当前位置:网站首页>多模态 —— Learnable pooling with Context Gating for video classification
多模态 —— Learnable pooling with Context Gating for video classification
2022-06-29 06:37:00 【只会git clone的程序员】
前言
这是视频理解的一篇paper,说是多模态的原因主要是该结构结合了视频embedding,音频embedding等特征做视频分类,可以说就是多模态融合了。
注:该paper赢得了Youtube 8M Kaggle Large-Scale Video understading比赛冠军,比赛地址:传送门.
系列文章
更新中…
动机
比赛类的文章好像没有什么动机的说法?看了下简介感觉基本都是受到别的paper的启发,然后试试某个结构在这个领域的效果,发现work了就拿来用了。
- 比赛提供了视频对应的图像帧特征,以及音频特征,因此本文不在特征提取部分做贡献
- 基于上一条,本文主要在特征融合的方向上作贡献,以往的方法主要用LSTM或者GRU对时序特征进行建模,还有些其他方法不对时序建模的话就直接用简单的sum、meam或者复杂一些的BOW、VLAD等来表征整体序列特征的融合特征。本文作者主要承接BOW、VLAD等方法来研究特征融合。
- 受到LSTM、GRU的门控单元的启发,作者设计一种视频分类架构,将非时间聚合与门控机制相结合,就是后文中的context gating层。
结构
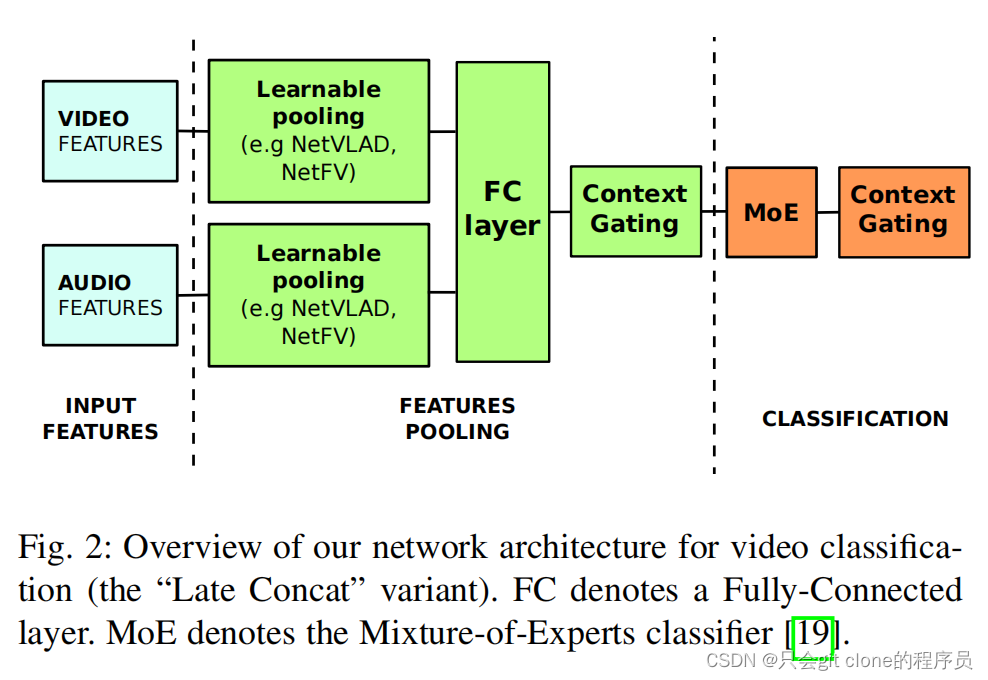
完整的结构很简洁,为了方便理解,本文模块化的介绍论文结构,先介绍整体的结构最后再介绍各个模块的具体实现。
1、首先是浅蓝色的video features,可以理解是比赛提供的视频抽帧的图像特征,比如一个视频固定抽10帧,然后假设用比较典型的resnet50抽图像特征一般就是2048维度的向量,所以可以理解图示的video features就是一个(10,2048)的特征。
2、audio features应该一般就是将整个音频转成了embedding,有时候音频比较长可能会分几段抽特征,假设分了5段,每段音频抽得到的特征纬度1024,所以就得倒(5,1024)的特征。
3、绿色的learnable pooling部分,就是在动机中提到的作者尝试了多种特征融合的方法,比如有BOW,VLAD,NetVLAD等,这个模块的输入是(N,D)的形状,输出是(1,d)的形状,小写的d是因为输入输出的纬度不一定相等可以是任意维度,就是把N个特征融合成了1个的意思。
4、因此从图像特征的pooling模块拿到的(1,d_v)的特征和音频特征的pooling模块拿到的(1,d_a)的特征在最后一个纬度进行concat操作得到视频和音频的融合特征(1,d_a+d_v)。
5、这个concat的特征送到图中绿色的FC layer中,这个FC layer看了下作者的源码就是一层全连接层加BN层以及激活函数(FC+BN+relu6)。
6、接下来送到context Gating层中,这就是抄的GLU的门控层,原文:作者希望在输入表示的激活之间引入非线性相互作用。其次,希望通过自动门控机制重新校准的输入的不同激活值。 人话:用激活函数来选择多少输入特征需要保留。
7、出了context Gating后送入到MOE中,MOE可以简单的理解用输入对不同的expert的输出做加权。
8、MOE输出又接了一个context Gating。
9、最后输出的特征拿来分类并计算loss。
我实现的结构代码示例:
基本就是1:1按照论文结构实现的。
模块详解
NetVLAD
这两个讲的比较清楚了:
1、知乎NetVLAD
2、论文笔记:NetVLAD: CNN architecture for weakly supervised place recognition
FC层
直接上代码了:
self.MLP = nn.Sequential(
nn.Linear(in_dim, out_dim),
nn.BatchNorm1d(out_dim),
nn.ReLU6()
)
context gating
上公式:
X是输入的特征,WX+b就是将X送到一个全连接层,f就是非线性函数,比如说sigmoid或者relu等,作者用的是sigmoid。
MOE

