当前位置:网站首页>Auto encoder
Auto encoder
2022-06-28 23:36:00 【Programming bear】
One 、 Principle of self encoder
Self - encoder algorithm belongs to self - supervised learning , If the algorithm put x Learn as a supervisory signal , The algorithm here is called self supervised learning (Self-supervised Learning)
The function of neural networks in supervised learning : .
. Is the length of the input eigenvector ,
Is the length of the input eigenvector , Is the vector length of the network output . For the classification problem , The network model takes the length as Input eigenvector 𝒙 Transform to length Of Output vector 𝒐, This process can be regarded as the process of feature dimension reduction , Input the original high-dimensional vector 𝒙 Transform to low dimensional variables 𝒐.
Is the vector length of the network output . For the classification problem , The network model takes the length as Input eigenvector 𝒙 Transform to length Of Output vector 𝒐, This process can be regarded as the process of feature dimension reduction , Input the original high-dimensional vector 𝒙 Transform to low dimensional variables 𝒐.
Feature dimension reduction (Dimensionality Reduction) It is widely used in machine learning , Such as file compression (Compression)、 Data preprocessing (Preprocessing) etc. . The most common dimensionality reduction algorithms are Principal component analysis (Principal components analysis, abbreviation PCA), The main components of the data are obtained by characteristic decomposition of the covariance matrix , however PCA It is essentially a linear transformation , The ability to extract features is extremely limited
Use the powerful nonlinear expression ability of neural network to learn the low dimensional data representation , But training neural networks usually requires an explicit label data ( Or supervisory signals ), But the unsupervised data has no additional annotation information , Only data 𝒙 In itself
Using data 𝒙 It is used as a monitoring signal to guide the training of neural network , That is, we hope that the neural network can learn to map  : 𝒙 → 𝒙.
: 𝒙 → 𝒙.

Put the Internet Cut into two parts , The previous sub networks try to learn the mapping relationship : : 𝒙 → 𝒛, The latter sub network tries to learn the mapping relationship
: 𝒙 → 𝒛, The latter sub network tries to learn the mapping relationship  : 𝒛 → 𝒙. hold Think of it as a Data encoding (Encode) The process of , Input the high dimension 𝒙 Encoded as low dimensional implicit variables 𝒛(Latent Variable, Or hide variables ), be called Encoder The Internet ( Encoder ); as Data decoding (Decode) The process of , Put the encoded input 𝒛 Decode to high dimensional 𝒙, be called Decoder The Internet ( decoder )
: 𝒛 → 𝒙. hold Think of it as a Data encoding (Encode) The process of , Input the high dimension 𝒙 Encoded as low dimensional implicit variables 𝒛(Latent Variable, Or hide variables ), be called Encoder The Internet ( Encoder ); as Data decoding (Decode) The process of , Put the encoded input 𝒛 Decode to high dimensional 𝒙, be called Decoder The Internet ( decoder )
The encoder and decoder work together to complete the input data 𝒙 The encoding and decoding process , Put the whole network model be called Automatic encoder (Auto-Encoder), Self encoder for short . If you use a deep neural network to parameterize and function , It is called depth self encoder (Deep Auto-encoder)
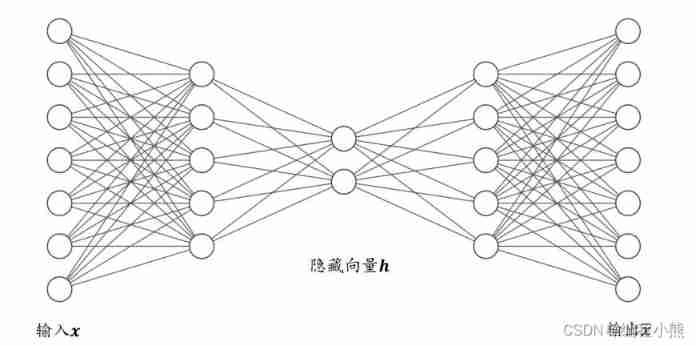
The self encoder can transform the input into a hidden vector 𝒛, And reconstruct by decoder (Reconstruct, Or recovery ) Out 𝒙. The output of the decoder can perfectly or approximately restore the original input , namely 𝒙 ≈ 𝒙, The optimization goal of self encoder : , dist(𝒙, 𝒙) Express 𝒙 and
, dist(𝒙, 𝒙) Express 𝒙 and  Distance measure of , It is called reconstruction error function . The common measurement method is the square of Euclidean distance , The calculation method is as follows :ℒ = ∑(𝑥𝑖 - 𝑥̅𝑖)2
Distance measure of , It is called reconstruction error function . The common measurement method is the square of Euclidean distance , The calculation method is as follows :ℒ = ∑(𝑥𝑖 - 𝑥̅𝑖)2
It is equivalent to mean square error principle . There is no essential difference between self encoder network and ordinary neural network , Just the training supervision signal by the tag 𝒚 Become yourself 𝒙. With the help of the nonlinear feature extraction ability of deep neural network , The self encoder can obtain good data representation , be relative to PCA Equilinear method , The self encoder has better performance , It can even recover the input more perfectly 𝒙
Two 、 Multiple self encoders
The training of self encoder network is stable , However, the loss function directly measures the distance between the reconstructed sample and the underlying features of the real sample , Instead of evaluating the fidelity and diversity of the reconstructed samples , Therefore, the effect on some tasks is average , Such as image reconstruction , It is easy to get blurred edges of reconstructed images , There is still a big gap between the fidelity and the real picture . In order to try to make the self encoder learn the true distribution of data , A series of self encoder variant networks have been produced
1.Denoising Auto-Encoder
In order to prevent the neural network from memorizing the underlying characteristics of the input data , Denoising Auto-Encoders Input data for Add random noise disturbance , For example, input 𝒙 Add noise sampled from Gaussian distribution 𝜀: , After adding noise , The network needs to start from
, After adding noise , The network needs to start from  Learn the real hidden variables of data z, And restore the original input 𝒙
Learn the real hidden variables of data z, And restore the original input 𝒙
2.Dropout Auto-Encoder
Dropout Auto-Encoder Reduce the expressive power of the network by randomly disconnecting the network , Prevent over fitting , Through the network layer , Insert Dropout Layer can realize random disconnection of network connection
3.Adversarial Auto-Encoder
In order to be able to conveniently from In a known prior distribution 𝑝(𝒛) Sampling hidden variables 𝒛, utilize 𝑝(𝒛) To reconstruct the input , Against self encoder (Adversarial Auto-Encoder) Using an additional discriminator network (Discriminator, abbreviation D The Internet ) To determine Hidden variables of dimension 𝒛 Whether to sample from a priori distribution 𝑝(𝒛), The output of the discriminator network belongs to [0,1] Interval variables , Indicates whether the hidden vector is sampled from a priori distribution 𝑝(𝒛): All samples are from a priori distribution 𝑝(𝒛) Of 𝒛 Mark true , Conditional probability of sampling from encoder 𝑞(𝒛|𝒙) Of 𝒛 Marked as false . Train in this way , In addition to reconstructing the sample , You can also constrain the conditional probability distribution 𝑞(𝒛|𝒙) Approximate a priori distribution 𝑝(𝒛).

