当前位置:网站首页>多线程初学
多线程初学
2022-06-23 08:49:00 【云杉木屋】
多线程初学
摘要:在Java核心技术的学习中我们学到过一个叫做线程的模块,在程序开发中离不开高并发和多线程,在此我们来好好研究一下线程与线程池的关系。线程池是面试的高频考点,在项目开发中使用线程池解决问题是一个亮点,而线程池的运行过程也是面试的重点。
第一部分 线程概念简单复习
1.线程的匿名对象创建方式
在今天(2022年6月17日)的学习之前,关于线程的创建我们只知道使用匿名类以及继承Thread类书写一个类进行线程创建的方法,但实际上关于线程的创建还存在一些其他的方法,在此首先整理一下传统的线程创建方法。
1.1.匿名类创建方法
非常经典简单的线程创建方法,可以方便的随手写一个线程出来,具体下发如下:
new Thread(){
public void run(){
for(int i = 0; i <= 100; i++){
System.out.println("See you cowboy Bebop!");
}
}.start();
}
这种写法的过程是:1.继承Thread类; 2.重写run方法; 3.调用start方法将线程加入到就绪队列中。这种写法简单边界,随手就可以起一个线程,但是其问题也存在不少,比如它没有句柄,因此一点启动我们就是失去了对它的控制,它的生命周期则完全交给了Java虚拟机来操纵,如果睡眠线程的消亡时间设定的很长,那么这种线程就会长期的停留在内存中进而消耗大量资源。
1.2.匿名类创建方法plus
这个方法是我再查资料的时候刚刚看到的,这种方法使用到了一个很重要的接口:Runnable,这个接口在之后要讲到的线程池中非常重要,现在我们先尝试书写这种匿名对象创建方法:
new Thread(new Runnable(){
public void run(){
