当前位置:网站首页>计算机视觉(AI)面试大全
计算机视觉(AI)面试大全
2022-06-11 02:50:00 【大黑山修道】
目标检测算法
1. 单阶段和二阶段目标检测算法的区别?以yolo和RCNN为例
单阶段:速度快但精度较低;
二阶段: 精度高而速度较慢;
单阶段one-stage:
one-stage算法会直接在网络中提取特征来预测物体的特征和位置,一步到位。代表作:YOLO,SSD。
二阶段two-stage:
第一阶段:专注于找出目标物体出现的位置,得到建议框,保证足够的准确率和召回率;
第二阶段:专注于对建议框进行分类,寻找更精确的位置
代表作:R-CNN,Fast R-CNN ,Faster R-CNN。
one-stage代表 yolo算法
yolo 创造性的将物体检测任务当作回归问题(regression problem), 将候选区和检测两个阶段合二为一。
yolov1:
本文将检测变为回归问题,yolo从输入图像,仅仅通过一个 neural network, 直接得到检测框和每个检测框所属的类别的概率。正因为整个过程仅仅一个网络,所以可以直接进行端到端的优化。
Loss 损失函数
1. 对 focal loss的了解
正负样本不平衡带来的问题:
样本中存在大量负样本的简单样本,这样会让大量的简单负样本对loss起主要贡献,主导梯度的更新方向,网络无法对object进行精确分类。
Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘。
1.1 首先面对正负样本不平衡的问题,为交叉熵增加一个权重alpha,用来平衡正负样本本事的比例不均,负样本越多比例越少;
原来:
修改为:
1.2 针对简单负样本和复杂负样本不平衡的问题,增加gamma因子,其中gamma>0使得减少简单样本的损失,使损失更关注于使得更关注于困难的、错分的样本。(因为简单样本比例很大,假设为0.9,那么1-0.9的值就会很小,导致最后对损失的影响也很小,这样还可以放大困难样本的影响)
定义损失函数: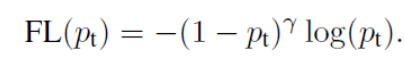
最终,focal loss的形式为: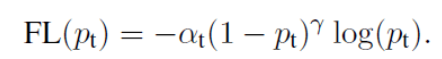
2.目标检测的损失函数有哪些?
目标检测中的损失函数通常由两部分组成:classification loss (分类损失)和 bounding box regression loss(定位损失)。
classification loss (分类损失)
2.1.1 交叉熵

交叉熵损失函数通过不断缩小两个分布的差异,使预测结果更可靠。
谷歌在交叉熵的基础上提出了Label Smoothing(标签平滑),解决over-confidence的问题。
Label Smoothing其实就是将原来的label取值范围从[0,1]改为 [ε,1-ε]
2.1.2 focal loss
主要是为了解决one-stage目标检测算法中正负样本比例严重失衡的问题,降低了大量简单负样本在训练中所占的比重。
focal loss的形式为:
首先面对正负样本不平衡的问题,为交叉熵增加一个权重alpha,用来平衡正负样本本事的比例不均,负样本越多比例越少;
针对简单负样本和复杂负样本不平衡的问题,增加gamma因子,其中gamma>0使得减少简单样本的损失,使损失更关注于使得更关注于困难的、错分的样本。(因为简单样本比例很大,假设为0.9,那么1-0.9的值就会很小,导致最后对损失的影响也很小,这样还可以放大困难样本的影响);
2.2.1目标定位损失—IoU
衡量目标检测定位性能的主要指标是交并比IoU。以往在设计损失函数时通常使用mse等损失函数来优化模型对目标的定位结果,但是不能很好地反应定位精度;
直接使用Iou衡量目标定位损失函数:
优点:尺度不变性
存在问题:相同的IOU不能代表检测框的定位效果相同;当两个框没有相交,则IOU=0不能反应两个框的距离,此时损失函数不存在梯度,无法通过梯度下降进行训练
2.2.2 目标定位损失—GIoU
GIOU的提出:

