当前位置:网站首页>Machine learning strong foundation program 0-4: popular understanding of Occam razor and no free lunch theorem
Machine learning strong foundation program 0-4: popular understanding of Occam razor and no free lunch theorem
2022-07-25 13:07:00 【Mr.Winter`】
Catalog
0 Write it at the front
The machine learning strong foundation program focuses on depth and breadth , Deepen the understanding and application of machine learning models .“ deep ” The mathematical principle behind the detailed derivation algorithm model ;“ wide ” In analyzing multiple machine learning models : Decision tree 、 Support vector machine 、 Bayesian and Markov decision 、 Strengthen learning, etc .
details : Machine learning strong foundation program
stay What is machine learning ? and AI What does it matter ? We mentioned in Machine learning is a means of studying how to calculate , The discipline of using experience generation models to improve the performance of the system itself . The core knowledge of data set is crosstalk , Construction method analysis Explained the data ( Experience ) Related concepts of , In this section, we discuss the idea of machine learning model .
1 Occam's razor principle
Models are also called truth hypothesis (hypothesis), Regardless of performance and accuracy , Several hypotheses about the truth can be obtained from the data set , The set of all assumptions is called Hypothetical space (hypothesis space).
Once the representation of a hypothesis or model is determined , Assume that the space and its size are immediately determined .

The set of hypotheses in the hypothesis space that conform to the training set pattern is called Version space (version space). Because all assumptions of version space lead to the correct conclusion about the training set data , Therefore, this equivalence will cause the output uncertainty of machine learning algorithm —— Possible version space assumptions A Judge that the new sample is a positive example and assume B Judge as a counterexample .
Therefore, any effective machine learning algorithm must tend to choose certain assumptions in version space , be called Generalize preferences (inductive bias), Inductive preferences can be seen as heuristics to perform a search on the hypothesis space .
The above concept is a little abstract , Old rules , Let's take an example .
There is such a series of data samples on the two-dimensional plane , We need to build a model , Find the pattern of the data
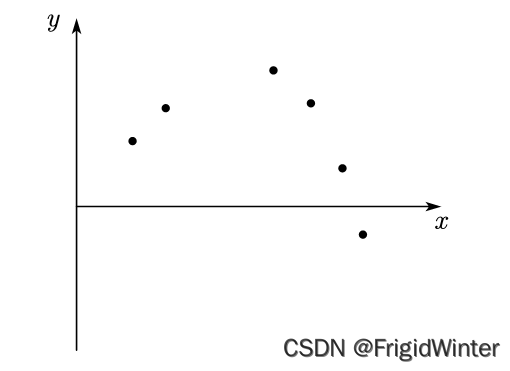
We might as well choose a model form , Set as polynomial model
y = ∑ i = 0 n a i x i y=\sum_{i=0}^n{a_ix^i} y=i=0∑naixi
Then we call all polynomial functions to form the assumption space of the problem , Suppose that there are many curves in the space that conform to the law of sample distribution to form the version space , Like the following

We can think that these different curves are the models of this data set , Based on these models, we can predict .
But in the end, we can't submit so many models to users to choose by themselves , So it leads to the inductive preference introduced before , We must have a preference for a certain model , To decide what model to ultimately adopt
Occam's razor principle It's an inductive preference , It provides direction for our decision model , In a word :
That is, if there are multiple assumptions consistent with observation , Choose the simplest one .
In this case , We can choose the curve with the lowest polynomial degree as the final model

