当前位置:网站首页>Image translation /gan:unsupervised image-to-image translation with self attention networks
Image translation /gan:unsupervised image-to-image translation with self attention networks
2022-06-26 04:50:00 【HheeFish】
Unsupervised Image-to-Image Translation with Self-Attention Networks Unsupervised image to image translation based on self attention network
Paper download
Open source code
0. Abstract
The purpose of unsupervised image translation is to give unpaired training data , Learn the transformation from source domain to target domain . Based on GANs Unsupervised image to image translation , Some of the most advanced works have achieved impressive results . Compared with local texture mapping tasks such as style conversion , It cannot capture strong geometric changes between domains , Or produce unsatisfactory results for complex scenes . lately ,SAGAN[35] indicate , Self attention network ratio convolution type GAN Produce better results . However , The effectiveness of self - attention network in unsupervised image - to - image translation has not been verified . In this paper , We propose an unsupervised image to image transformation with self attention network , Among them, long-distance dependence not only helps to capture strong geometric changes , And you can also use clues from all feature locations to generate details . In the experiment , We qualitatively and quantitatively prove the superiority of this method over the existing unsupervised image to image translation tasks .
1. summary
In computer vision and graphics , There are many image to image conversion tasks , Including repairing [17]、[26]、 Super resolution [10]、[19]、 To color [36]、[37]、 Style conversion [11]、[15]、[25] wait . This interdisciplinary topic of image to image translation has become a major concern of researchers .
in many instances , Given a paired data set , The problem can be solved by conditional image conversion [18]、[22]、[30]. However , Obtaining paired samples is difficult and expensive . Besides , In some cases supervision is not possible .
The goal of unsupervised image translation is given unpaired training data , Learn the transformation from source domain to target domain . Recent work is based on GANs The unsupervised image to image translation has achieved impressive results [1]、[8]、[16]、[20]、[23]、[27]、[29]、[34]、[38]. To a large extent, it can be divided into two types . The first is the style transformation task . The problem is to keep high-level information such as content or geometry , Change low-level information such as color or texture . Style shift and condition based GANs The method has achieved good results in this research field .
The second is the object deformation task . Different from the style conversion task , This task focuses on changing advanced information , While retaining low-level information .CycleGAN[38] It is the most representative unsupervised image translation method , Due to the network structure specially used for style transformation , It fails to change the high-level semantics .
In order to solve the problem of unsupervised image to image conversion , The first 23 Unit puts forward the assumption of shared potential space . It assumes that a pair of corresponding images in different domains can be mapped to the same potential code in the shared potential space .MUNIT[16] A multimodal unsupervised image to image translation framework is proposed .
To implement many to many cross domain mapping , It does this by decomposing each domain specific part of the shared potential space and style code across domains , Reduces the assumption that the potential space is fully shared in the unit .UNIT and MUNIT In the experiment, an impressive animal image translated from a head centered clipping data set is shown . When the training image data set is not standard in space , Due to the lack of correspondence between shared semantic parts , Make the problem more difficult .
In our experiment , We find that these methods often fail in the application of image to image translation with strong geometric changes . lately , Sagan (SAGAN)[35] indicate , The self - attention module is the complement of convolution , Helps to model long distances across image regions 、 Multi level dependencies . Although the self - attention module is unconditional GANs Success in , However, the effectiveness of the self attention module in unsupervised image to image translation has not been verified .
In this paper , We propose an unpaired image to image translation model with a self - attention network , This model allows long-distance dependency modeling for image translation tasks with strong geometric changes . In the experiment , We demonstrate the superiority of this method over the existing unsupervised image to image translation tasks .
2. Method
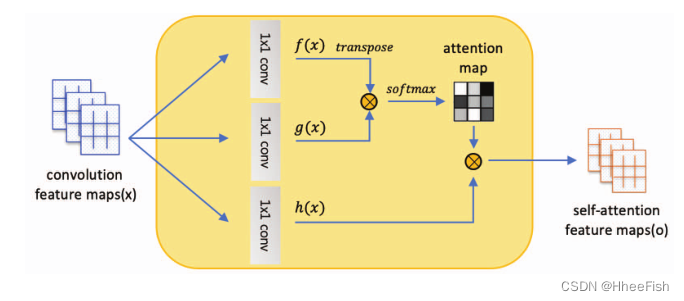
chart 1: Self attention network .[35] ⊗ Representation matrix multiplication .