for(int i = 0; i<= 100; i++){
System.out.println("See you cowboy Bebop!");
}
}
}).start();
这种写法的过程是:1.将Runnable接口的实现类传递给Thread类的构造方法; 2.实现Runnable接口的Run方法; 3.调用Thread类对象的start方法。
1.3.总结
我们称这种创建线程的方法为:匿名对象创建方法,这种创建线程的方法的好处在于,我们可以随时随地的创建线程,无需为了一个线程单开一个专门的线程类,但是缺点在于我们使用这种方式一次只能开一个线程,如果想要开一个内部逻辑相同的线程,我们只能再复制一份,就像这样:
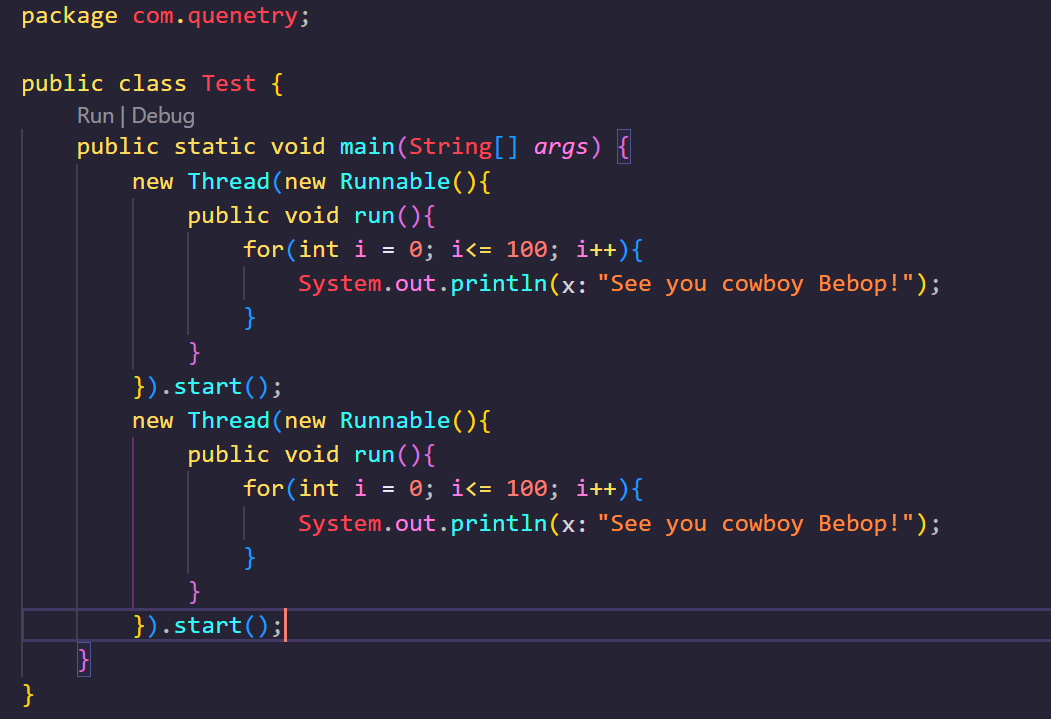
这种书写方式很奇怪,因为这里出现了两段完全相同的代码,但是却没有报错,这是因为我们使用的是匿名对象,两段相同的代码只是对象的逻辑,而不是句柄,在内部二者的实体实际上是可区别的。但是使用这种方法我们总觉得怪怪的,并且匿名对象创建线程的另一个缺点是我们一旦让它们跑起来,就完全将它们对系统托管了,之后再也无法管理它们,因此我们在大部分情况下很少使用这种方式进行线程的创建。
2.继承Thread类的线程创建方式
现在我们来研究一个更加具有普适化的线程创建方式,那就是继承Thread类来创建一个线程。在Java中存在各种接口以及抽象类,同时存在一种非常重要的概念,那就是龙生龙凤生凤,通俗的讲就是:想要成为某种东西,必须要继承某种东西,在Java中,想要成为线程类,继承Thread类是一个非常重要的方法,如下:

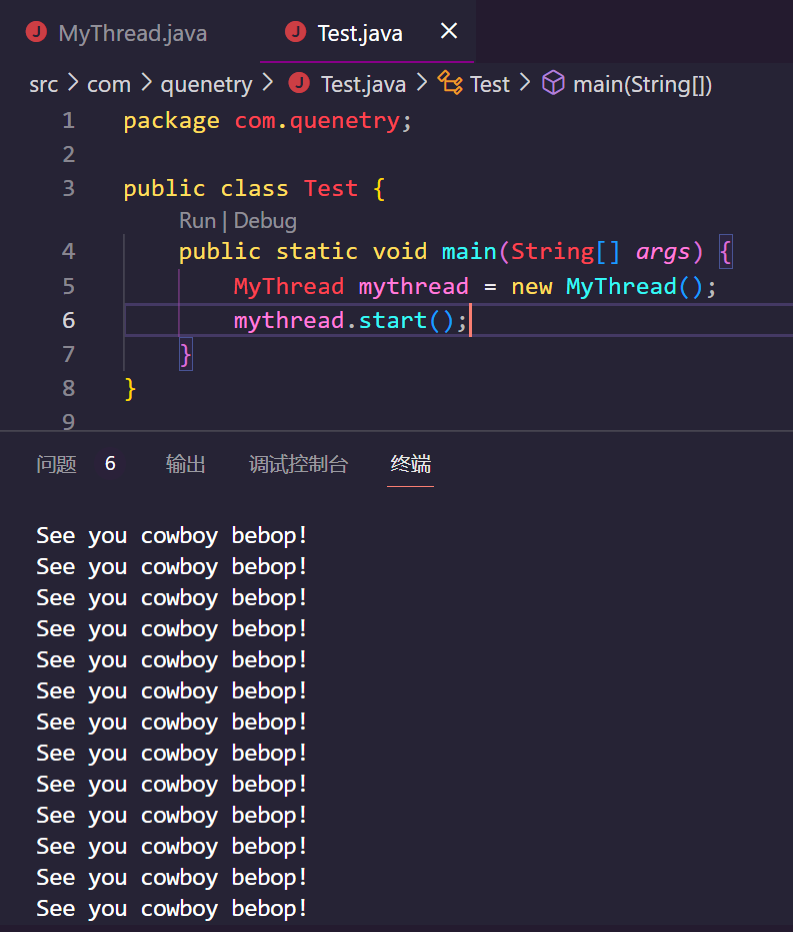
我们直接让一个自己书写的类继承了Thread类,然后重写了Thread的Run方法,之后我们使用.start()这个方法,仍然可以将这个线程加入到就绪队列中并被系统调度。
