当前位置:网站首页>Surrounddepth: self supervised multi camera look around depth estimation
Surrounddepth: self supervised multi camera look around depth estimation
2022-06-11 10:56:00 【3D vision workshop】
Click on the above “3D Visual workshop ”, choice “ Star standard ”
The dry goods arrive at the first time

Author Huang Yu
Source computer vision deep learning and automatic driving
arXiv The paper “SurroundDepth: Entangling Surrounding Views for Self-Supervised Multi-Camera Depth Estimation“, Upload on 2022 year 4 month , From Tsinghua 、 Tiandahe Jianzhi robot startup company .

Estimating depth from an image is autopilot 3D The basic steps of perception , It's an expensive depth sensor ( Like lidar ) Economic alternatives to . Temporal photometric consistency (photometric consistency) It can realize dimensionless self supervised depth estimation , Further promote its wide application . However , Most of the existing methods only predict the depth based on each monocular image , The correlation between multiple surrounding cameras is ignored , This usually applies to modern autonomous vehicles .
This paper puts forward a kind of SurroundDepth Method , Combine information from multiple surrounding views , Predict the depth map between cameras . Specifically, a federated network is used to handle all the surrounding views , And propose a cross view transformer To effectively fuse information from multiple views . Cross view self attention is used to effectively realize the global interaction between multi camera feature images . Different from self supervised monocular depth estimation , It can predict the scale of the real world given the external parameters of multiple cameras . In order to achieve this goal , Exercise restores structure (SfM) Extraction scale - The pseudo depth of awareness is used to pre train the model . Besides , The self motion of each individual camera is not predicted , Instead, it estimates the general self motion of the vehicle , And transfer it to each view , To achieve multi view consistency . In the experiment , This method is applied to challenging multi camera depth estimation data sets DDAD and nuScenes The latest performance has been achieved on .
Code is located https://github.com/weiyithu/SurroundDepth
Camera 3D Perception because of its semantic richness and economy , Has become a promising potential alternative . Depth estimation as input 2D Image and reality 3D A bridge between environments , To the downstream 3D Understanding has a crucial impact , And received more and more attention .
Due to the high cost of intensively marking depth maps , Depth estimation is usually learned in a self supervised way . By simultaneously predicting the depth map and the self motion of the camera , The existing methods use the time-domain photometric consistency between continuous images as the monitoring signal . Although modern autonomous vehicle are usually equipped with multiple cameras to capture the surrounding scenes 360 Panoramic view of , Most existing methods still focus on predicting depth maps from monocular images , The correlation between the surrounding views is ignored . Because the relative scale can only be inferred from the time domain photometric consistency , These self supervised monocular depth estimation methods can not produce scale - The depth of awareness . However , The scale of the real world is obtained by the translation vector in the multi camera external parameter matrix , So it is possible to obtain the scale - Aware of predictions .
The self supervised monocular depth estimation method explores both the learning depth and the movement route . For monocular sequences , Geometric constraints are usually established on adjacent frames . The earliest is to build this problem as a view composition task , The two networks are trained to predict posture and depth respectively . It was also suggested that ICP Loss , Its work demonstrates the use of the entire 3D Effectiveness of structural consistency .Monodepth2 Use minimum re projection loss 、 Full resolution multiscale sampling and auto-masking Loss , Further improve the prediction quality . There is also a scale inconsistency (scale consistency ) Loss term to solve the problem of scale inconsistency between depth maps .PackNet SfM By introducing 3D Convolution further improves the accuracy of depth estimation . lately ,FSM Enrich the monitoring signal by introducing spatial and temporal context , The self - supervised monocular depth estimation is extended to all - around view .
Multi view feature interaction is multi view stereo vision 、 A key component in object detection and segmentation .MVSNet Construct a variance based cost volume with multi view features (variance-based cost volume), And use 3D CNN Do the cost regularization regression depth value . There is also the introduction of adaptive aggregation and LSTM To further improve performance . lately ,CVP-MVSNet The pyramid structure is used to iteratively optimize the depth prediction .STTR A method with alternating self attention and cross attention is adopted transformer To replace the cost body .LoFTR stay transformer Using self - attention and cross - attention layers , Get the feature descriptor of two images .Point MVSNet combination 2D Image appearance clues and geometric prior knowledge , Dynamic fusion of multi view image features . Besides ,PVNet Integrate 3D Point features and multi view features , To better identify the association 3D shape .
Additional supervisory signals for depth estimation , It can enhance the accuracy of depth estimation , Such as optical flow and target motion .DispNet It is the first work to transfer the information of synthetic stereo video data set to real-world depth estimation . Besides , A dual modular domain adaptive network with generative loss resistance is used (two-module domain adaptive network), Migrate knowledge from the composite domain . Some methods use auxiliary depth sensors to capture accurate depth , Like lidar , To assist in depth estimation . Besides , Some methods introduce surface normals to help predict depth , Because the depth is constrained by the local tangent plane determined by the surface normal .GeoNet Proposed depth to normal (depth-to-normal) Net and normal to depth (normal-to-depth) The Internet , Forcing final predictions to follow geometric constraints . Besides , A lot of work has introduced traditional methods ( Such as SfM), Produce some sparse but high-quality depth values , To assist model training .DepthHints Some ready-made stereo vision algorithms are used to enhance stereo vision matching .
The figure shows the traditional monocular depth estimation method and SurroundDepth Comparison :

