当前位置:网站首页>Introduction to superresolution
Introduction to superresolution
2022-07-04 01:19:00 【Programmer base camp】
Common data set
BSDS300、BSDS500、DIV2K、General-100、L20、Manage109、OutdoorScene、PIRM、Set5、Set14、T91、Urban100
Image evaluation
- PSNR: Compare pixel by pixel
- SSIM: Pay attention to overall comparison , From the contrast 、 brightness 、 Structure independent comparison
- MOS: Average subjective opinion score
Operation channel
- RGB
- YCBCr
Super resolution method with supervised learning
Pre-upsampling SR
reason : It is difficult to directly learn the mapping between low resolution images and high resolution images
Model :SRCNN、VDSR、DRRN
innovation : For the first time to use pre-upsampling SR operation , First pair LR Take samples , Make the image size after up sampling and HR identical , Then learn their mapping relationship , Greatly reduce the difficulty of learning
shortcoming : Pre sampling will cause noise amplification and blur , Calculation is carried out in high-dimensional space , More time and space costs
structure :

Post-upsampling SR
reason : Computing in low dimensions can improve computing efficiency , So first calculate in the low dimension , Perform up sampling at the end of the network
Model :FSRCNN、ESPCN
innovation : Because the feature extraction process with huge computational cost only occurs in low dimensional space , It greatly reduces the amount of computation and space complexity , This framework has also become one of the most mainstream frameworks
shortcoming : In the super fractional scale factor Scale In larger cases , It is difficult to learn
structure :

Progressive upsampling SR Progressive upsampling super-resolution
reason : When the amplification factor is large , Use the above b The method is very difficult ; And for different amplification factors , Need to train a separate SR A network model , Can not meet the multi-scale SR The needs of
Model :LapSRN
innovation : Cascade based CNN structure , Gradually reconstruct high-resolution images . Break down difficult tasks , Reduce the difficulty of learning . If you want to 4 times SR, Then go ahead 2 times SR, stay X2_SR Based on 4 times SR
shortcoming : The model design is complex 、 Poor training stability 、 We need more modeling guidance and advanced training strategies
structure :

Iterative up-and-down sampling SR Up and down sampling iterative super-resolution
reason : To better capture LR-HR Direct interdependence , Back projection is introduced
Model :DBPN
innovation : Connect the upper sampling layer and the lower sampling layer alternately , And use all intermediate processes to rebuild the final HR result , It can be well excavated LR-HR The deep relationship between image pairs , So as to improve the reconstruction effect
shortcoming : The back projection design standard is not clear , It has great exploration potential
structure :

Up sampling method
- Interpolation based upsampling : Nearest neighbor interpolation 、 Bilinear interpolation 、 Bicubic interpolation
- Learning based upsampling : Transposition convolution 、 Subpixel convolution
Network design
Residual learning
| Global residual learning | The input image is highly correlated with the target image , Therefore, we can only learn the residuals between them , This is global residual learning | (a) It can avoid learning the complex transformation from a complete image to another image , Instead, you only need to learn a residual graph to recover the lost high-frequency details (b) Because the residuals in most areas are close to zero , The complexity and learning difficulty of the model are greatly reduced |
|---|---|---|
| Local residual learning | Be similar to ResNet Residual learning in ,shortcut Connectivity can be used to alleviate model degradation caused by increasing network depth , It reduces the difficulty of training |  Such as SRGAN、RCAN And so on Such as SRGAN、RCAN And so on |
Recursive learning
reason : In order to learn more advanced features without introducing too many parameters , Apply the same module many times in a recursive manner to achieve super-resolution tasks
shortcoming : High computing costs cannot be avoided , There is the problem of gradient disappearance or explosion , It is often combined with residual learning and multiple supervised learning
Model :DRCN、MEMNet、CARN、DSRN
structure :

Multipath learning
Concept : Refers to the transfer of features through multiple paths , Each path performs different operations , Integrate their operation results to provide better modeling ability
| Global multipath learning | Use multiple paths to extract the features of different aspects of the image , These paths can cross each other in the process of propagation , So as to greatly improve learning ability |  | LapSRN、DSPN |
|---|---|---|---|
| Local multipath learning | The input is fused after feature extraction of different paths |  | CSNLN |
| Multi-path learning at a specific scale | Different scales of SR The model needs to undergo similar feature extraction , So they share the network layer of the model for feature extraction , At the beginning and end of the network, a specific proportion of preprocessing structure and up sampling structure are added . During training, only modules corresponding to the selected proportion are enabled and updated |  | MDSR、CARN、ProSR |
Dense connections
principle : For each layer in a dense block , Take all the characteristic diagrams of the previous layer as input , And transfer its own characteristic graph as input to all subsequent layers
advantage : Dense connections not only help reduce gradient disappearance 、 Enhance signal propagation and encourage feature reuse , But also through the use of small growth rates ( That is, the number of channels in the dense cluster ) And compressing the number of channels after connecting all input feature maps to significantly reduce the size of the model .
Model :
structure :