The countermeasure self encoder is derived from the algorithm of generating countermeasure network
4.Variational AutoEncoders
The basic self encoder is essentially Learn to input 𝒙 And hidden variables 𝒛 Mapping between , It is a discriminant model (Discriminative model), It's not about generating models (Generative model).
Variational self encoder (Variational AutoEncoders,VAE): Given the distribution of hidden variables P(𝒛), If you can learn the conditional probability distribution P(𝒙|𝒛), Then through the joint probability distribution P(𝒙, 𝒛) = P(𝒙|𝒛)P(𝒛) sampling , Generate different samples 
From the perspective of neural networks , VAE Relative to the self encoder model , It also has two sub networks of encoder and decoder . The decoder accepts input 𝒙, The output is an implicit variable 𝒛; The decoder is responsible for converting the hidden variable 𝒛 Decode into reconstructed 𝒙. The difference is , VAE Model for implicit variables 𝒛 The distribution of has explicit constraints , I hope the implicit variable 𝒛 Conform to the preset a priori distribution P(𝒛). In the design of loss function , In addition to the original reconstruction error term , Implicit variables are also added 𝒛 Distributed constraints
In terms of probability , Suppose the data sets are all sampled from a distribution 𝑝(𝒙|𝒛), 𝒛 Is a hidden variable , Represents an internal characteristic , For example, pictures of handwritten numbers 𝒙, 𝒛 Can represent the font size 、 Writing style 、 In bold 、 Italics, etc , It conforms to a priori distribution 𝑝(𝒛), Hide variables in a given concrete 𝒛 Under the circumstances , You can learn from distribution 𝑝(𝒙|𝒛) A series of generated samples are sampled in , These samples all have 𝒛 The commonalities expressed
It's usually assumed that 𝑝(𝒛) Conform to the known distribution 𝒩(0,1). stay 𝑝(𝒛) Under known conditions , Hope to learn how to generate probability models 𝑝(𝒙|𝒛). Maximum likelihood estimation can be used here (Maximum Likelihood Estimation) Method : A good model , There should be a high probability of generating real samples 𝒙 ∈ 𝔻. If the generated model 𝑝(𝒙|𝒛) Yes, it is 𝜃 To parameterize , So the optimization goal of the neural network is : , because z Is a continuous variable , This integral cannot be converted to discrete form , Cannot optimize directly . Using variational inference , After a series of simplification VAE Model optimization objectives
, because z Is a continuous variable , This integral cannot be converted to discrete form , Cannot optimize directly . Using variational inference , After a series of simplification VAE Model optimization objectives  and
and ![max\mathbb{E}_{zq}[logp_{\theta }(x|z)]](http://img.inotgo.com/imagesLocal/202202/16/202202161300527691_7.gif) . among
. among 
The first optimization objective can be understood as constraining implicit variables 𝒛 The distribution of , The second optimization objective is to improve the network reconstruction effect
Implicit variables are sampled from the output of the encoder 𝑞 ( |𝑥), When 𝑞(z|𝑥) and 𝑝(z ) Assuming a normal distribution , The mean value of the normal distribution of the encoder output 𝜇 And variance 𝜎2, The input of the decoder is sampled from 𝒩(𝜇, 𝜎2). Due to the existence of sampling operation , The resulting gradient propagation is discontinuous , It is impossible to train end-to-end by gradient descent algorithm VAE The Internet
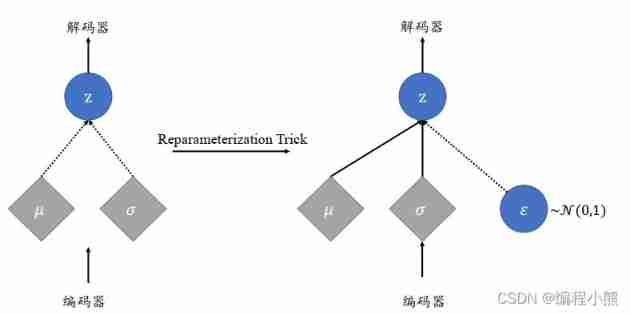
Reparameterization Trick( Reparameterization techniques ):

