当前位置:网站首页>自监督论文阅读笔记 Self-supervised Label Augmentation via Input Transformations
自监督论文阅读笔记 Self-supervised Label Augmentation via Input Transformations
2022-08-03 05:23:00 【YoooooL_】
自监督学习通过仅给定输入信号构造人工标签来学习,最近已经获得了对无标签数据集的学习表示的相当大的关注,即,没有任何人类注释监督的学习。在本文中,证明了这种技术即使在完全标记的数据集下,也能显著提高模型的准确性。本文的方案训练模型来学习原始和自监督的任务,但不同于传统的多任务学习框架,传统的多任务学习框架优化其相应损失的总和。本文的主要思想是学习关于原始和自监督标签的联合分布的单个统一任务,即,通过输入变换的自监督来增强原始标签。这种简单而有效的方法允许通过在同时学习原始和自监督任务期间放松某个不变约束来更容易地训练模型。它还实现了组合来自不同增强的预测的聚合推断,以提高预测准确性。此外,本文提出了一种新的知识迁移技术,我们称之为self-distillation 自蒸馏,它具有在单个(更快的)推理中聚合推理的效果。本文的框架在各种完全监督的设置上的大的准确性改进和广泛的适用性,例如,少样本和不平衡分类场景。
自监督:当缺少人类标注的标签时,该方法仅使用输入示例来构造人工标签,然后通过预测标签来学习它们的表示。一种最简单但有效的自监督学习方法是通过仅观察修改后的输入t(x)来预测哪个变换t应用于输入x,例如,t可以是patch置换 或旋转 。为了预测这种转换,模型应该区分什么是语义上自然的,因此,它学习输入的高级语义表示。
基于变换的自监督的简单性鼓励了其在无监督表示学习之外的其他目的的广泛适用性,例如半监督学习 、提高鲁棒性 、训练生成对抗网络 。先前的工作通常为原始任务和自监督任务维护两个独立的分类器(但共享公共的特征表示),并同时优化它们的目标。然而,当处理完全标记的数据集时,这种多任务学习方法通常不会提供准确性增益。这启发我们探索以下问题:如何有效地利用基于变换的自监督来完成全监督分类任务?
Contributions:
多任务学习方法迫使原始任务的主要分类器相对于自监督任务的变换是不变的。例如,当使用旋转作为自我监督时,将每个图像旋转0、90、180、270度,同时保留其原始标签,主分类器被迫学习对旋转不变的表示。强制这种不变性可能会导致任务的复杂性增加,因为转换可能会在很大程度上改变样本的特征和/或用于识别目标的有意义的信息,例如图像分类{6对9}或{鸟对蝙蝠}。因此,这可能会损害整体表示学习,并降低主要的全监督模型的分类精度。
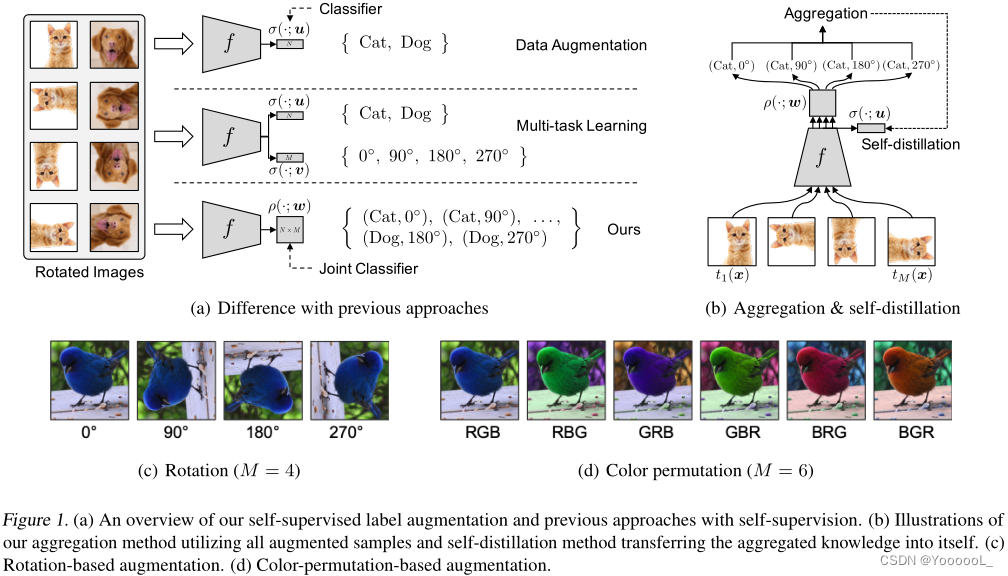
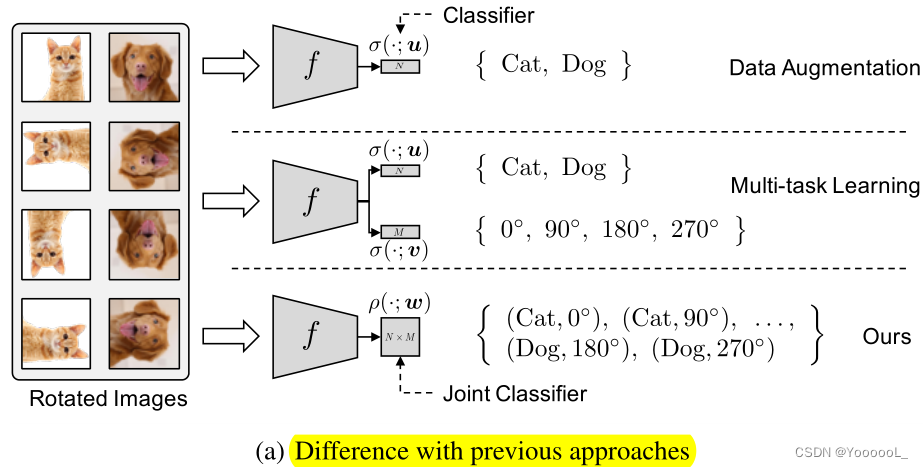
为了应对这一挑战,本文提出了一个简单而有效的想法(见图1(a)),即学习关于原始和自监督标签的联合分布的单个统一任务,而不是先前自监督文献中通常使用的两个独立任务。例如,当在CIFAR10(10个标签)上用旋转的自监督(4个标签)进行训练时,我们学习所有可能组合的联合概率分布,即40个标签。