使用这种方法的好处在于我们创建了句柄,之后便可以通过句柄方便的调用这个线程,我们在主线程中可以根据自己的需求操控这个线程(这里属于线程的较高级运用,关于线程的操作这里暂时不做研究)。
3.实现接口的方式创建线程
这是最为重要的一种创建线程类的方式,关于实现接口创建线程,我们通常有两种方法,一种是实现Runnable接口,一种是实现Callable接口,两种接口都非常重要,因为实现了这两种接口的线程类可以作为线程池的任务注入参数。
3.1.实现Runnable接口

Runnable接口的实现非常简单,其内部只需要实现一个抽象方法Run,实现了这个抽象方法之后我们这个线程就已经可用了,如图所示:
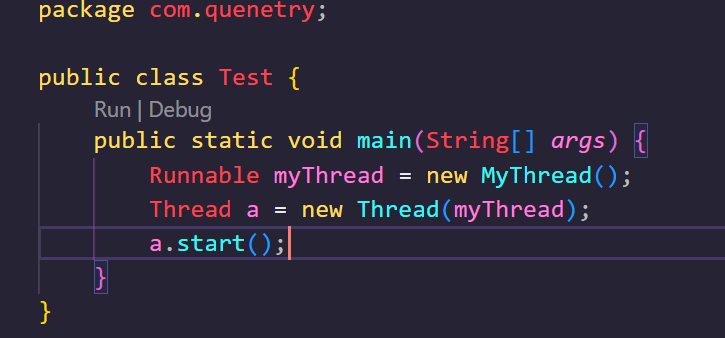
然而到这里事情已经发生了改变,我们之前在直接继承线程类的时候,直接实例化一个对象,就可以调用这个对象的.start()方法了,而使用接口的时候,我们不能直接调用,而是要将它作为一个参数传到一个Thread中,然后再调用这个Thread类的对象的.start()方法,这是不是很奇怪呢?在此我们先留一个疑问。
3.2.实现Callable接口

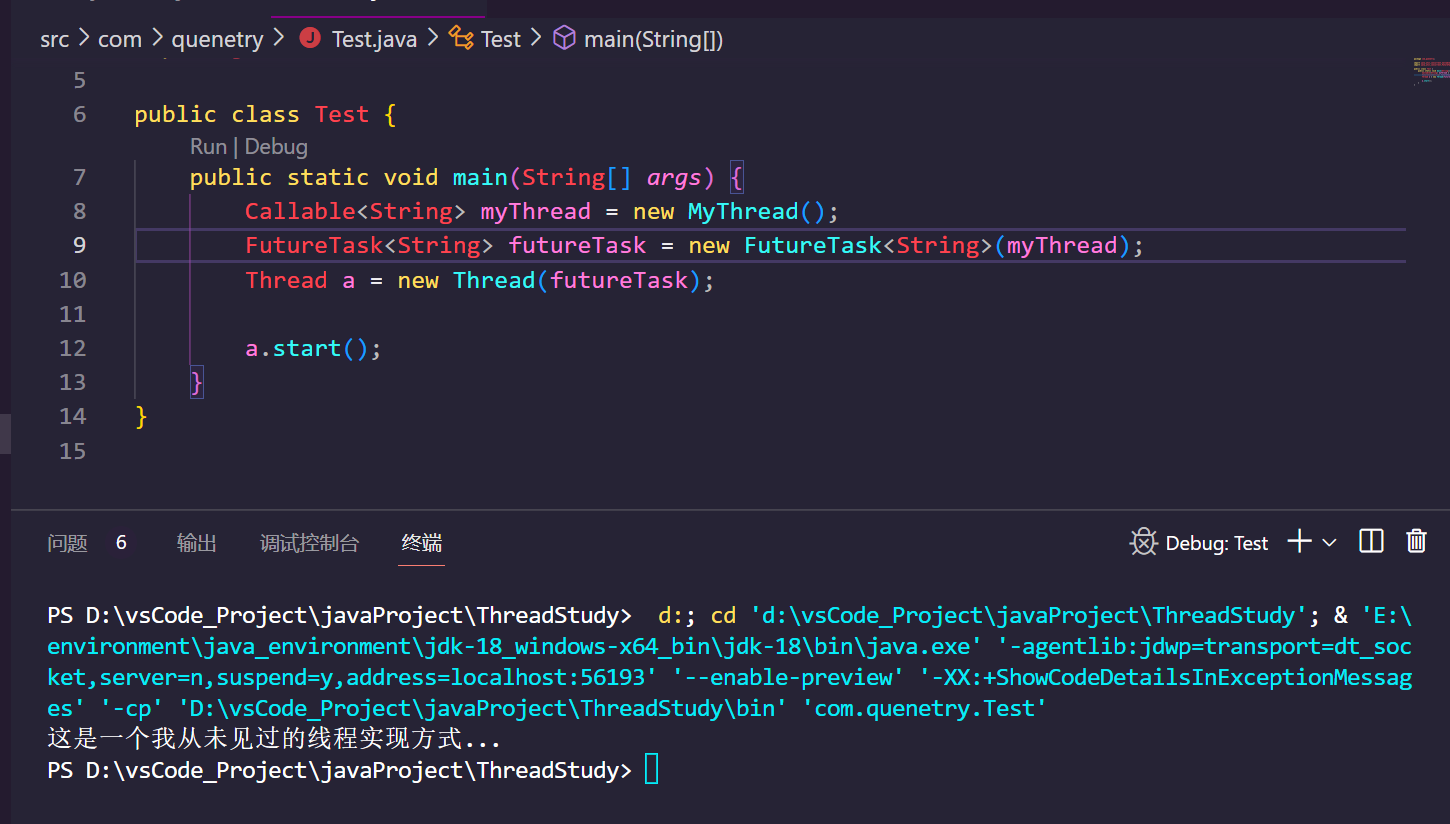
正如我打印出来的文字那样,这是我迄今为止见到的最为奇怪的一种线程实现方式,其内部实现的方法不再是Run方法,而是一个叫Call的方法,我们通过这种方法创建出来的类的对象和Runnable一样,不能直接作为一个线程来运行,而是要先加在一个叫FutureTask的类中,作为其入参生成一个FutureTask对象,然后将这个FutureTask对象作为一个参数加入在Thread类的对象中,最终使用Thread类来调用start方法,进行运行。
3.3.总结