In the self-monitoring depth and self motion settings , Optimize the depth network by minimizing pixel photometric re projection losses F, These include SSIM Measure and L1 Loss item :
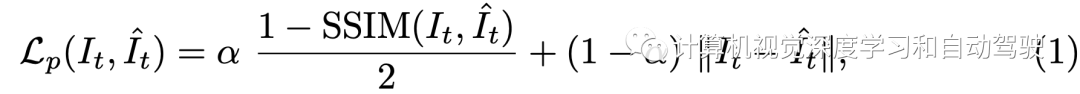
This process requires a posture network G To predict the It-》Is Relative posture of . To be specific , Given camera intrinsic matrix K, Based on the predicted depth map , computable It Any pixel in the p1 stay Is The corresponding projection of p2. such , According to the projection coordinates p2 Can be in Is Use bilinear interpolation to create a composite RGB Images . This reconstruction based self-monitoring paradigm has made great progress in monocular depth estimation , And it can be directly extended to multi camera full look depth estimation .I The predicted depth map and pose of can be written as :
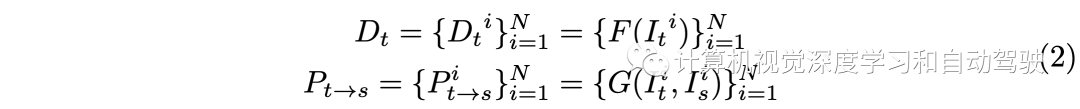
The overlap between adjacent views connects all views into a complete 360 Degree environment view , It contains a lot of useful knowledge and prior knowledge , It helps to understand the whole scene . Based on this fact , Build a joint model , First, extract and exchange the representations of all surrounding views . After the cross view interaction , Map the multi view representation to the final depth at the same time . Besides , View dependent self motion can be derived from the predicted common pose (universal pose) And the known external matrix . All in all , The depth and attitude predictions can be expressed as :

Using the joint model , It can not only improve the depth estimation performance of all views through cross view information interaction , It can also generate a common self motion , Thus, the scale is generated by using the external parameter matrix of the camera - Aware of predictions .
As shown in the figure SurroundDepth Network Overview : The Internet F It can be divided into three parts , namely , Shared encoder E、 Shared decoder D And multiple cross views Transformer(CVT). Given a set of periscopic images , Firstly, the encoder network extracts its multi-scale representation in parallel . It is different from the existing methods of directly decoding learning features , It entangles the features of all views into a complete feature on each scale , And further use of multi-scale specific CVT, Perform cross view self attention on all scales .

CVT Use powerful attention mechanisms , Enable each element of the feature map to propagate its information to other locations , While absorbing information from other locations . Last , Separate the interactive features to N Individual view , And send it to the decoder D.
Different from monocular depth estimation , This scale that can restore the real world from the camera external parameter matrix . A simple way to use these camera external parameter matrices is , Embedded in spatial photometric loss between two adjacent views . However , It is found that the depth network cannot directly learn the scale through the supervision of spatial photometric consistency . To solve this problem , The author puts forward the scale - Perceptive SfM Pre training and joint attitude estimation .
say concretely , In two frames SfM Generate pseudo depth to pre train the model . The pre training depth network can learn the scale of the real world . Besides ,N The time domain self motion of cameras has explicit geometric constraints . Consistency loss is not used here , Instead, estimate the common attitude of the vehicle , The self motion of each view is calculated according to the external parameter matrix .
As shown in the figure : This work utilizes multi-scale features extracted from all surrounding views , Replace the hop connection between encoder and decoder with a cross view transformer(CVT)

First, use separable convolution along the depth (DS Conv,depthwise separable convolution) Layers summarize multi view features into compact representations . And then build Z Cross view self attention layer , Fully swap flat multi view features . After the cross view interaction , use DS Deconv(depthwise separable deconvolution) Layer to restore the resolution of multi view features . Last , Constructed a hop connection , Combine input and restored multi view features .
SfM The purpose of pre training is to explore the scale of the real world from the camera external parameter matrix . The direct method of using the external parameter matrix is to use the spatial photometric loss between two adjacent views , namely :