这种标签增强方法,我们称为自监督标签增强 (SLA),在不假设原始标签和自监督标签之间的关系的情况下,不会强制转换具有任何不变性。此外,由于本文为每个转换 分配不同的自监督标签,因此可以在测试时 通过聚合所有转换 来进行预测,如图 1(b) 所示。这可以使用单个模型提供(隐式的)集成效果。最后,为了在 不损失 集成效果的情况下 加快推理过程,本文提出了一种新颖的自蒸馏技术,该技术将多个推理的知识转化为单个推理,如图 1(b) 所示。
在本文的实验中,考虑了两种用于自监督标签增强的输入变换,旋转(4 个变换)和 颜色排列(6 个变换),分别如图 1(c) 和图 1(d) 所示。为了证明本文方法的广泛适用性和兼容性,尝试了各种基准数据集和分类场景,包括 少样本 和 不平衡的分类任务。在所有测试设置中,本文的简单方法 显著且一致地 提高了分类准确性。例如,本文的方法在 CIFAR-100 上的标准全监督任务(Krizhevsky 等人,2009)和 FC100 上的 5-way 5-shot 任务(Oreshkin 等人, 2018),分别超过相关基线。
在本节中,在关注完全监督的场景下提供本文的自监督标签增强技术的细节。首先在 2.1 节讨论利用自监督标签的传统多任务学习方法及其局限性。然后,在第 2.2 节介绍了本文的学习框架,该框架可以充分利用自监督的力量。在这里,还提出了两种附加技术:聚合,它利用所有不同的增强样本来使用单个模型提供集成效果;和自蒸馏,将聚合的知识转移到模型本身中,以加快推理速度而不损失集成效果。
设![]() 为输入,
为输入,![]() 是它的标签,其中 N 是类数,LCE 是交叉熵损失函数,σ(·; u) 是 softmax 分类器,即
是它的标签,其中 N 是类数,LCE 是交叉熵损失函数,σ(·; u) 是 softmax 分类器,即![]() 。z = f(x; θ) 是 x 的嵌入向量,其中 f 是参数为 θ 的神经网络。我们还让
。z = f(x; θ) 是 x 的嵌入向量,其中 f 是参数为 θ 的神经网络。我们还让![]() 表示使用变换 t 的增强样本,并且
表示使用变换 t 的增强样本,并且![]() 是增强样本
是增强样本 ![]() 的嵌入。
的嵌入。
在基于转换的自监督学习中(Doersch et al., 2015; Noroozi & Favaro, 2016; Larsson et al., 2017; Gidaris et al., 2018; Zhang et al., 2019a),给定修改后的样本![]() ,模型学习预测哪种转换t 应用于输入 x。将自监督标签用于其他任务的常用方法是 优化主要任务和自监督任务的两个损失,同时在它们之间共享特征空间(Chen 等人,2019;Hendrycks 等人,2019;Zhai 等人)等人,2019);即 在多任务学习框架中 训练这两个任务。因此,在完全监督的环境中,可以将 有自监督的多任务目标 LMT 制定如下:
,模型学习预测哪种转换t 应用于输入 x。将自监督标签用于其他任务的常用方法是 优化主要任务和自监督任务的两个损失,同时在它们之间共享特征空间(Chen 等人,2019;Hendrycks 等人,2019;Zhai 等人)等人,2019);即 在多任务学习框架中 训练这两个任务。因此,在完全监督的环境中,可以将 有自监督的多任务目标 LMT 制定如下:
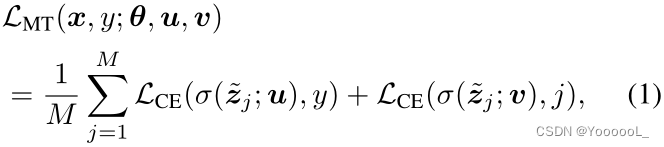
其中 ![]() 是预定义的变换,