IoU反映了两个框的重叠程度,在两个框不重叠时,IoU衡等于0,此时IoU loss恒等于1。而在目标检测的边界框回归中,这显然是不合适的。因此,GIoU loss在IoU loss的基础上考虑了两个框没有重叠区域时产生的损失。具体定义如下:
其中,C表示两个框的最小包围矩形框,R(P,G)是惩罚项。从公式可以看出,当两个框没有重叠区域时,IoU为0,但R依然会产生损失。极限情况下,当两个框距离无穷远时,R→1
I o U = ∣ A ∩ B ∣ ∣ A ∪ B ∣ IoU=\frac{|A\cap B|}{|A\cup B|} IoU=∣A∪B∣∣A∩B∣
G I o U = I o U − ∣ C \ ( A ∪ B ) ∣ ∣ C ∣ GIoU=IoU-\frac{|C\backslash(A\cup B)|}{|C|} GIoU=IoU−∣C∣∣C\(A∪B)∣
GIOU的优势:
1.首先可以实现较全场景以类IoU Loss为目标直接优化,使得优化目标和最终的评估目标一致。由于IoU Loss的关键问题在于当两个物体没有交集的时候,它就退化为常数1,失去优化目标
2.相比于传统的回归loss,它具备尺度不变形
3.极限情况下,GIoU(A,B) = IoU(A, B)
2.2.3 DIoU Loss
IoU loss和GIoU loss都只考虑了两个框的重叠程度,但在重叠程度相同的情况下,我们其实更希望两个框能挨得足够近,即框的中心要尽量靠近。因此,DIoU在IoU loss的基础上考虑了两个框的中心点距离,具体定义如下:
其中,ρ表示预测框和标注框中心端的距离,p和g是两个框的中心点。c表示两个框的最小包围矩形框的对角线长度。当两个框距离无限远时,中心点距离和外接矩形框对角线长度无限逼近,R→1
下图直观显示了不同情况下的IoU loss、GIoU loss和DIoU loss结果:
其中,绿色框表示标注框,红色框表示预测框,可以看出,最后一组的结果由于两个框中心点重合,检测效果要由于前面两组。IoU loss和GIoU loss的结果均为0.75,并不能区分三种情况,而DIoU loss则对三种情况做了很好的区分。
2.2.4 CIoU Loss
DIoU loss考虑了两个框中心点的距离,而CIoU loss在DIoU loss的基础上做了更详细的度量,具体包括:
重叠面积
中心点距离
长宽比
因此,进一步在DIoU的基础上提出了CIoU。其惩罚项如下面公式:
其中 ɑ 是权重函数:
而 v 用来度量长宽比的相似性,定义为:
2.2.5 L1(MAE)
L1损失函数:
L1损失函数对x的导数为常数,不会有梯度爆炸的问题,但其在0处不可导,在较小损失值时,得到的梯度也相对较大,可能造成模型震荡不利于收敛。
2.2.6 L2(MSE)
L2损失函数:

L2损失函数处处可导,但由于采用平方运算,当预测值和真实值的差值大于1时,会放大误差。尤其当函数的输入值距离中心值较远的时候,使用梯度下降法求解的时候梯度很大,可能造成梯度爆炸。同时当有多个离群点时,这些点可能占据Loss的主要部分,需要牺牲很多有效的样本去补偿它,所以L2 loss受离群点的影响较大。
2.2.7 smooth L1损失函数