It passes through  The way Sampling implicit variables z,
The way Sampling implicit variables z, and
and  Is continuously differentiable , So as to connect the gradient propagation
Is continuously differentiable , So as to connect the gradient propagation
边栏推荐
- Serious internal entanglement in the we media industry: where should the enterprise we media go
- 收藏 | VLOOKUP函数的这些妙用你都知道吗?
- Count the number of arrays with pointers
- [mathematical modeling] fmincon() function of MATLAB nonlinear programming
- 2022年PMP项目管理考试敏捷知识点(4)
- Basic operation of MySQL database: import hellodb SQL and query as required; Create account and authorize
- Hesitating root sound
- IO playback function of FIO
- 移动端异构运算技术 - GPU OpenCL 编程(基础篇)
- 【状态机设计】Moore、Mealy状态机、三段式、二段式、一段式状态机书写规范
猜你喜欢

这样学习二叉树
![[matlab] function definition and use](/img/43/a7970ca8e075151277f7773434f7db.png)
[matlab] function definition and use

stm32F407-------寄存器地址名称映射分析

Chapter V virtual memory exercise

Cmake tutorial (I)

机器学习6-决策树

What pitfalls should be avoided in the job interview for the operation post in 2022?

window10 phpstudy 安装redis扩展

Machine learning 4-dimension reduction technology

ROS2中的行为树 BehaviorTree
随机推荐
VSCode里使用条件断点(基于GDB)
Huawei's level 22 experts have worked hard for ten years to complete the advanced practical document of cloud native service grid. 6
Thinking about lever
Learn binary tree like this
Implementation of dynamic timer for quartz
frameworks/base/core/res/res/values/symbols. Xml:3915: error: no definition for declared symbol solution
stm32F407-------RTC实时时钟
Langage C - analyse des mots
大三,不简单啊!
TDD and automated testing
Keil project, RTT cannot print after too many programs are written
Picture 64base transcoding and decoding
Scrapy使用xlwt实现将数据以Excel格式导出的Exporter
笔记
Is it safe to open a stock account on the Internet?
lock4j--分布式锁中间件--使用/实例
PHP利用CURL实现登录网站后下载Excel文件
stm32F407-------IO引脚复用映射
【OpenCV】—线性滤波:方框滤波、均值滤波、高斯滤波
Matlab learning notes (6) upsample function and downsample function of MATLAB