目前我们暂时不深入探究这两种实现接口的线程创建方法,只是了解这两种方法的存在即可。我们需要注意的是实现了这两个接口的类实际上都不是严格意义上的线程类,因为直接实现这两个接口的类的实例并不能直接使用.start()方法,从某种角度上来看,这两个接口看上去更像是某种容器,它们的内部代码本质上是再靠多态,让别人执行,而不是自己执行。
在这里我们解答一下上面的一个问题:为什么这两个接口很重要?这是因为这两个接口都可以作为线程池的参数,我们可以通过这两个接口的实现类为线程池分配任务。
两个接口中定义的方法也存在些许不同,其中Runnable是一种看上去比较常规的方法,它内部的Run方法不带返回值,看上去和我们自己书写的Thread类中的Run方法非常像;Callable接口则需要定义一个泛型,这个泛型是其内部的call方法的返回值类型,而和普通的Run方法不一样的地方也显现出来了,那就是Callable的call方法有返回值。相当多的情况下,线程池的入参都是Callable的实现类。
第二部分 多线程理论基础
1.线程通信
线程与线程之间不总是毫不相关,各管各自的,它们有时会相互影响,发生信息交流,实际上有些情况下我们必须让线程有信息交流才能实现一个任务。实现线程通信的两个重要机制是:共享变量,线程管道,这两个机制需要我们作为重要知识点来记。
2.并发和并行
我们早在学习操作系统的时候就接触到了并发和并行的知识,这两种状态是完全不同的,比较通俗的解释是:并发是指两个线程通过交替运行,在一段时间之内,看上去仿佛是两个线程在同时运行;并行指的是这两个线程并没有交替运行,而是此时此刻真的在一起执行。通常情况下CPU的单核跑两个线程我们称之为并发;而两个核,每个核上跑一个线程,我们称这两个线程的状态为并行。
现在我们有一种更加文雅准确的说法:
1.并发:多个线程竞争同一资源
2.并行:线程之间互不干扰,没有重合的资源,不存在资源竞争关系
3.我们何时使用多线程?
