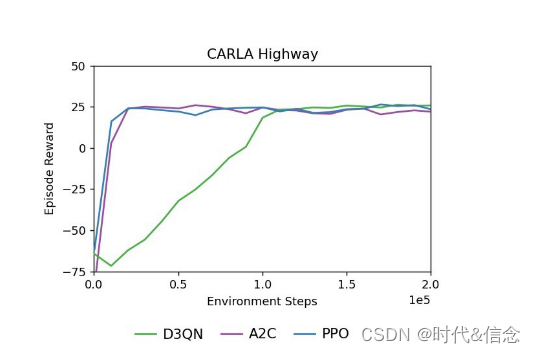
5.2 Testing
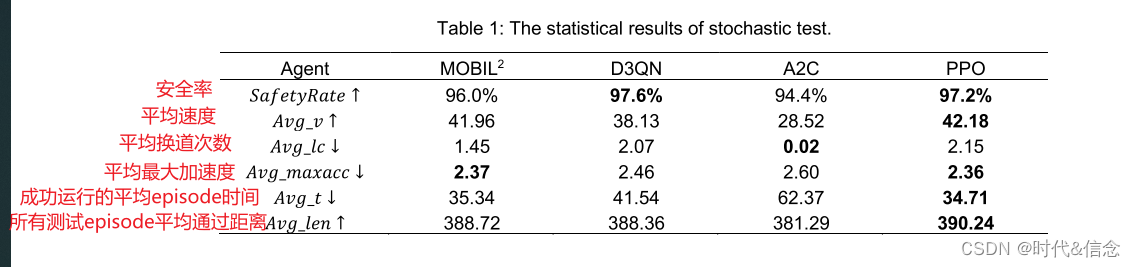
从表1可以看出,在随机测试场景下,A2C代理几乎不能换道,而D3QN和PPO代理具有一定的换道能力。 D3QN 在几种方法中实现了最好的安全性,但其效率低于 MOBIL。值得注意的是,虽然 PPO 方法的换道次数略多,但在所有其他指标上都超过了 MOBIL,显示了基于 DRL 的方法的能力。
episode的解释:
从表 2 和表 3 可以看出,PPO 代理在确定性测试场景中的表现还是比较好的,达到了与 MOBIL 相当的性能。综合所有测试结果,PPO 方法在我们的设置下表现最好,而非学习方法 MOBIL 提供了强大的基线。 A2C 方法没有学习到好的变道行为,而 D3QN 表现相对平庸。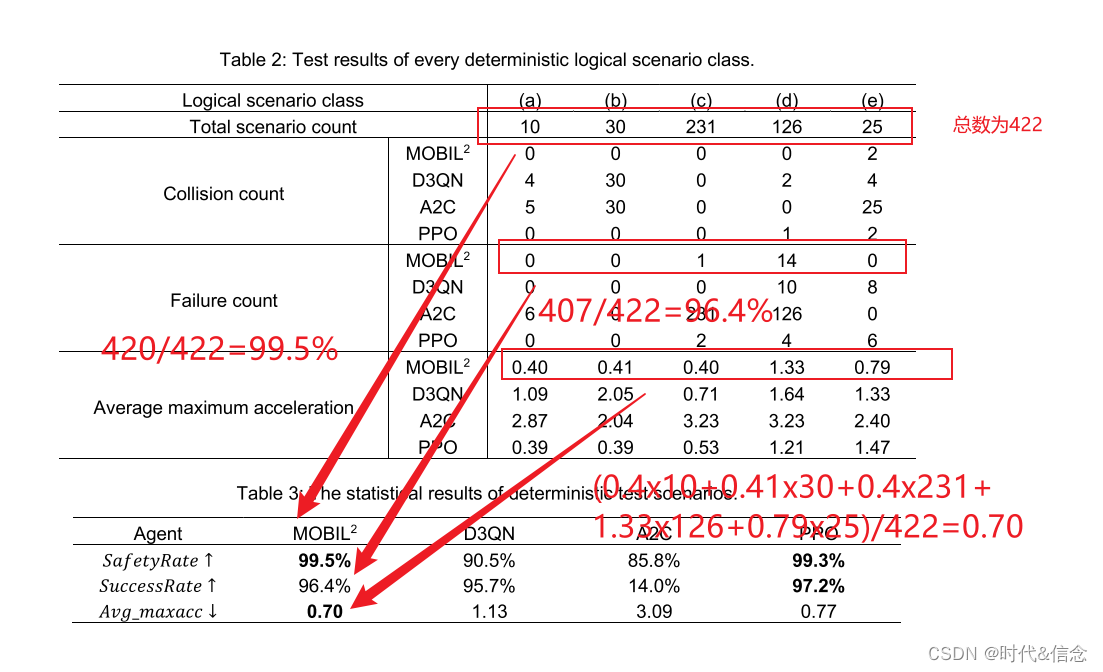
结论
在本文中,我们提出了一种用于变道场景的训练、测试和评估流程。在我们对强化学习问题的形式化下,我们构建了训练场景来训练几个最先进的强化学习代理,即 D3QN、A2C 和 PPO。此外,我们实现了非学习变道方法 MOBIL 作为比较基线。此外,我们构建测试场景来评估学习模型并在评估指标下提供基准结果。
边栏推荐
- Protobuf Grpc使用异常 类型有未导出的方法,并且是在不同的软件包中定义
- 金鱼哥RHCA回忆录:CL210管理计算资源--管理计算节点+章节实验
- 数据驱动的软件智能化开发| ChinaOSC
- 阿里巴巴政委体系-第六章、阿里政委体系运作
- 云图说丨初识华为云微服务引擎CSE
- if/else或switch替换为Enum
- Unity获取canvas 下ui 在屏幕中的实际坐标
- mysql跨库关联查询(dblink)
- 丙二醇二乙酸酯(Propylene Glycol Diacetate)
- Teach you to locate online MySQL slow query problem hand by hand, package teaching package meeting
猜你喜欢

Reveal how the five operational management level of hundreds of millions of easily flow system

高效目标检测:动态候选较大程度提升检测精度(附论文下载)

线上一次JVM FullGC搞得整晚都没睡,彻底崩溃

阿里巴巴政委体系-第五章、阿里政委体系建设
MySQL 主从,6 分钟带你掌握!
开发即时通讯到底需要什么样的技术,需要多久的时间
ECCV 2022 Oral | 满分论文!视频实例分割新SOTA: IDOL
Interview Blitz: What Are Sticky Packs and Half Packs?How to deal with it?
LeetCode 622. 设计循环队列
MySQL详细学习教程(建议收藏)
随机推荐
力扣刷题之爬楼梯(7/30)
The effective square of the test (one question of the day 7/29)
面试突击:什么是粘包和半包?怎么解决?
【微信小程序】NFC 标签打开小程序
net-snmp私有mib动态加载到snmpd
ADS 2023 Download Link
Word另存为PDF后无导航栏解决办法
【leetcode】剑指 Offer II 009. 乘积小于 K 的子数组(滑动窗口、双指针)
ScrollView嵌套RV,滑动有阻力不顺滑怎么办?
ctfshow php features
阿里巴巴政委体系-第七章、阿里政委培育
傅里叶变换(深入浅出)
ERROR: You don‘t have the SNMP perl module installed.
Unity获取canvas 下ui 在屏幕中的实际坐标
Postgresql源码(64)查询执行——子模块Executor(2)执行前的数据结构和执行过程
怎么将自己新文章自动推送给自己的粉丝(巨简单,学不会来打我)
CS免杀姿势
Introduction to Cosine Distance
力扣刷题之合并两个有序数组
不要再用if-else