当前位置:网站首页>Mxnet construction and implementation of alexnet model (comparison with lenet)
Mxnet construction and implementation of alexnet model (comparison with lenet)
2022-06-11 10:31:00 【Yinque Guangqian】
2012 year Alex Krizhevsky( First author of the paper ),Ilya Sutskever(OpenAI R & D Director ),Geoffrey E. Hinton( Father of deep learning ) An epoch-making paper , English address :ImageNet Classification with Deep ConvolutionalNeural Networks It is the foundation work of deep learning , The first two great gods are Hinton Of the students , The dataset used was created by lifeifei ImageNet( This data set has pushed the research of computer vision and machine learning into a new stage )
Previously introduced MXNet Use GPU Training LeNet Model Good results on small data sets , But it doesn't perform very well on larger real data sets , For example, now this ImageNet Data sets ,120 Million high-resolution pictures , And it contains 6000 Ten thousand parameters and 65 Ten thousand neurons . For such a large data set , therefore AlexNet He was born .

AlexNet And LeNet The design concept is very similar , The following are the significant differences
1、AlexNet The network layer deepens , Yes 8 Convolution layers (5 Layer convolution and 2 Layer full connection hidden layer , as well as 1 All connected output layers )
And you can see that , The size of the first convolution kernel is 11*11, Because the width and height of the image are relatively large , So the window of convolution kernel cannot be too small , The convolution window of the second layer is reduced to 5*5, hinder 3 All the convolution layers adopt 3*3, The window shape of the maximum pool layer is 3*3, The stride is 2, And this one AlexNet The number of convolution channels is also tens of times that of LeNet Number of convolution channels in .
Next to the last convolution layer are two outputs 4096( each GPU yes 2048), Because the parameters are close to 1GB, So limited by the size of the video memory at that time , But for this split design , Some very large models are still very useful , After all, one piece GPU Sometimes I can't make up my mind
2、AlexNet take sigmoid The activation function is modified to be simple ReLU Activation function , Mainly when sigmoid The output of the activation function is very close to 0 or 1 when , The gradient of these regions is almost 0, As a result, back propagation cannot continue to update some model parameters ; and RelU The gradient of the activation function in the positive interval is constant 1. therefore , If the model parameters are not initialized properly ,sigmoid A function may be obtained in a positive interval almost equal to 0 Gradient of , So that the model can not be effectively trained .RelU It is also called an unsaturated nonlinear activation function , That is, it doesn't put input into the extrusion , Except less than 0 The location of 0 outside , Others are reserved for input , Unlike sigmoid and tanh This kind has extrusion ( saturated ) The activation function of , Fixed the input to 0 To 1 or -1 To 1 The interval between .
3、AlexNet The model complexity of the full connection layer is controlled by discarding method , and LeNet There is no . This is also a good method to suppress over fitting
4、AlexNet Introduced a lot of image enhancement , Like flipping 、 tailoring 、 And color changes , So as to further expand the data set and mitigate over fitting , Because the previous article introduced , If the data set is small, it is easy to generate over fitting .
Of course, these differences and advantages , It is not the first time that they have proposed , You can also see that there are 26 In reference to , Although it is a collection of methods that many people have done , But it still puts forward a lot of innovative things , It has a far-reaching impact on future in-depth learning , Otherwise, it would not be said to be a foundation work . Because of this ImageNet Dataset too large , I have only one piece 2G Of GPU, So choose the original FashionMNIST Data sets to demonstrate , It doesn't use the cutting into two pieces mentioned in the paper GPU In the practice .
import d2lzh as d2l
from mxnet import gluon,init,nd
from mxnet.gluon import data as gdata,nn
import os
import sys
import mxnet as mx
net=nn.Sequential()
# There are two pieces in the paper GPU, So the value of the sum of the two blocks of the channel number
net.add(nn.Conv2D(96,kernel_size=11,strides=4,activation='relu'),
nn.MaxPool2D(pool_size=3,strides=2),
nn.Conv2D(256,kernel_size=5,padding=2,activation='relu'),
nn.MaxPool2D(pool_size=3,strides=2),
nn.Conv2D(384,kernel_size=3,padding=1,activation='relu'),
nn.Conv2D(384,kernel_size=3,padding=1,activation='relu'),
nn.Conv2D(256,kernel_size=3,padding=1,activation='relu'),
nn.MaxPool2D(pool_size=3,strides=2),
# Fully connected layer , Then use Dropout Discard layer
nn.Dense(4096,activation='relu'),nn.Dropout(0.5),
nn.Dense(4096,activation='relu'),nn.Dropout(0.5),
# Because it's not used ImageNet Data sets , This is not a part of the thesis 1000
nn.Dense(10)
)
X=nd.random.uniform(shape=(1,1,224,224))
net.initialize()
for layer in net:
X=layer(X)
print(' Shape of the output :',X.shape)
'''
Shape of the output : (1, 96, 54, 54)
Shape of the output : (1, 96, 26, 26)
Shape of the output : (1, 256, 26, 26)
Shape of the output : (1, 256, 12, 12)
Shape of the output : (1, 384, 12, 12)
Shape of the output : (1, 384, 12, 12)
Shape of the output : (1, 256, 12, 12)
Shape of the output : (1, 256, 5, 5)
Shape of the output : (1, 4096)
Shape of the output : (1, 4096)
Shape of the output : (1, 4096)
Shape of the output : (1, 4096)
Shape of the output : (1, 10)
'''Now let's train the model , We did data enhancement before reading data , Enlarge the height and width of the image to 224, adopt Resize Examples to achieve , The training method is MXNet Use GPU Training LeNet Model Appear , Also included in d2lzh In bag , If it is CPU Training , I am a i5-7500 It just exploded , Can't train , So switch to GPU