是预定义的变换,![]() 是 tj 的变换样本,
是 tj 的变换样本,![]() 是它对神经网络 f 的嵌入。这里,σ(·; u) 和 σ(·; v) 分别是 主要任务 和 自监督任务的分类器。上述损失迫使 主要分类器 σ(f(·); u) 对变换 {tj} 保持不变。根据转换的类型,强制这种不变性可能没有意义,因为增强的训练样本(例如,通过旋转)的统计特征 可能与原始训练样本的统计特征大不相同。在这种情况下,对这些转换实施不变性会使学习变得更加困难,甚至会降低性能(参见第 3.2 节中的表 1)。
是它对神经网络 f 的嵌入。这里,σ(·; u) 和 σ(·; v) 分别是 主要任务 和 自监督任务的分类器。上述损失迫使 主要分类器 σ(f(·); u) 对变换 {tj} 保持不变。根据转换的类型,强制这种不变性可能没有意义,因为增强的训练样本(例如,通过旋转)的统计特征 可能与原始训练样本的统计特征大不相同。在这种情况下,对这些转换实施不变性会使学习变得更加困难,甚至会降低性能(参见第 3.2 节中的表 1)。
在多任务学习目标(1)中,如果我们不学习自监督,则可以将其视为数据增强目标 LDA,如下所示:
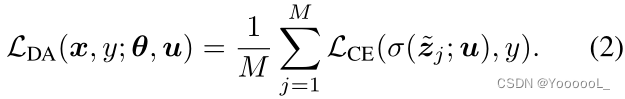
这种传统的数据增强 旨在 通过利用可以保留其语义的某些转换(例如裁剪、对比度增强和翻转)来提高目标神经网络 f 的泛化能力。另一方面,如果 变换 修改了语义,则 关于变换的不变属性可能会干扰语义表示学习(参见第 3.2 节中的表 1)。
通过联合标签分类器消除不变性:
本文的关键思想是 去除 变换样本中 (1)和(2)中 分类器 σ(f(·);u) 的不必要的不变性质。为此,我们使用 联合 softmax 分类器 ρ(·; w) 表示联合概率为![]() ,
,
那么,我们的训练目标可以写成:
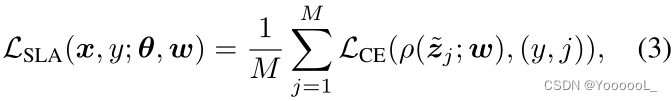
其中,![]() 。请注意,该框架仅增加了标签的数量,因此与整个网络相比,额外的参数的数量可以忽略不计,例如,使用 ResNet-32 时仅新引入了 0.4% 的参数(He et al., 2016)。我们还注意到,当所有 i、j 的
。请注意,该框架仅增加了标签的数量,因此与整个网络相比,额外的参数的数量可以忽略不计,例如,使用 ResNet-32 时仅新引入了 0.4% 的参数(He et al., 2016)。我们还注意到,当所有 i、j 的 ![]() 时,上述目标可以简化为多任务学习目标 LMT (1),而当所有 i 的
时,上述目标可以简化为多任务学习目标 LMT (1),而当所有 i 的 ![]() 时,可以将上述目标简化为数据增强目标 LDA (2)。
时,可以将上述目标简化为数据增强目标 LDA (2)。
从优化的角度来看,LMT 和 LSLA 考虑的是同一组多标签,但前者需要额外的约束,因此比后者更难优化。传统增强、多任务学习 和 本文的增强 之间的区别如图 1(a) 所示。在训练期间,我们像 Gidaris 等人(2018) 一样为每次迭代同时提供所有 M 个增强样本,即对于每个 mini-batch B,我们最小化![]() 。本文还假设第一个变换是恒等函数,即
。本文还假设第一个变换是恒等函数,即 ![]() 。
。
聚合推理:
给定一个测试样本 x 或 其通过变换 tj 增强的样本 ∼xj = tj(x),我们不需要考虑所有 N × M 个标签来预测其原始标签,因为我们已经知道应用了哪种变换。因此,我们使用条件概率![]()
![]() 进行预测,其中 ∼zj = f(∼xj)。此外,对于所有可能的变换 {tj},我们 聚合相应的条件概率 以提高分类精度,即我们训练一个模型,该模型可以像集成模型一样执行推理。为了计算 聚合推理 的概率,我们首先平均 pre-softmax 激活(即 logits),然后计算 softmax 概率如下:
进行预测,其中 ∼zj = f(∼xj)。此外,对于所有可能的变换 {tj},我们 聚合相应的条件概率 以提高分类精度,即我们训练一个模型,该模型可以像集成模型一样执行推理。为了计算 聚合推理 的概率,我们首先平均 pre-softmax 激活(即 logits),然后计算 softmax 概率如下:
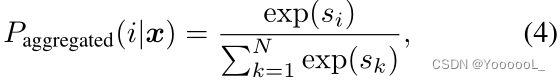
其中,![]() 。(PS:j=1~M 指的是变换,一共有M个变换。)由于我们为每个转换 tj 分配不同的标签,我们的聚合方案 显着提高了准确性。有点令人惊讶的是,它在我们的实验中实现了 与多个独立模型的集合 相当的性能(参见第 3.2 节中的表 2)。我们 将聚合的对应物称为 单一推理,它仅使用非增强 或 原始样本
。(PS:j=1~M 指的是变换,一共有M个变换。)由于我们为每个转换 tj 分配不同的标签,我们的聚合方案 显着提高了准确性。有点令人惊讶的是,它在我们的实验中实现了 与多个独立模型的集合 相当的性能(参见第 3.2 节中的表 2)。我们 将聚合的对应物称为 单一推理,它仅使用非增强 或 原始样本 ![]() ,即使用
,即使用 ![]() 预测标签。
预测标签。
聚合自蒸馏 Self-distillation from aggregation:
尽管前面提到的 聚合推理 实现了出色的性能,但它需要为所有 j 计算 ~zj = f(~xj),即它需要 比单个推理高 M 倍的 计算成本。为了加速推理,我们 从聚合知识 Paggregated(·|x) 执行自蒸馏 (Hinton et al., 2015; Lan et al., 2018) 到另一个由 u 参数化的分类器 σ(f(x; θ); u) ,如图 1(b) 所示。然后,分类器 σ(f(x; θ); u) 可以 仅使用一个嵌入 z = f(x) 来维护聚合知识。为此,我们优化了以下目标:
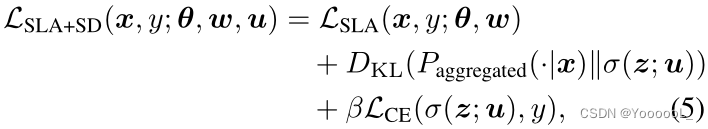
其中 β 是一个超参数,我们简单地选择 β ∈ {0, 1}。在计算 LSLA+SD 的梯度时,我们将 Paggregated(·|x) 视为一个常数。训练后,我们使用 σ(f(x; θ); u) 进行推理而不进行聚合。
本文将 仅使用随机裁剪和翻转 进行数据增强(没有旋转和颜色排列)的基线称为“Baseline”。请注意,DA 与 Baseline 不同,因为 DA 使用自监督作为增强(例如,旋转),而 Baseline 没有。在使用 LSLA 进行训练后,本文考虑了两种推理方案:分别由 SLA+SI 和 SLA+AG 表示的 单一推理 P (i|x, j = 1) 和 聚合推理 Paggregated(i|x)。我们还将自蒸馏方法 LSLA+SD (5) 表示为 SLA+SD,它仅使用单个推理 σ(f(x; θ); u)。