需要注意的是有些情况下多线程不一定比单线程快,那么我们何时使用多线程呢?答案是当因为CPU因经常性的访问外接硬件,而导致的CPU空转时间增多,出现了大量的CPU浪费时,我们使用多线程,这样可以有效增加CPU的吞吐量,缩短总体的程序运行时间,防止CPU资源被浪费。
4.关于CPU的一个常识
我们得计算机中通常在每时每刻存在着大量的线程,通常情况下这些线程的数量是远远大于我们的计算机的核心数的

如图所示我计算机的核心数只有四个,有八个逻辑核,但是系统中此时此刻存在3000多个线程,这是怎么实现的呢?难道说CPU的一个核心可以同时运行好几百个线程吗?答案是否定的,CPU的一个核在同一时刻只能运行一个线程,实现这种效果的原因是一个处理单元通过快速切换,可以让少量核运行大量线程,说白了,在我的计算机中,每时每刻只有4个线程在真正的并发执行,因为逻辑核不能拯救一个处理单元只能运行一个线程的事实,这3000个线程,大部分实际上是在进行并发,而非并行。这些线程在一个处理器上快速切换,进而在一段时间内,看上去好像在同时执行。这里的基准速度指的就是CPU的频率,是CPU的单核速度。
在上图中,另一个参数是句柄,这个句柄就是当前系统中存在的变量,一个句柄是对应一个值的。
5.逻辑处理器是什么?
逻辑处理器是最早由英特尔开发出来的一种CPU内核虚拟技术,本质上就是以牺牲单核频率为代价,虚拟出两个核心,提升CPU的多线程问题处理能力,这种CPU的多核多线程能力会得到提升,但是单核处理问题的能力就会下降,如果当前运行的软件的多核优化没做好,即使这个CPU卖的很贵(如线程撕裂者或者志强),但是打穿越火线并不好,性能甚至还不如双核的老i3(i3默秒全)。
说实在的逻辑处理器并不能拯救一个CPU的总体性能,这只是英特尔挤牙膏恰烂钱的一种手段,实际上一个物理核只能是同一时刻只能执行一个线程,这是因为一个核心就是一个逻辑电路,一个逻辑电路在某一时刻上面只能是有一种电气状态,或者说人类的科技树导致电路问题的解决本身就是离散的,原子的,问题只能一个一个的解决,因此无论它再怎么虚拟,一个核心在某一时刻只能是跑一个线程,所以我们通常看到的所谓6核12线程,都是使用了这种虚拟化,其性能不见得一定强于6核6线程,至少是在某些时候。
6.大量的线程如何在少量的内核上运行?
同样的这属于操作系统的问题范畴,线程在内核上通常是存在某种调度策略的,这个问题主要是看系统软件了,有时间片轮转,优先级策略,先来先服务等等各种各样的调度策略,这个需要根据具体任务的总体情况加以分析,然后由操作系统决定。但是需要注意的是不管是哪种调度策略,在每次线程调度的时候,都是要花费内存来记录当前线程停止之前的状态的,这个肯定是消耗系统资源的,并且线程的切换会花费一定的时间,做好各种工作一边该线程的下次执行。
计算机额外做任何工作都是要消耗资源的,早进行线程的上下文切换时,其代价相当大,达到了一微秒,这是一个非常大的时间消耗,对于CPU来说,已经是漫长的等待了。
7.多线程一定优于单线程吗?