# Has been included in d2lzh In bag
def load_data_fashion_mnist(batch_size,resize=None,root=os.path.join('~','.mxnet','datasets','fashion-mnist')):
root=os.path.expanduser(root)# take ~ Replace with the current user directory , Such as C:\Users\Tony\.mxnet\datasets\fashion-mnist
transformer=[]
if resize:
transformer+=[gdata.vision.transforms.Resize(resize)]#[Resize()]
transformer+=[gdata.vision.transforms.ToTensor()]#[Resize(), ToTensor()]
transformer=gdata.vision.transforms.Compose(transformer)#Compose((0): Resize()(1): ToTensor())
mnist_train=gdata.vision.FashionMNIST(root=root,train=True)
mnist_test=gdata.vision.FashionMNIST(root=root,train=False)
num_workers=0 if sys.platform.startswith('win32') else 4
train_iter=gdata.DataLoader(mnist_train.transform_first(transformer),batch_size,shuffle=True,num_workers=num_workers)
test_iter=gdata.DataLoader(mnist_train.transform_first(transformer),batch_size,shuffle=False,num_workers=num_workers)
return train_iter,test_iter
batch_size=50
train_iter,test_iter=load_data_fashion_mnist(batch_size,resize=96)# The paper is 224
lr,num_epochs,ctx=0.01,5,d2l.try_gpu()
#lr,num_epochs,ctx=0.01,5,mx.cpu()
net.initialize(force_reinit=True,ctx=ctx,init=init.Xavier())
trainer=gluon.Trainer(net.collect_params(),'sgd',{'learning_rate':lr})
d2l.train_ch5(net,train_iter,test_iter,batch_size,trainer,ctx,num_epochs)
[12:21:13] c:\jenkins\workspace\mxnet-tag\mxnet\src\operator\nn\cudnn\./cudnn_algoreg-inl.h:97: Running performance tests to find the best convolution algorithm, this can take a while... (set the environment variable MXNET_CUDNN_AUTOTUNE_DEFAULT to 0 to disable)
training on gpu(0)
epoch 1, loss 1.5937, train acc 0.396, test acc 0.577, time 69.4 sec
epoch 2, loss 0.7274, train acc 0.724, test acc 0.774, time 68.6 sec
epoch 3, loss 0.5738, train acc 0.784, test acc 0.798, time 70.7 sec
epoch 4, loss 0.4959, train acc 0.813, test acc 0.825, time 71.0 sec
epoch 5, loss 0.4489, train acc 0.833, test acc 0.847, time 70.2 sec The training time is relatively long , The reason why the video memory is small , I am a Geforce GTX 1050,2G memory ( command :dxdiag)
The above prompt can be disabled , stay Linux And Windows The settings are as follows :
export MXNET_CUDNN_AUTOTUNE_DEFAULT=0
set MXNET_CUDNN_AUTOTUNE_DEFAULT=0
Finally, we see the implementation AlexNet Only than LeNet It seems that there are only a few more layers , In fact, the production of new ideas and excellent experimental results , It takes many years for the academic community to make such achievements .
边栏推荐
猜你喜欢