smooth L1完美的避开了L1和L2损失的缺点:
在[-1,1]之间就是L2损失,解决L1在0处有折点
在[-1, 1]区间以外就是L1损失,解决离群点梯度爆炸问题
当预测值与真实值误差过大时,梯度值不至于过大
当预测值与真实值误差很小时,梯度值足够小
上述三个损失函数(L1(MAE),L2(MSE),smooth L1损失函数)在计算bounding box regression loss时,是独立的求4个点的loss,然后相加得到最终的损失值,这种做法的前提是四个点是相互独立的,而实际上是有一定相关性的
实际评价检测结果好坏的指标是IoU,这两者是不等价的,多个检测框可能有相同的loss,但IoU差异很大。
训练策略
1. 训练过程中类别不平衡怎么办?怎么解决的?
1. 从采样的策略上: 通过采样方法将不平衡的数据集变为平衡的数据集,优点是简单方便。具体分为过采样和欠采样。
过采样 :将小份的样本复制多份。
这样可能会造成训练出的模型有一定过拟合。
欠采样:将大份的样本中筛选一部分作为数据集,等于丢弃部分训练集的数据,也可能会造成过拟合。
可以采用3个方法减少欠采样带来的损失。
1.1 EasyEnsemble :利用模型融合的方法,多次欠采样产生多个数据集,从而训练多个模型,综合多个模型的结果作为最终的结果
1.2 BalanceCascade: 利用增量训练的思想,先利用欠采样产生的训练集训练一个分类器,然后对分类正确的样本从总训练集中筛除,再次在剩余的数据集利用欠采样训练第二个分类器,最终结合所有的分类器结果作为最终结果。
1.3 NearMiss:利用KNN试图挑选那些最具代表性的大众样本。
2. 图像增强:通过某种手段,利用已有的样本人工合成少数类样本,从而达到类别平衡的目的。
常规的图像增强方法有: 缩放,旋转,翻转,偏移等。
还有根据场景化定制的一些图像增强方法:增加噪声,滤波操作(模糊),调节亮度/对比度
3. 加权操作:通过加权的方式解决数据不平衡的问题,在设计损失函数时,为少数类样本赋予更大的权值,为多数类样本赋予更小的权值。
例如: focal loss
4. 调整输出阈值:当类别不平衡时,采用默认的分类阈值可能会导致输出全部为反例,产生虚高的准确度,导致分类失败。因此,可以选择调整阈值,使得模型对于较少的类别更为敏感。
2. 采集数据集时需要注意什么
2.1 注意避免正负样本不均衡
2.2 注意在多个类之间保持一个数量均衡
2.3 场景多样性:尽可能采集需求范围内各种场景下的数据
例如:检测器是在户外进行检测的,则采集的数据尽可能的包含白天,晚上,雨天,晴天等场景;
2.4 目标多样性:尽可能收集需求范围内各种状态下的目标
2.4 采集数据的设备尽量与后期检测的设备,或者图像输入尺寸保持一致,要避免差异过大;
2.5 把握标注质量,在最后对数据集的人工标注能有一个严格的质量把关;
2.6 条件困难的情况下,可以采用互联网的数据集加上现场人工采集的数据集进行一定组合再进行训练,可以减少人工成本;
参考博客:
https://blog.csdn.net/weixin_41665360/article/details/100126744
https://blog.csdn.net/weixin_43750248/article/details/116656242
https://blog.csdn.net/a264672/article/details/122952162
边栏推荐
- Rs232/rs485 to 4G DTU uploading temperature and humidity sensor data based on Modbus protocol to remote TCP server
- 出栈序列是否是入栈序列
- 怎样确保消息的可靠性投递?
- C语言数组的简单认识
- RS232/RS485转4G DTU 上传基于Modbus协议的温湿度传感器数据到远程TCP服务器
- Forest v1.5.22 release! Kotlin support
- Chapter VII introduction to common protocols (1)
- Log4j:error category option "1" not a decimal integer
- com. mchange. v2.c3p0. Combopooleddatasource red
- 关于玩家身上有个普通Set并发安全的讨论
猜你喜欢

重磅直播!ORB-SLAM3系列之特征匹配(MLPnP、词袋模型等)。
马志强:语音识别技术研究进展和应用落地分享丨RTC Dev Meetup
Explication du cours de graphacademy: neo4j Graph Data Science Foundation

Visit the swagger times unable to infer base url

VMware virtual machine IP, gateway settings. The virtual machine cannot be pinged to the Internet

ASLR

WinDbg virtual machine dual machine debugging driver file debugging

File compositor

新来的同事问我 where 1=1 是什么意思???

How to handle error code 30204-44 when installing office 2016 in win10?
随机推荐
数据库唯一索引和普通索引的区别?
B / Qurt Utilisateur Guide (19)
WinDbg virtual machine dual machine debugging driver file debugging
UBIFS FAQ and HOWTO
Stringutils string tool class used by FreeMarker to create templates
postgresql源码学习(22)—— 故障恢复③-事务日志的注册
Determine whether a string of numbers is the result of a quick sort
Go quick start of go language (I): the first go program
GraphAcademy 课程讲解:《Neo4j 图数据科学基础》
Will your company choose to develop data center?
VMware虚拟机IP,网关设置。虚拟机ping不通外网
Forest v1.5.22 release! Kotlin support
If you understand the logic of mining and carbon neutrality, you will understand the 100 billion market of driverless mining areas
怎样确保消息的可靠性投递?
Pyqt5:qlineedit control code
怎样简洁明了地说清楚产品需求?
Construction of Flink development environment and wordcount
Basic use of sonarqube platform
B_QuRT_User_Guide(19)
CPT 102_ LEC 13-14