2 There is no such thing as a free lunch
There is no free lunch to teach us Everything has a price The truth . So in machine learning No free lunch theorem What are you talking about ?
give an example : There's an algorithm A, One of its properties , For example, the calculation speed increases , Get the algorithm B; There must be another performance degradation , For example, the storage occupation increases . Algorithm A and B Which good ?
You can say Algorithm A Ratio algorithm B Better ? You can't , Because in the scenario that requires high computing speed B good , In scenarios with high storage requirements A good . Therefore, the performance improvement between algorithms has to pay a price , And the algorithm performance comparison cannot be divorced from the practical significance .
Now we formally give the specific content of the no free lunch theorem : When the probability of all problems is the same , The expected performance between any two algorithms is the same .
Let's simply prove this theorem .
Suppose the sample space is X \mathcal{X} X, The training set is X X X, Then the test set is X − X \mathcal{X}-X X−X, The probability of sample occurrence is recorded as P ( x ) P\left( \boldsymbol{x} \right) P(x). Set the algorithm as L \mathfrak{L} L, How do we measure the performance of this algorithm ? It can be calculated by the prediction error on the test set
E o t e ( L ∣ X , f ) E_{ote}\left( \mathfrak{L} |X, f \right) Eote(L∣X,f)
among f f f It is an objective model in the sample space that does not take human will as the transfer , The above formula translates directly into : Given the objective sample space and limited training set , Get the expected performance of the algorithm .
We use the full probability formula to expand
E o t e ( L ∣ X , f ) = ∑ h ∑ x ∈ X − X P ( x ) ℓ ( h ( x ) ≠ f ( x ) ) P ( h ∣ X , L ) E_{ote}\left( \mathfrak{L} |X, f \right) =\sum_h{\sum_{\boldsymbol{x}\in \mathcal{X} -X}{P\left( \boldsymbol{x} \right) \ell \left( h\left( \boldsymbol{x} \right) \ne f\left( \boldsymbol{x} \right) \right) P\left( h|X, \mathfrak{L} \right)}} Eote(L∣X,f)=h∑x∈X−X∑P(x)ℓ(h(x)=f(x))P(h∣X,L)
among ℓ \ell ℓ Is the performance measurement function , h h h It is the model trained after the given algorithm and training set , ℓ ( h ( x ) ≠ f ( x ) ) \ell \left( h\left( \boldsymbol{x} \right) \ne f\left( \boldsymbol{x} \right) \right) ℓ(h(x)=f(x)) It is the cost when the model prediction is not equal to the real situation .
Review the example above , There may be some problems in reality that require high computing speed , Some require high storage performance , let me put it another way , All problems are possible , And the probability of occurrence is the same , Therefore, the sample space for each problem is f f f There are also several equal possibilities , We sum these possibilities ( That is to expect )
∑ f E o t e ( L ∣ X , f ) = ∑ f ∑ h ∑ x ∈ X − X P ( x ) ℓ ( h ( x ) ≠ f ( x ) ) P ( h ∣ X , L ) \sum_f{E_{ote}\left( \mathfrak{L} |X, f \right)}=\sum_f{\sum_h{\sum_{\boldsymbol{x}\in \mathcal{X} -X}{P\left( \boldsymbol{x} \right) \ell \left( h\left( \boldsymbol{x} \right) \ne f\left( \boldsymbol{x} \right) \right) P\left( h|X, \mathfrak{L} \right)}}} f∑Eote(L∣X,f)=f∑h∑x∈X−X∑P(x)ℓ(h(x)=f(x))P(h∣X,L)
Change the order of integration
∑ f E o t e ( L ∣ X , f ) = ∑ x ∈ X − X P ( x ) ∑ h P ( h ∣ X , L ) ∑ f ℓ ( h ( x ) ≠ f ( x ) ) \sum_f{E_{ote}\left( \mathfrak{L} |X, f \right)}=\sum_{\boldsymbol{x}\in \mathcal{X} -X}{P\left( \boldsymbol{x} \right) \sum_h{P\left( h|X, \mathfrak{L} \right) \sum_f{\ell \left( h\left( \boldsymbol{x} \right) \ne f\left( \boldsymbol{x} \right) \right)}}} f∑Eote(L∣X,f)=x∈X−X∑P(x)h∑P(h∣X,L)f∑ℓ(h(x)=f(x))
Without losing generality, consider the problem of two classifications , be
∑ f ℓ ( h ( x ) ≠ f ( x ) ) = 1 2 ℓ ( h ( x ) ≠ f ( x ) ) + 1 2 ℓ ( h ( x ) = f ( x ) ) = σ \sum_f{\ell \left( h\left( \boldsymbol{x} \right) \ne f\left( \boldsymbol{x} \right) \right)}=\frac{1}{2}\ell \left( h\left( \boldsymbol{x} \right) \ne f\left( \boldsymbol{x} \right) \right) +\frac{1}{2}\ell \left( h\left( \boldsymbol{x} \right) =f\left( \boldsymbol{x} \right) \right) =\sigma f∑ℓ(h(x)=f(x))=21ℓ(h(x)=f(x))+21ℓ(h(x)=f(x))=σ
Is a fixed value .
The result is
∑ f E o t e ( L ∣ X , f ) = σ ∑ x ∈ X − X P ( x ) \sum_f{E_{ote}\left( \mathfrak{L} |X, f \right)}=\sigma \sum_{\boldsymbol{x}\in \mathcal{X} -X}{P\left( \boldsymbol{x} \right)} f∑Eote(L∣X,f)=σx∈X−X∑P(x)
Its performance has nothing to do with the algorithm itself .
Last , To sum up, there is no free lunch theorem : It's meaningless to talk about the advantages and disadvantages of learning algorithms out of specific application scenarios , Whether the inductive preference matches the current problem directly determines whether the algorithm can achieve good performance .
3 Ugly duckling Theorem
Ugly duckling Theorem Asked a question :
You think there is a big difference between the ugly duckling and the White Swan , Or is there a big difference between a white swan and another white swan ?
From the perspective of morphology , There is a big difference between the ugly duckling and the White Swan ; From a genetic perspective , There is a big difference between a white swan and another white swan !
What does this ?
It shows that it is impossible for computers to perform machine learning tasks for us automatically and objectively , We must set a standard for it , For example, in the ugly duckling problem , The standard is morphological comparison or genetic comparison . As long as the criteria are introduced , It must be subjective .
Therefore, no judgment in this world can be completely fair without discrimination .
In machine learning , Any algorithm has its subjectivity , Therefore, there is always room for improvement in the grasp of objective laws .
边栏推荐
- Clickhouse notes 03-- grafana accesses Clickhouse
- Microsoft proposed CodeT: a new SOTA for code generation, with 20 points of performance improvement
- Business visualization - make your flowchart'run'(3. Branch selection & cross language distributed operation node)
- CONDA common commands: install, update, create, activate, close, view, uninstall, delete, clean, rename, change source, problem
- MySQL remote connection permission error 1045 problem
- Perf performance debugging
- 弹性盒子(Flex Box)详解
- Ministry of Public Security: the international community generally believes that China is one of the safest countries in the world
- What is ci/cd?
- A turbulent life
猜你喜欢

