当前位置:网站首页>3D object detection dataset
3D object detection dataset
2022-08-02 05:23:00 【hello689】
目录
First to list a few introduce dataset papers and some convenient download data set community or site.
论文:
- Deep Learning based Monocular Depth Prediction: Datasets, Methods and Applications(This paper has a monocular depth estimation field commonly used data sets,Documentary orders,3DTarget detection data set is a lot of coincidence)
数据集网站:
- Public data sets to download | 格物钛,非结构化数据平台,This is the address,下载方便,Even you don't have to download directly preview data.
- Open Datasets - Scale,The site mainly provides data sets summary list.
Before on zhihu search to an article about data sets,太优秀了:Automated driving source data sets summary.Although there are many such data sets are introduced,But I still want to arrange、输出一下.After learning some knowledge,通过自己的理解,整理,再输出一遍,Help yourself remember a little.
image source: 文献 nuScenes: A multimodal dataset for autonomous driving
1. KITTI Dataset
数据集地址:The KITTI Dataset
论文地址:Vision meets robotics: The KITTI dataset
3D object detection benchmark 由:
- 7481张train image,
- 7518张test image,
- And the composition of the corresponding point cloud,
- 共包含80256The goal of mark.
- 9个类别
评价标准:使用PASCALStandard to evaluate3D目标检测性能.对于汽车,我们要求3DBounding box overlap70%,And for pedestrians and cyclists,我们要求3DBounding box overlap50%.在2019年10月8日,KittiWebsite to followMapillaryTeam in their paper Disentangling Monocular 3D Object Detection中提出的建议,使用40A recall of position insteadPascal VOCBenchmark proposed11A recall of position.The comparison results is fair.The specific method for evaluating the data,There are many online blog has introduced,我就不再赘述:KITTI 3D目标检测的评估指标_W1995S的博客-CSDN博客.Understand the two concepts in advance is needed here:
mAP(mean Average Precision,All the class label of the average precision rate)
PR曲线
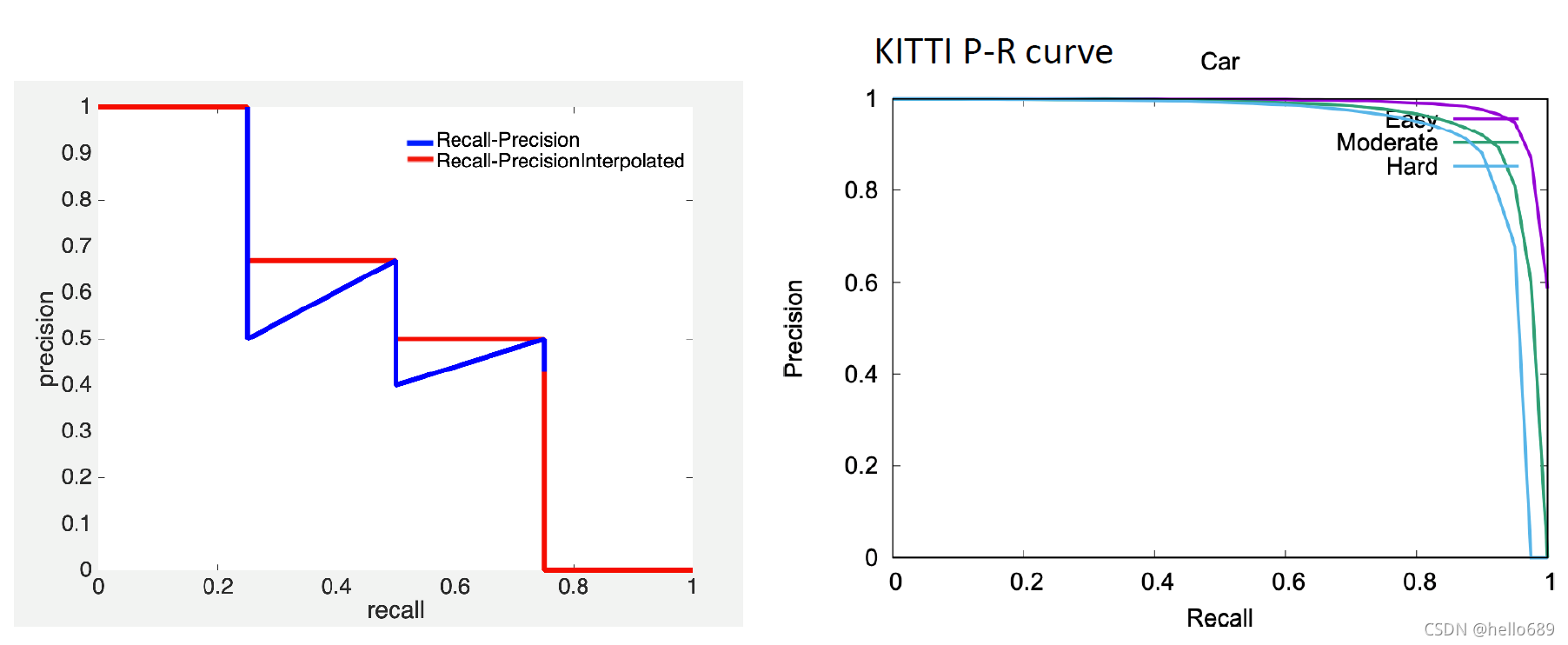
img source: The KITTI Vision Benchmark Suite (cvlibs.net)
Annotation data is introduced:
000000.txt:
Pedestrian 0.00 0 -0.20 712.40 143.00 810.73 307.92 1.89 0.48 1.20 1.84 1.47 8.41 0.01
- 1 类型: 包括Car、Van、Pedestrian、Cyclist、Truck、DontCare等
- 2 截断: 从0(未截断)到1(截断)浮点数,Truncation refers to the left image boundary object
- 3 遮挡 : 用整数 (0,1,2,3) To represent the state of several:
0 =完全可见, 1 = 部分遮挡
2 = A wide range of keep out, 3 = 未知 - 4 alpha: Observe the Angle of the object,范围[-pi , pi]
- 5-8 bbox: contains left, top, right, bottom pixel coordinates
- 9-11 Dimension shape dimension: 3D object dimensions: height, width, length (in meters)
- 12-14 位置: 在相机坐标系下3D object location x,y,z(in meters)
- 15 rotation_y: In the camera coordinate system about abouty-axis的旋转,范围[-pi, pi]
注:在这里,“DontCare”Label for objects not marked area,Because they are too far from the laser scanner.
000000.png
000001.txt:
Truck 0.00 0 -1.57 599.41 156.40 629.75 189.25 2.85 2.63 12.34 0.47 1.49 69.44 -1.56
Car 0.00 0 1.85 387.63 181.54 423.81 203.12 1.67 1.87 3.69 -16.53 2.39 58.49 1.57
Cyclist 0.00 3 -1.65 676.60 163.95 688.98 193.93 1.86 0.60 2.02 4.59 1.32 45.84 -1.55
DontCare -1 -1 -10 503.89 169.71 590.61 190.13 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 511.35 174.96 527.81 187.45 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 532.37 176.35 542.68 185.27 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 559.62 175.83 575.40 183.15 -1 -1 -1 -1000 -1000 -1000 -10
000001.png
Easy、Moderate、Hard标准定义如下:
Easy: Min. bounding box height: 40 Px, Max. occlusion level: Fully visible, Max. truncation: 15 %
Moderate: Min. bounding box height: 25 Px, Max. occlusion level: Partly occluded, Max. truncation: 30 %
Hard: Min. bounding box height: 25 Px, Max. occlusion level: Difficult to see, Max. truncation: 50 %
2. Waymo Open Dataset
数据集地址:https://waymo.com/open
论文地址:
- Scalability in Perception for Autonomous Driving: Waymo Open Dataset(2020)
- [Large Scale Interactive Motion Forecasting for Autonomous Driving :The WAYMO OPEN MOTION DATASET(2021)]([2104.10133] Large Scale Interactive Motion Forecasting for Autonomous Driving : The Waymo Open Motion Dataset (arxiv.org))
整个数据集包含1150个场景,Each time about20秒,且LiDAR和CameraIs a synchronous and calibration of. The image and laser radarbounding boxCarefully mark,And between each frame using a consistent identifier.
数据集介绍:
1150个场景,Each scenario length is about20秒
1000个训练集,150个测试集
1200万个LiDARComment box and1200M image comment box
Perception Dataset: 标签为Vehicles, Pedestrians, Cyclists, Signs 四类
Motion Dataset:标签为Vehicles, Pedestrians, Cyclists三类.