MOE就是将输入送入n个expert,每个expert的结构一样但是参数不一样,就可以得到n个输出了,然后用输入经过一个全连接层输出是n个分数对n个experts的输出做加权得到最后的输出。
class Expert_model(nn.Module):
def __init__(self, input_size, output_size, hidden_size):
super(Expert_model, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
self.relu = nn.ReLU()
self.log_soft = nn.LogSoftmax(1)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
out = self.log_soft(out)
return out
class MOE(nn.Module):
def __init__(self, input_size, output_size, expert_num, hidden_size=64):
super().__init__()
self.input_size = input_size
self.output_size = output_size
self.expert_num = expert_num
self.hidden_size = hidden_size
self.experts = nn.ModuleList(
[Expert_model(self.input_size, self.output_size, self.hidden_size) for i in range(self.expert_num)])
self.w_gate = nn.Linear(self.input_size, self.expert_num)
def forward(self, x):
# 我喜欢加一个sigmoid将gate的输出回归到0-1之间,可以防止梯度消失
gate_weight = self.w_gate(x).sigmoid().softmax(dim=-1) # bs, expert_num
expert_outputs = [self.experts[i](x) for i in range(self.expert_num)]
expert_outputs = torch.stack(expert_outputs) # expert_num, bs, dim
gate_weight_expert = torch.einsum("bn,nbd->bd", gate_weight, expert_outputs)
return gate_weight_expert
实验
以上就是论文的完整结构,实验结果有一些提升,但是发现一个比较严重的现象根据训练和验证的loss变化发现这个结构特别容易过拟合。
因此尝试了在MOE的FC层后面加dropout层,以及其他的一些FC层后加Dropout层都是有效的,比较明显的拟制了过拟合,并且指标还有一定的涨幅~
边栏推荐
- Analysis on the wave of learning robot education for children
- Failure: unable to log in to "taxpayer equity platform"
- Mongostat performance analysis
- 力扣每日一题-第30天-594.最长和谐子序列
- 消息队列之通过队列批处理退款订单
- 目标检测——使用yolov6进行视频推理
- 关于 localStorage 的一些高阶用法
- National Defense University project summary
- I would like to ask what securities dealers recommend? Is it safe to open an account online?
- Idea use
猜你喜欢
Pointer from beginner to advanced (2)

Exclusive download. Alibaba cloud native brings 10+ technical experts to bring new possibilities of cloud native and cloud future

Linux Installation redis
关于DDNS

Chapter IV introduction to FPGA development platform

消息队列之通过幂等设计和原子锁避免重复退款

Qt 程序打包发布-windeployqt工具
![[deep learning] - maze task learning I (to realize the random movement of agents)](/img/c1/95b476ec62436a35d418754e4b11dc.jpg)
[deep learning] - maze task learning I (to realize the random movement of agents)

Qt QFrame详解

二叉树的迭代法前序遍历的两种方法
随机推荐
Principle of screen printing adjustment of EDA (cadence and AD) software
关于DDNS
jetson tx2
Idea use
Antd work item memo w3.0
Qt 串口编程
Li Kou daily question - day 30 -1281 Difference of sum of bit product of integer
2022.02.15 - SX10-31. House raiding III
Qt 容器类
【OSPF引入直连路由时巧借静态黑洞路由做汇总】
Hyperledger Fabric 2. X custom smart contract
Part 63 - interpreter and compiler adaptation (II)
Json tobean
Antlr4 recognizes the format of escape string containing quotation marks
List collection implements paging
Chapter V online logic analyzer signaltap
Introduction to Ceres Quartet
Move disassembly of exclusive delivery of script (the first time)
How to fix Error: Failed to download metadata for repo ‘appstream‘: Cannot prepare internal mirrorli
施工企业选择智慧工地的有效方法