But actually , It doesn't work . This conclusion is different from FSM(“Full Surround Monodepth from Multiple Cameras“,arXiv 2104.00152,2021) Got . actually , At the beginning of training , Spatial photometric loss will be invalid , And can not supervise the real scale of deep network learning . To solve this problem , use SIFT Descriptors to extract correspondence . then , Use the camera external parameter matrix to triangulate to calculate the scale - The false depth of awareness . Last , These sparse pseudo depths and temporal luminosity losses are used to pre train the depth network and attitude network .
As shown in the figure, i.e. scale - perceive SfM Preliminary training : Due to small overlap and large angle of view , Traditional two frame motion recovery structure (SfM) There will be many error correspondences . By introducing region mask( Define image Ii Left side 1/3 Area , Images Ii+1 To the right of 1/3 Area ), Narrow the search scope of corresponding relationship , Improve the retrieval quality . The epipolar geometry obtained by using the camera external parameter matrix can further filter outliers .

The epipolar line of a point here is expressed as :

In the monocular depth estimation framework , The relative camera attitude is determined by PoseNet It is estimated that ,PoseNet It's an encoder E- decoder D The Internet . therefore , In the multi camera head setup , The attitude of all photographic heads is necessary to generate supervision signals for all views . An intuitive method is to estimate each pose separately . However , This strategy ignores the posture consistency between different views , This may result in invalid supervision signals . In order to maintain the consistency of multi viewpoint self motion , The camera pose estimation problem is decomposed into two sub problems : Common attitude prediction and universal-to-local Transformation . To get a common posture P, I will N Feed the target and source images once PoseNet G, The extracted features are averaged before the decoder . The common attitude can be calculated by :

Based on camera internal parameters , Thus, the attitude of each camera is calculated as :
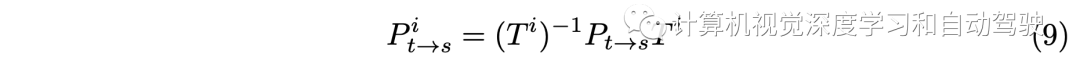
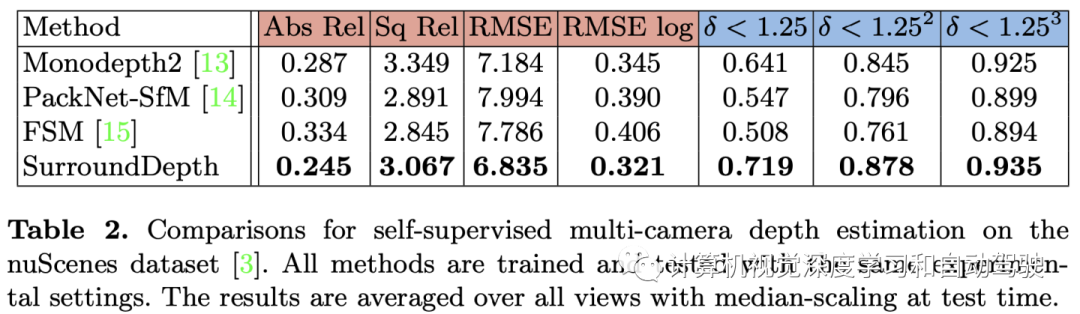
The experimental results are as follows :



This article is only for academic sharing , If there is any infringement , Please contact to delete .
3D Visual workshop boutique course official website :3dcver.com
1. Multi sensor data fusion technology for automatic driving field
2. For the field of automatic driving 3D Whole stack learning route of point cloud target detection !( Single mode + Multimodal / data + Code )
3. Thoroughly understand the visual three-dimensional reconstruction : Principle analysis 、 Code explanation 、 Optimization and improvement
4. China's first point cloud processing course for industrial practice
5. laser - Vision -IMU-GPS The fusion SLAM Algorithm sorting and code explanation
6. Thoroughly understand the vision - inertia SLAM: be based on VINS-Fusion The class officially started
7. Thoroughly understand based on LOAM Framework of the 3D laser SLAM: Source code analysis to algorithm optimization
8. Thorough analysis of indoor 、 Outdoor laser SLAM Key algorithm principle 、 Code and actual combat (cartographer+LOAM +LIO-SAM)
10. Monocular depth estimation method : Algorithm sorting and code implementation
11. Deployment of deep learning model in autopilot
12. Camera model and calibration ( Monocular + Binocular + fisheye )
13. blockbuster ! Four rotor aircraft : Algorithm and practice
14.ROS2 From entry to mastery : Theory and practice
15. The first one in China 3D Defect detection tutorial : theory 、 Source code and actual combat
blockbuster !3DCVer- Academic paper writing contribution Communication group Established
Scan the code to add a little assistant wechat , can Apply to join 3D Visual workshop - Academic paper writing and contribution WeChat ac group , The purpose is to communicate with each other 、 Top issue 、SCI、EI And so on .
meanwhile You can also apply to join our subdivided direction communication group , At present, there are mainly 3D Vision 、CV& Deep learning 、SLAM、 Three dimensional reconstruction 、 Point cloud post processing 、 Autopilot 、 Multi-sensor fusion 、CV introduction 、 Three dimensional measurement 、VR/AR、3D Face recognition 、 Medical imaging 、 defect detection 、 Pedestrian recognition 、 Target tracking 、 Visual products landing 、 The visual contest 、 License plate recognition 、 Hardware selection 、 Academic exchange 、 Job exchange 、ORB-SLAM Series source code exchange 、 Depth estimation Wait for wechat group .
Be sure to note : Research direction + School / company + nickname , for example :”3D Vision + Shanghai Jiaotong University + quietly “. Please note... According to the format , Can be quickly passed and invited into the group . Original contribution Please also contact .