变换的选择:
由于在训练期间 使用整个输入图像 对于图像分类很重要,因此一些自监督技术不适合本文的目的。例如,拼图方法 (Noroozi & Favaro, 2016) 将输入图像划分为 3 × 3 块,然后分别计算它们的嵌入。使用这种嵌入的预测 比 使用整个图像的预测性能更差。为了避免这个问题,本文选择了两种使用整个输入图像而不进行裁剪的变换:旋转(Gidaris 等人,2018)和 颜色排列。旋转构造 M = 4 个旋转图像(0°、90°、180°、270°),如图 1(c) 所示。由于其简单性,这种变换被广泛用于自监督(Chen et al., 2019; Zhai et al., 2019)。颜色排列 构造 M = 3!= 6 通过交换 RGB 通道获得 6 个不同的图像,如图 1(d) 所示。当颜色信息很重要(例如细粒度分类数据集)时,这种转换会很有用。
为了直观地了解学习关于某些变换的不变属性的难度,我们在此介绍简单的示例:三个二进制数字图像分类任务,{1 vs. 9}、{4 vs. 9} 和 {6 vs. 9} 在 MNIST (LeCun et al., 1998) 中使用基于原始像素值的线性分类器。如图 2(a) 所示,使用线性分类器 对直立数字 进行分类 通常更容易,例如,仅对直立的 6s 和 9s 进行分类时的误差为 0.2%。请注意,4 和 9 具有相似的形状,因此它们的像素值 比其他对 更接近。在保留标签的同时 旋转数字后,线性分类器仍然可以区分旋转的 1 和 9,如图 2(b) 所示,但不能区分旋转的 4、6 和 9,如图 2(c) 和 2(d) ,例如,对旋转的 6s 和 9s 进行分类时有 13% 的错误。这些例子表明,线性可分数据 在通过旋转等一些变换增强后 可能不再是线性可分的,即解释了为什么强制不变属性 会增加学习任务的难度。但是,如果为每次旋转分配不同的标签(正如我们在本文中提出的那样),那么线性分类器可以 对旋转的数字 进行分类,例如,在对旋转的 6s 和 9s 进行分类时有 1.1% 的误差。
与 DA 和 MT 的比较:
本文凭经验验证 本文提出的方法可以利用自监督,而不会损失全监督数据集的准确性,而 数据增强 和 多任务学习方法 则不能。为此,本文 使用三个不同的目标 在通用分类数据集 CIFAR10/100 和 tiny-ImageNet 上训练模型:数据增强 LDA (2)、多任务学习 LMT (1) 和 本文的带旋转的自监督标签增强 LSLA ( 3) 。如表 1 所示,与不使用基于旋转的增强的基线相比,LDA 和 LMT 显着降低了性能。但是,当使用 LSLA 进行训练时,性能略有提高。图 3 显示了 CIFAR100 在训练过程中训练和测试样本的分类准确率。如图所示,LDA 会导致比其他方法更高的泛化误差,因为 LDA 强制了不必要的不变量属性。此外,优化 LMT 比第 2.2 节中描述的 LSLA 更难,因此 前者 在训练和测试样本上的准确率 都低于后者。这些结果表明,学习对某些变换(例如旋转)的不变性会使优化变得更加困难并降低性能。即,应谨慎处理此类转换。
与独立的集成的比较:
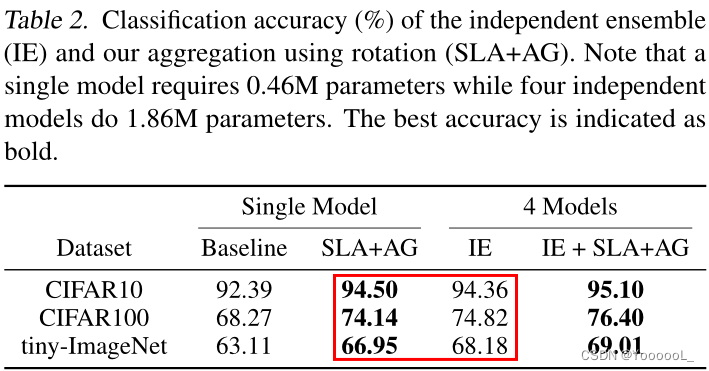