Attention mechanism
principle : Considering the interdependence of features between different channels to improve the learning ability of the network
Model :
Image Super-Resolution Using Very Deep Residual Channel Attention Networks
Second-Order Attention Network for Single Image Super-Resolution
Image Super-Resolution With Cross-Scale Non-Local Attention and Exhaustive Self-Exemplars Mining
Advanced convolution
Expansion convolution ( Cavity convolution )、 Grouping convolution 、 Deep separation convolution
Loss function
Pixel level loss pixel Loss
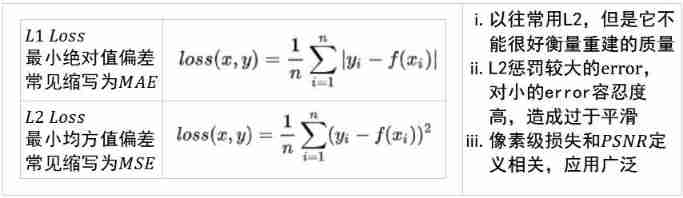
Content loss Content Loss
Measure the difference between the feature maps of different images after pre training the model , Calculate the perceptual similarity between images

among ,φ It's using Vgg、ResNet And other pre trained image classification Networks
Texture loss Texture Loss
Considering that the reconstructed image should have the same style as the target image ( Such as color 、 texture 、 Contrast ), The image texture is regarded as the correlation between different feature channels , The texture of the image is regarded as the correlation between different feature channels ( Use matrix point multiplication to express Correlation )

The final loss function requires the same correlation :

It requires some experience in parameter adjustment ,patch Too small will cause partial ghosting of texture , Too big to double the whole image
Against the loss Adversarial Loss
In generating a countermeasure network , The discriminator is used to judge the authenticity of the current input signal , The generator generates as much as possible “ really ” The signal of , To cheat the discriminator

Loss of cycle consistency Cycle Consistency Loss
Inspired by , take HR The image passes through another CNN Network reduced to I', Then measure the similarity with the small image to be processed

Total change loss Total Variation Loss
Used to suppress noise , Improve the spatial smoothness of the image
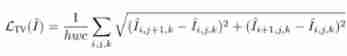
Loss based on a priori Prior-Based Loss
Super resolution focusing on face images , Introduce face comparison network FAN To constrain the consistency of faces detected from the original and generated images , Often with multiple Loss Use a combination of , It requires some experience in parameter adjustment
边栏推荐
- 关于 uintptr_t和intptr_t 类型
- How to use AHAS to ensure the stability of Web services?
- 技術實踐|線上故障分析及解决方法(上)
- The force deduction method summarizes the single elements in the 540 ordered array
- 【.NET+MQTT】. Net6 environment to achieve mqtt communication, as well as bilateral message subscription and publishing code demonstration of server and client
- 1-Redis架构设计到使用场景-四种部署运行模式(上)
- 技术实践|线上故障分析及解决方法(上)
- Meta metauniverse female safety problems occur frequently, how to solve the relevant problems in the metauniverse?
- 不得不会的Oracle数据库知识点(三)
- Network layer - routing
猜你喜欢
Who moved my code!

技術實踐|線上故障分析及解决方法(上)
MySQL deadly serial question 2 -- are you familiar with MySQL index?

1-redis architecture design to use scenarios - four deployment and operation modes (Part 1)
Characteristics of ginger

Conditional test, if, case conditional test statements of shell script

CLP information - how does the digital transformation of credit business change from star to finger?

51 MCU external interrupt
Technical practice online fault analysis and solutions (Part 1)
手机异步发送短信验证码解决方案-Celery+redis
随机推荐
[error record] configure NDK header file path in Visual Studio
Query efficiency increased by 10 times! Three optimization schemes to help you solve the deep paging problem of MySQL
Sequence list and linked list
Summary of common tools and technical points of PMP examination
How to set the response description information when the response parameter in swagger is Boolean or integer
Future源码一观-JUC系列
Flutter local database sqflite
Oracle database knowledge points (IV)
7.1 learning content
Pratique technique | analyse et solution des défaillances en ligne (Partie 1)
Huawei BFD and NQA
Release and visualization of related data
Summary of JWT related knowledge
Hash table, string hash (special KMP)
不得不会的Oracle数据库知识点(一)
Day05 table
2-redis architecture design to use scenarios - four deployment and operation modes (Part 2)
Function: store the strings entered in the main function in reverse order. For example, if you input the string "ABCDEFG", you should output "gfedcba".
[common error] custom IP instantiation error
长文综述:大脑中的熵、自由能、对称性和动力学