不一定,多线程和单线程本质上没有优劣之分,只有在哪种场景下合适,哪种场景下不合适这种情况。因为在多线程模式下往往会出现多个进程在一个核心上运行的情况,因此在多线程模式下少不了上下文切换这个机制,也就是物理核心对线程的调度,上下文切换这个东西是消耗内存且消耗CPU的,上面也提到了,一次上下文切换的时间大概在1毫秒左右,因此有时任务的总量单线程跑也就60毫秒就能跑完,但是加了多线程之后引入了上下文切换,这个任务可能需要70毫秒才能跑完,此时多线程就显得非常浪费了。在多线程中,上下文切换越频繁,其消耗越多。
**那什么时候多线程好,什么时候单线程好呢?**关于这个问题:当程序中存在大量对硬盘等外设的访问时,使用多线程更加方便,因为对外设的访问往往会消耗大量的时间,如对硬盘的访问等待时间达到了25毫秒,机械硬盘由于其机械的特性,比电信号慢的多,因此CPU如果干等的话会导致长时间空转,这是如果使用多线程的话,在CPU等待数据返回的时候可以让CPU先运行另一个线程,当这个线程执行到需要等到CPU的时候,另一个线程的数据已经返回了,这是CPU就可以接着运行,空转时间大大减少,项目的整体速度就快上来了。如果这时仍然使用单线程,那么CPU的空闲时间就很多,就会导致程序总体运行时间变长。
当程序中多是逻辑运算,很少存在对外设的访问时,使用单线程就比多线程快,因为这时基本上没有CPU对外设的等待时间,因此CPU本身就没有什么空闲的机会,程序一个接一个的运行就会很快,如果加上多线程中的上下文切换,就会额外的多处一些上下文切换的消耗时间,让CPU白白多出很多的空闲时间。
因此,任务之间没有互相的等待的情况下,单线程是比多线程快的;当任务之间存在很多相互等待或者让CPU等待的情况时,使用多线程更快。在程序设计中,我们要做的事情就是尽量减少算力浪费,也就是减少CPU空转的时间。
8.多线程的应用场景(面试点)
综上所述,多线程多用于存在CPU发出请求然后需要花时间等待的情况,因此多线程多用于大规模访问数据库,使用爬虫爬取大量数据并处理的情况。注意,在对数据库进行大规模访问时,CPU会经常等待硬盘的返回,这时会产生很多的等待时间,因此在这时使用多线程会比单线程快很多;在使用爬虫的时候,因为发出一次请求之后等待爬虫程序回应的过程也很漫长,因此在爬虫爬取网页的场景下,使用多线程也很快。
9.多线程提升性能的原理
当程序中存在CPU发出请求之后然后长时间等待的情况时,使用多线程,这样一来当程序在CPU中执行时,当发出请求命令之后,正逢另一个线程的请求值回来,这样CPU就无需空转,在等待返回值的时候先处理其他的返回值,于是这样就增加了吞吐量,提升了CPU的吞吐率,降低了CPU的空闲时间,进而降低了程序整体的运行时间,线程在跑起来之后会自行切换,或者说被操作系统调度,无需我们操心管理。
边栏推荐
- 6、 Web Architecture Design
- How can I handle the "unable to load" exception when easyplayer plays webrtcs?
- 528. Random Pick with Weight
- 高通9x07两种启动模式
- 3. Caller 服务调用 - dapr
- Deep analysis and Simulation of vector
- 【活动报名】SOFAStack × CSDN 联合举办开源系列 Meetup ,6 月 24 日火热开启
- Single core driver module
- 173. Binary Search Tree Iterator
- 6月《中國數據庫行業分析報告》發布!智能風起,列存更生
猜你喜欢
636. Exclusive Time of Functions
通信方式总结及I2C驱动详解

Testing -- automated testing selenium (about API)

Point cloud library PCL from introduction to mastery Chapter 10
![[event registration] sofastack × CSDN jointly held the open source series meetup, which was launched on June 24](/img/e1/97c92290a2a5e68f05cdbd5bf525e8.png)
[event registration] sofastack × CSDN jointly held the open source series meetup, which was launched on June 24

点击添加下拉框

Linux MySQL installation

Object. Defineproperty() and data broker
Geoserver添加mongoDB数据源

Qualcomm 9x07 two startup modes
随机推荐
【云原生 | Kubernetes篇】Kubernetes原理与安装(二)
1、 Software architecture evaluation
USB peripheral driver - debug
【学习资源】理解数学和热爱数学
Quartz Crystal Drive Level Calculation
986. Interval List Intersections
Batch generation of code128- C barcode
Third party payment in the second half: scuffle to symbiosis
The results of CDN node and source station are inconsistent
Community article | mosn building subset optimization ideas sharing
Leetcode topic analysis count primes
Single core driver module
kernel log调试方法
Flink error --caused by: org apache. calcite. sql. parser. SqlParseException: Encountered “time“
@Response
2022-06-22:golang选择题,以下golang代码输出什么?A:3;B:1;C:4;D:编译失败。
Tencent cloud arm server evaluation practice
How to use the template library of barcode label software
GeoServer adding mongodb data source
Implementing an open source app store with swiftui