接下来,为了评估 聚合在 SLA 训练模型中的效果,本文将 使用旋转的聚合 与 独立集成 (IE) 进行比较,该集成 在独立训练的模型上 聚合 pre-softmax 激活(即 logits)。本文在这里使用四个独立的模型(即,比我们的参数多 4 倍),因为具有四个模型的 IE 和 SLA+AG 具有相同的推理成本。令人惊讶的是,如表 2 所示,与集成相比,使用旋转的聚合 实现了具有竞争力的性能。当同时使用 IE 和 带有旋转的SLA+AG 时,即与集成相同数量的参数时,精度会进一步提高。
本文首先在 2.2 节 (4) 中评估聚合推理 Paggregated(·|x) 的效果:参见表 3 中的 SLA+AG 列。使用旋转作为增强可以提高所有数据集的分类准确度,例如 8.60% 和 18.8分别在 CIFAR100 和 CUB200 上相对于基线的 % 相对增益。通过颜色排列,CIFAR 和 tiny-ImageNet 上的性能改进不太显着,但它仍然在细粒度数据集上提供了有意义的收益,例如 CUB200 和斯坦福狗的相对增益分别为 12.6% 和 10.6%。在补充材料中,我们还提供了对大规模数据集的额外实验,例如 8k 标签的 iNaturalist (V an Horn et al., 2018),以证明 SLA 在标签数量方面的可扩展性。
由于这两种转换对细粒度数据集都有效,因此本文还测试了两种不同类型转换的 组合转换 以进一步改进。为了构建组合的转换,本文首先分别选择旋转和颜色排列的两个子集 Tr 和 Tc,例如,Tr = {0◦, 180◦} 或 Tc = {RGB, GBR, BRG}。然后,我们组合它们,即 T = {tc ◦ tr : tr ∈ Tr, tc ∈ Tc}。这意味着 t = tc ◦ tr ∈ T 将图像旋转 tr,然后交换颜色通道 tc。如表 9 所示,使用更大的集合 T 进一步改进了聚合推理。然而,在过多的转换下,聚合性能 可能会 因为优化变得过于困难 而降低。当使用 M = 12 变换时,本文获得了最佳性能,比 CUB200 上的基线高出 20.8%。补充材料中报告了关于Stanord Dogs 的类似实验。
本文进一步将 SLA+SD(在推理上比 SLA+AG 更快)与现有的增强技术,Cutout (DeVries & Taylor, 2017)、CutMix (Y un et al., 2019)、AutoAugment (Cubuk et al., 2019) ) 和 FastAutoAugment (Lim et al., 2019) 应用到最近的架构中 (Zagoruyko & Komodakis, 2016b; Han et al., 2017)。请注意,SLA 使用语义敏感的转换来分配不同的标签,而传统的数据增强方法使用语义不变的转换来保留标签。因此,使用 SLA 和传统数据增强 (DA) 技术的转换不会重叠。例如,AutoAugment (Cubuk et al., 2019) 策略将图像最多旋转 30 度,而 SLA 至少旋转 90 度。因此,SLA 可以自然地与现有的 DA 方法相结合。如表 5 所示,SLA+SD 始终如一地减少分类错误。因此,它在 CIFAR10/100 上的错误率分别为 1.80% 和 12.24%。这些结果证明了本文方法的兼容性。
有限数据:
当只有 很少的训练样本 可用时,本文的增强技术也很有效。为了评估有效性,本文首先通过为每个类随机选择 n ∈ {25, 50, 100, 250} 个样本来构建 CIFAR100 的子数据集,然后在使用和不使用 本文基于旋转的自监督标签增强的情况下 训练模型。如图 4 所示,本文的方案在聚合下将准确率提高了 37.5%,在没有聚合的情况下提高了 21.9%。
少样本分类:
受上述数据限制条件下结果的启发,本文还结合最近的方法 ProtoNet (Snell et al., 2017) 和 MetaOptNet (Lee et al., 2019) 应用 本文的 SLA+AG5 方法来 解决少样本分类问题。请注意,当使用 M-way 转换时,本文的方法将 N-way K-shot 任务增加到 N M-way K-shot。如表 6 所示,本文的方法在 mini-ImageNet、CIFAR-FS 和 FC100 上持续提高了 5-way 1/5-shot 分类精度 例如,在 FC100 的 5-shot 任务上获得了 7.05% 的相对改进。在这里,可以通过 对 本文的(和基线)应用 额外的数据增强技术 来获得 进一步的改进,如第 3.3 节所示。然而,我们发现 使用最先进的数据增强技术 进行训练 和/或 使用 ten-crop(Krizhevsky 等人,2012)进行测试 并不总是为少样本实验 提供有意义的改进,例如在本文的实验中, AutoAugment(Cubuk 等人,2019 年)和 Ten-crop 在 ProtoNet 下的 FC100 上提供了边际 (<1%) 的准确度增益。
(PS:N-way是指N个类,K-shot是指每个类的样本数量。测试集是N-way K-shot,并且类别和训练集不交叉。少样本模型的目的就是learn to learn。)
不平衡的分类:
最后,本文考虑一组 不平衡的训练数据集,其中每个类的实例数量差异很大,有些类只有几个训练实例。在这个实验中,将本文的 SLA+SD 方法与最近的两种方法相结合,ClassBalanced (CB) 损失 (Cui et al., 2019) 和 LDAM (Cao et al., 2019),专门针对这个问题。在具有长尾标签分布的 CIFAR10/100 不平衡的数据集下,本文的方法不断提高分类精度,如表 7 所示(例如,在不平衡 CIFAR100 数据集上高达 13.3% 的相对增益)。结果表明 本文的自监督标签增强的广泛适用性。在这里,本文强调所有测试的方法(包括本文的 SLA+SD)都具有相同的推理时间。
自监督学习:
对于未标记数据集中的表示学习,自监督学习方法仅使用输入信号构建人工标签(称为自监督),然后学习预测它们。自监督可以以多种方式构建。其中一个简单的方法是基于转换的方法(Doersch et al., 2015; Noroozi & Favaro, 2016; Larsson et al., 2017; Gidaris et al., 2018; Zhang et al., 2019a)。他们首先通过变换修改输入,例如旋转(Gidaris 等人,2018)和 patches排列(Noroozi & Favaro,2016),然后将变换分配为输入的标签。
另一种方法是基于聚类的(Bojanowski 和 Joulin,2017 年;Caron 等人,2018 年;Wu 等人,2018 年;YM. 等人,2020 年)。他们首先使用当前模型执行聚类,然后使用聚类索引分配标签。当迭代地执行这个过程时,表示的质量会逐渐提高。 Wu等人(2018)不是聚类,而是为每个样本分配不同的标签,即将每个样本视为一个集群。