Introduction to ZigBee module wireless transmission star topology networking structure

吴恩达机器学习课程-第七周
Some code fragments of a universal and confession wall system developed by PHP

EMC rectification cases of electronic equipment radiation
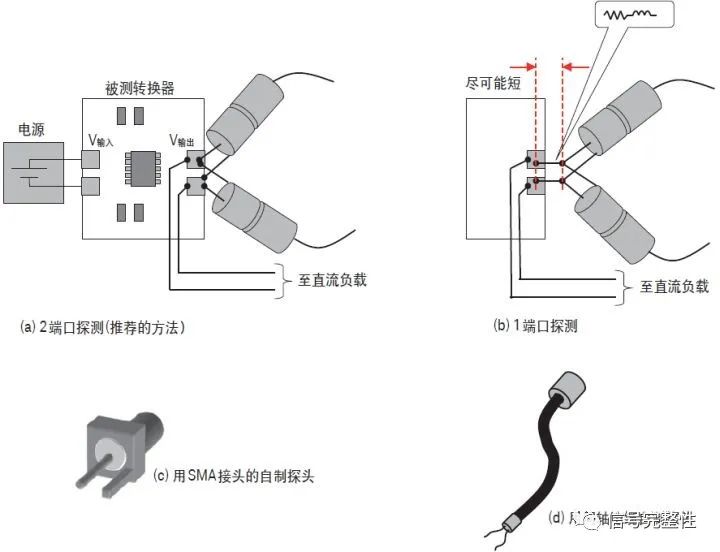
详述用网络分析仪测量DC-DC和PDN

Leetcode 1952. 三除数

TikTok在英国遭遇文化冲突,短期内众多员工离职

Ugui picture wall

Dimension types for different CV tasks

rpc的正确打开方式|读懂Go原生net/rpc包
随机推荐
Pl/sql compilation check in kingbasees
NGUI,选择性别男女
1. system in Library
详述用网络分析仪测量DC-DC和PDN
Detail measurement of DC-DC and PDN with network analyzer
Wuenda machine learning course - week 7
Unity字体间距
Cas de rectification du CEM rayonné par des équipements électroniques
NFT将改变元宇宙中的数据所有权
GameFi:您需要了解的关于“即玩即赚”游戏经济的一切
Explain the physical layer consistency test of 2.5g/5g/10g Base-T Ethernet interface in detail!
用真金做的电路板——金手指
Tiktok encounters cultural conflict in the UK, and many employees leave in a short time
链接器和链接器选项、运行时库和运行时库设置、配置设置、生成过程和方法
电子设备辐射EMC整改案例
MySQL comparison
Where is it safer to open an account for soda ash futures? How much money can you do?
Summary of common constraints in MySQL foundation part I
WordPress website backup
Knowledge drop - personality analysis - four types of method