yum和vim须掌握的常用操作

【视频】马尔可夫链原理可视化解释与R语言区制转换MRS实例|数据分享
![[review SSM framework series] 15 - Summary of SSM series blog posts [SSM kill]](/img/fb/6ca8e0eb57c76c515e2aae68e9e549.png)
[review SSM framework series] 15 - Summary of SSM series blog posts [SSM kill]

485 communication (detailed explanation)
零基础学习CANoe Panel(16)—— Clock Control/Panel Control/Start Stop Control/Tab Control
![[problem solving] ibatis.binding BindingException: Type interface xxDao is not known to the MapperRegistry.](/img/00/65eaad4e05089a0f8c199786766396.png)
[problem solving] ibatis.binding BindingException: Type interface xxDao is not known to the MapperRegistry.
cv2.resize函数报错:error: (-215:Assertion failed) func != 0 in function ‘cv::hal::resize‘
![[operation and maintenance, implementation of high-quality products] interview skills for technical positions with a monthly salary of 10k+](/img/d8/90116f967ef0f5920848eca1f55cdc.png)
[operation and maintenance, implementation of high-quality products] interview skills for technical positions with a monthly salary of 10k+

程序的内存布局

“蔚来杯“2022牛客暑期多校训练营2 补题题解(G、J、K、L)
随机推荐
JS 中根据数组内元素的属性进行排序
Selenium uses -- XPath and analog input and analog click collaboration
Want to go whoring in vain, right? Enough for you this time!
MySQL remote connection permission error 1045 problem
【历史上的今天】7 月 25 日:IBM 获得了第一项专利;Verizon 收购雅虎;亚马逊发布 Fire Phone
[advanced C language] dynamic memory management
AtCoder Beginner Contest 261 F // 树状数组
How to use causal inference and experiments to drive user growth| July 28 tf67
零基础学习CANoe Panel(15)—— 文本输出(CAPL Output View )
CONDA common commands: install, update, create, activate, close, view, uninstall, delete, clean, rename, change source, problem
Migrate PaloAlto ha high availability firewall to panorama
Chapter5 : Deep Learning and Computational Chemistry
Eccv2022 | transclassp class level grab posture migration
【视频】马尔可夫链原理可视化解释与R语言区制转换MRS实例|数据分享
状态(State)模式
零基础学习CANoe Panel(16)—— Clock Control/Panel Control/Start Stop Control/Tab Control
【AI4Code】《CodeBERT: A Pre-Trained Model for Programming and Natural Languages》 EMNLP 2020
[problem solving] org.apache.ibatis.exceptions PersistenceException: Error building SqlSession. 1-byte word of UTF-8 sequence
零基础学习CANoe Panel(13)—— 滑条(TrackBar )
Selenium use -- installation and testing