当前位置:网站首页>Spark RDD case: Statistics of daily new users
Spark RDD case: Statistics of daily new users
2022-06-29 07:16:00 【Yushijuj】
List of articles
One 、 Put forward a task
The following users have access to historical data , The first column is the date when the user visited the website , The second column is the user name :
2022-02-07,Mike
2022-02-07,Alice
2022-02-27,Brown
2022-04-02,Mike
2022-04-02,Alice
2022-04-02,Green
2022-07-12,Alice
2022-07-12,Smith
2022-07-12,Brian

Count the number of new users every day through the above data , The following statistical results are obtained :
2022-02-07 Added 3 Users ( Respectively mike、alice、brown)
2022-04-02 Added 1 Users (green)
2022-07-12 Added 2 Users ( Respectively smith、brian)
Two 、 Realize the idea
Use inverted indexing , If the same user corresponds to multiple access dates , The minimum date is the registration date of the user , I.e. new date , Other dates are repeat visit dates , Should not be counted . Therefore, each user should only calculate the minimum date of user access . As shown in the figure below , Move the minimum date each user accesses to the first column , The first column is valid data , Only the occurrence times of each date in the first column are counted , That is, the number of new users on the corresponding date .

- Start the cluster HDFS And Spark

- stay HDFS Prepare data on - users.txt
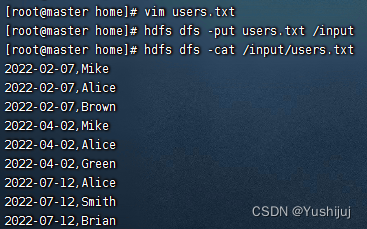
3、 ... and 、 To complete the task
( One ) Read the file , obtain RDD
val rdd1 = sc.textFile("hdfs://master:9000/input/users.txt")

( Two ) inverted , swap RDD The element order of the middle element group
val rdd2 = rdd1.map(
line => {
val fields = line.split(",")
(fields(1), fields(0))
}
)

( 3、 ... and ) Inverted RDD Key grouping
val rdd3 = rdd2.groupByKey()

( Four ) Get the minimum value of the grouped date set , Count as 1
val rdd4 = rdd3.map(line => (line._2.min, 1))

( 5、 ... and ) Key count , Get the number of new users per day
val result = rdd4.countByKey()
result.keys.foreach(key => println(key + "," + result(key)))

Four 、 To complete the task
( One ) newly build Maven project – CountNewUsers


take JAVA Directory changed to scala

( Two ) Add related dependencies and build plug-ins
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.cb.rdd</groupId>
<artifactId>CountNewUsers</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.3.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- And refresh the download dependency

( 3、 ... and ) Create log properties file
- Create a log attribute file in the resource folder - log4j.properties
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spark.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n

( Four ) Create a single instance object for calculating the average score
- stay net.cb.sql Create in package CountNewUsersBySQL Singleton object
package net.cb.rdd
import org.apache.spark.{
SparkConf, SparkContext}
/** * function : Statistics of daily new users * author : Chen Biao * Time : 2022 year 06 month 18 Japan */
object CountNewUsersBySQL {
def main(args: Array[String]): Unit = {
// establish Spark conf Containers
val spark: SparkConf = new SparkConf()
.setAppName("CalculusAverageByRDD")
.setMaster("local[*]")
val sc: SparkContext = new SparkContext(spark)
val lines = sc.textFile("hdfs://master:9000/input/users.txt")
//lines.collect.foreach(println)
// swap RDD The order of elements in
val value = lines.map(
line =>{
val fields = line.split(",")
val name = fields(1)
val time = fields(0)
(name,time)
}
)
// Group names
val nameGB = value.groupByKey().map(
line => {
val time = line._2.min
val name = line._1
(time,name)
}
)
// Key count , Get daily additions
val CB = nameGB.countByKey()
CB.keys.foreach(key => println(key + "," + CB(key)))
// Closed container
sc.stop()
}
}
( 5、 ... and ) Local running program , View results

边栏推荐
- Qt 串口编程
- 你真的懂 “Binder 一次拷贝吗“?
- Twitter launches the test of anti abuse tool "safe mode" and adds enabling prompt
- 通过keyup监听textarea输入更改按钮样式
- 2022.6.27-----leetcode. five hundred and twenty-two
- Idea integrated code cloud
- YGG pilipinas: typhoon Odette disaster relief work update
- QT STL type iterator
- Using IPv6 to access remote desktop through public network
- Markdown 技能树(7):分隔线及引用
猜你喜欢

国内代码托管中心- 码云

利用IPv6實現公網訪問遠程桌面
![[when OSPF introduces direct connection routes, it makes a summary by using static black hole routes]](/img/a8/f77cc5e43e1885171e73f8ab543ee4.png)
[when OSPF introduces direct connection routes, it makes a summary by using static black hole routes]

RPC和RMI

消息队列之通过队列批处理退款订单
把多个ROC曲线画在一张图上

【软件测试】接口——基本测试流程
YGG pilipinas: typhoon Odette disaster relief work update

Relevance - correlation analysis

Mongostat performance analysis
随机推荐
What are the conditions for a high-quality public chain?
VerilogA - counter
Using IPv6 to access remote desktop through public network
NoSQL数据库之Redis(一):安装 & 简介
Idea use
软件工程师与软件开发区别? Software Engineer和Software Developer区别?
UVM authentication platform
数字ic设计——UART
你真的懂 “Binder 一次拷贝吗“?
Some thoughts on port forwarding program
Common status codes for page error reporting
Utilisation d'IPv6 pour réaliser l'accès public au bureau distant
Method of changing host name (permanent)
【翻译】e-Cloud。使用KubeEdge的大规模CDN
利用IPv6实现公网访问远程桌面
Summary of some new datasets proposed by cvpr2021
Markdown 技能树(1):MarkDown介绍
LiveData源码赏析 —— 基本使用
[answer all questions] CSDN question and answer function evaluation
Tree drop-down selection box El select combined with El tree effect demo (sorting)