chart 2: Architecture of network automatic encoder model
2.1. Unpaired image to image translation based on self attention network
We propose an unsupervised image to image translation model with a self - interested network , This model allows long-distance dependency modeling for image translation tasks with strong geometric changes . Combined with self attention , The generator can translate images , The fine details of each position are carefully coordinated with those of the remote part of the image . Besides , The discriminator can also impose complex geometric constraints on the global image structure more accurately .
In this paper , Our network architecture is based on the combination of multiple self attention modules into multimodal unsupervised image to image conversion (MUNIT) Model generator and discriminator .
In order to explore the effect of the proposed self attention mechanism , We build several by adding self - awareness mechanisms at different stages of the generator and discriminator SAGAN. For generators , The self attention layer is placed in front of the lower sampling layer in the encoder and the upper sampling layer in the decoder respectively . For the discriminator , It is added before the lower sampling layer . chart 2 It shows the architecture of an automatic encoder model with a self - interested network
2.2. Loss function
All the objectives of our model include bi-directional reconstruction loss function and counter loss function . And 16 The same in , Our model consists of coders for each domain Ei And decoder Gi form . The potential code of each automatic encoder is divided into content code ci And style code si, among (ci,si)=(Eci(xi),Esi(xi))=Ei(xi). You can switch encoders - The encoder pair performs image to image conversion .
Two way reconstruction loss
Bidirectional reconstruction loss includes image reconstruction loss and potential reconstruction loss . The image reconstruction loss formula is as follows :
We should be able to reconstruct the image sampled from the data distribution after encoding and decoding .
The potential reconstruction loss formula is as follows :
Potential code in a given potential distribution ( Content and style ), We should be able to reconstruct it after decoding and encoding .
Confrontational loss
The adversarial loss formula is as follows :
To match the distribution between the translation domain and the target domain , We have adopted a countervailing loss .
The overall goal
The total loss formula is as follows :
边栏推荐
- Multipass Chinese document - share data with instances
- Create alicloud test instances
- 图像翻译/GAN:Unsupervised Image-to-Image Translation with Self-Attention Networks基于自我注意网络的无监督图像到图像的翻译
- dijkstra
- 微信小程序保存圖片的方法
- 做软件测试学历重要还是能力重要
- 2022.2.10
- 1.14 learning summary
- Multipass中文文档-与实例共享数据
- Sklearn Library -- linear regression model
猜你喜欢
![[H5 development] 03- take you hand in hand to improve H5 development - single submission vs batch submission with a common interface](/img/37/84b7d59818e854dac71d6f06700cde.jpg)
[H5 development] 03- take you hand in hand to improve H5 development - single submission vs batch submission with a common interface
![[H5 development] 01 take you to experience H5 development from a simple page ~ the whole page implementation process from static page to interface adjustment manual teaching](/img/e4/27611abdd000019e70f4447265808c.jpg)
[H5 development] 01 take you to experience H5 development from a simple page ~ the whole page implementation process from static page to interface adjustment manual teaching

1.11 learning summary

torchvision_ Transform (image enhancement)

Essential foundation of programming - Summary of written interview examination sites - computer network (1) overview

2.9 learning summary

Navicat connects the pit of shardingsphere sub table and sub library plug-ins

How can the intelligent transformation path of manufacturing enterprises be broken due to talent shortage and high cost?

Thinkphp6 implements a simple lottery system

Use of better scroll
随机推荐
天才制造者:独行侠、科技巨头和AI|深度学习崛起十年
Record a circular reference problem
2020-12-18
微信小程序保存图片的方法
Thymeleaf data echo, single selection backfill, drop-down backfill, time frame backfill
Dbeaver installation and configuration of offline driver
条件查询
Numpy data input / output
PowerShell runtime system IO exceptions
dijkstra
企业的产品服务怎么进行口碑营销?口碑营销可以找人代做吗?
How to use the configured slave data source for the scheduled task configuration class scheduleconfig
[H5 development] 03- take you hand in hand to improve H5 development - single submission vs batch submission with a common interface
2022.2.13
Multipass Chinese document - use packer to package multipass image
Multipass Chinese document - share data with instances
numpy 随机数
SixTool-多功能多合一代挂助手源码
Physical design of database design (2)
2021/11/6-burpsuit packet capturing and web page source code modification