虽然最近基于聚类的方法在无监督学习方面优于基于转换的方法,但后者由于其简单性而被广泛用于其他目的,例如半监督学习(Zhai 等人,2019;Berthelot 等人,2020) ,提高鲁棒性(Hendrycks 等人,2019 年),以及训练生成对抗网络(Chen 等人,2019 年)。在本文中,还利用了 基于转换的自监督,但旨在提高全监督数据集下的准确性。
自蒸馏 Self-distillation:
欣顿等人(2015)提出了一种知识蒸馏技术,该技术通过转移(或蒸馏)预先训练的大型网络的知识来改进网络。有许多先进的蒸馏技术(Zagoruyko & Komodakis, 2016a; Park et al., 2019; Ahn et al., 2019; Tian et al., 2020),但它们应该首先训练更大的网络,这会导致高昂的训练成本。为了克服这个缺点,已经开发了将自己的知识转移到自身中的自蒸馏方法。 (Lan 等人,2018;Zhang 等人,2019b;Xu & Liu,2019)。他们利用部分独立的架构 (Lan et al., 2018)、数据失真 (Xu & Liu, 2019) 或 隐藏层 (Zhang et al., 2019b) 进行蒸馏。虽然这些方法在相同的标签空间上执行蒸馏,但 本文的框架 在通过自监督转换增强的不同标签空间之间转移知识。因此,我们的方法可以享受与现有方法的正交使用;例如,可以像 Zhang 等人 (2019b) 所做的那样,将聚合的知识 Paggregated (4) 提取到隐藏层中。
Conclusion:
本文提出了一种简单而有效的方法,通过学习 关于原始标签和自监督标签的联合分布的单个统一任务,对完全标记的数据集进行自监督。本文认为本文的工作可以为未来的研究带来许多有趣的方向;例如,人们可以重新审视之前关于自监督应用的工作,例如,具有自监督的半监督学习(Zhai et al., 2019; Berthelot et al., 2020)。将 本文的联合学习框架应用于 除少样本或不平衡分类任务之外的 全监督任务,或学习 选择有助于提高 主要任务的预测准确性 的任务,是其他有趣的未来研究方向。
边栏推荐
猜你喜欢



随机推荐
中国水产养殖行业市场投资分析及未来风险预测报告2022~2028年
浏览器多线程离屏渲染压缩打包方案
mysql 客户端SSL错误2026 (HY000)
【Arduino】关于“&”和“|” 运算-----多个参数运算结果异常的问题解决
神经网络之感知机
编程软件配备
Kettle Spoon 安装配置详解
Makefile
【解读合约审计】Harmony的跨链桥是如何被盗一亿美金的?
Gradle插件与代理服务器导致Sync Project失败的问题
opencv透视变化
spark sql 报错 Can‘t zip RDDs with unequal numbers of partitions
用iPhone前摄3D人像建模,Meta:我看行
解析各种文本的年月日
中国人力资源服务行业投资建议与前景战略规划研究报告2022~2028年
动态规划笔记
IPC 通信 - IPC
二阶段提问总结
深度学习基本概念
当我们在看Etherscan的时候,到底在看什么?