▲ Long press and add wechat group or contribute
▲ The official account of long click attention
3D Vision goes from entry to mastery of knowledge : in the light of 3D In the field of vision Video Course cheng ( 3D reconstruction series 、 3D point cloud series 、 Structured light series 、 Hand eye calibration 、 Camera calibration 、 laser / Vision SLAM、 Automatically Driving, etc )、 Summary of knowledge points 、 Introduction advanced learning route 、 newest paper Share 、 Question answer Carry out deep cultivation in five aspects , There are also algorithm engineers from various large factories to provide technical guidance . meanwhile , The planet will be jointly released by well-known enterprises 3D Vision related algorithm development positions and project docking information , Create a set of technology and employment as one of the iron fans gathering area , near 4000 Planet members create better AI The world is making progress together , Knowledge planet portal :
Study 3D Visual core technology , Scan to see the introduction ,3 Unconditional refund within days
There are high quality tutorial materials in the circle 、 Answer questions and solve doubts 、 Help you solve problems efficiently
Feel useful , Please give me a compliment ~
边栏推荐
- 链接器和链接器选项、运行时库和运行时库设置、配置设置、生成过程和方法
- Cube 技术解读 | Cube 渲染设计的前世今生
- Leetcode (Sword finger offer) - 10- ii Frog jumping on steps
- Pyspark case series 4-dataframe output to a single folder solution
- 2022年安全月各类活动方案汇报(28页)
- Fix the problem that uicollectionview does not reach the bottom security zone
- MySQL foundation part common constraints summary part 2
- Summary of English thesis reading knowledge
- Hardware Description Language HDL
- golang编译和链接参数,运行时
猜你喜欢

使用 Ribbon 实现客户端负载均衡

pyspark案例系列4-dataframe输出到单个文件夹的解决方案

Install MySQL version 5.7 or above on windows (install in compressed package)
![[CV basis] Color: rgb/hsv/lab](/img/0f/188b103bc910b1a635b8f421f38ec2.png)
[CV basis] Color: rgb/hsv/lab
![Jerry's acquisition of ble to check the causes of abnormal conditions such as abnormal code reset [chapter]](/img/c5/a9468ad75bd6a8776c0695140d1a5d.png)
Jerry's acquisition of ble to check the causes of abnormal conditions such as abnormal code reset [chapter]

杰理之获取 BLE OTA 双备份升级(只能用于 4Mbits 以上的芯片)【篇】

Report on various activity plans of safety month 2022 (28 pages)
Using ribbon to realize client load balancing

MYSQL(九)

封装组件系列-(一)-插槽及动态组件
随机推荐
Update更新 bytea类型失败 PostGresql
RxJs fromEvent 工作原理分析
C language course design topic
MN梦奈宝塔主机系统V1.5版本发布
Mxnet construction and implementation of alexnet model (comparison with lenet)
白屏时间、首屏时间
Ngui, floating blood
Wechat cloud development al short video one click face changing applet source code
Electron desktop development (development of an alarm clock [End])
施一公:我直到博士毕业,对研究也没兴趣!对未来很迷茫,也不知道将来要干什么......
Yibentong 1122: calculating saddle point
Ngui, cooling effect
云开发mbti人格类型测试助手微信小程序源码
杰理之BLE SPP 开启 pin_code 功能【篇】
Jerry's ble spp open pin_ Code function [chapter]
Pl/sql compilation check in kingbasees
使用 Ribbon 实现客户端负载均衡
Online files are not transferred to Base64
Half of the property rights of the house are registered in the woman's name when they are in love, and they want to return after they break up
MYSQL(九)