3. NuScenes DataSet
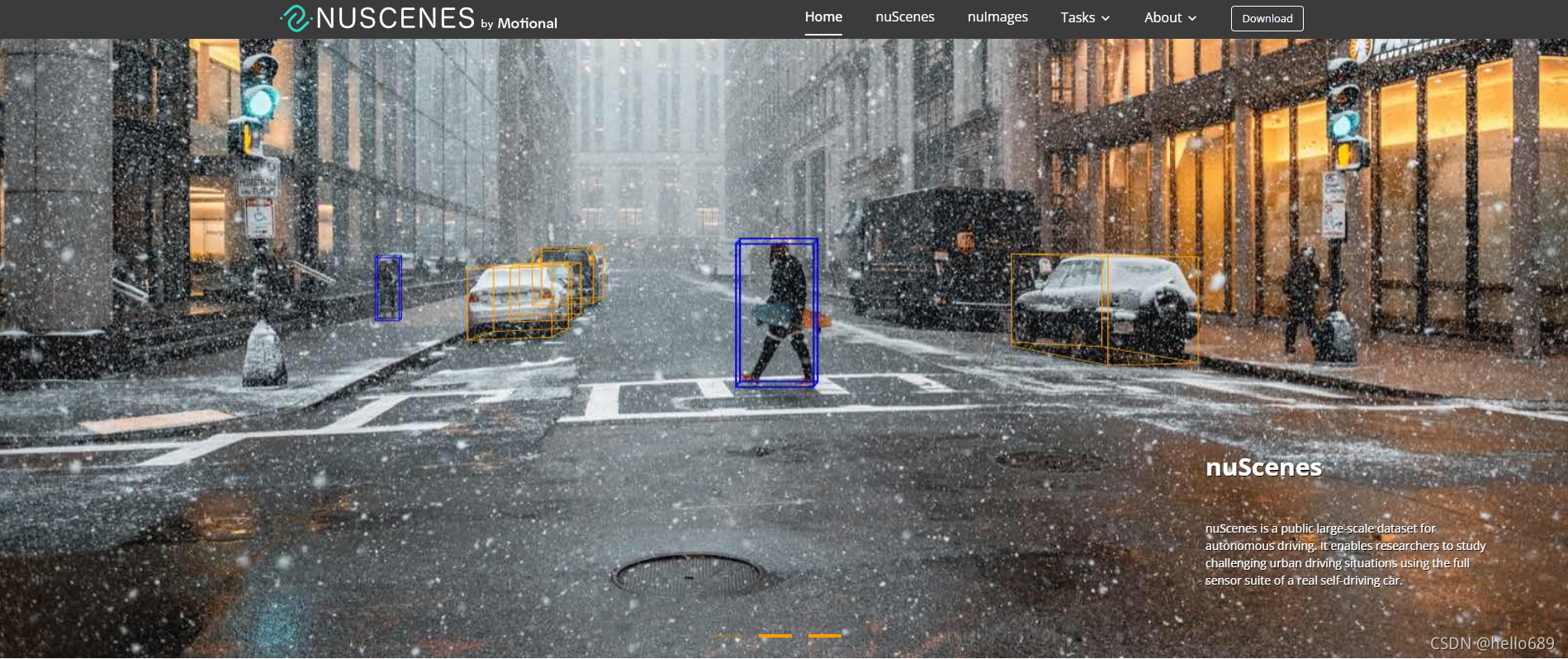
image source: https://www.nuscenes.org/
数据集地址:https://www.nuscenes.org/download
论文地址:nuScenes: A Multimodal Dataset for Autonomous Driving
Source of data sets a brief introduction to:
MotionalHyundai motor group andAptivA joint venture of unmanned company,Committed to self-driving car safety,Reliable, and can reach.It has a unique power,Allow us to fundamentally change people's way of life.MotionalMission is to create and develop can save life、Technology save time and money,The works to change the world.
nuScenes数据集是由MotionalTeam development for unmanned public large data sets.In order to support the public research in computer vision and automated driving,Motional公开了nuScenes的部分数据.
关于nuScenes:
- 1个LiDAR,5个RADAR,6个camera,IMU,GPS
- 1000 scenes of 20s each
- 1,400,000 camera images
- 390,000 lidar sweeps
- Two diverse cities: Boston and Singapore
- 1.4M 3D bounding boxes manually annotated for 23 object classes
- New: 1.1B lidar points manually annotated for 32 classes
- 300GB
其中激光雷达:32线、范围为80-100m


image source: https://gas.graviti.cn/dataset/motional/nuScenes
Compared with other data sets: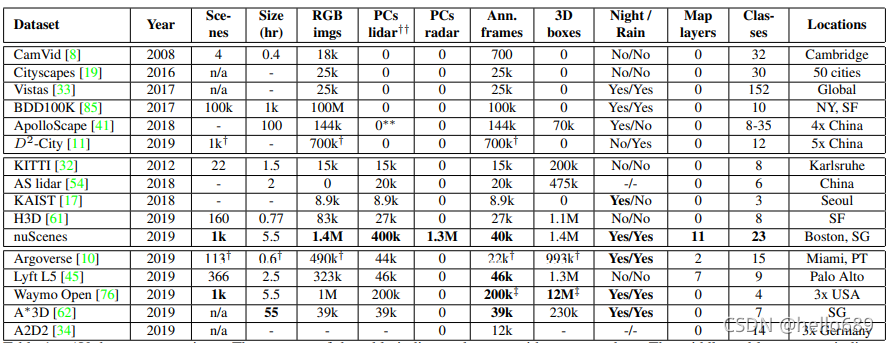
image source: 论文 nuScenes: A multimodal dataset for autonomous driving
4. Appllo Scape
数据集地址:Apollo Scape
论文地址:The ApolloScape Dataset 
image source: The ApolloScape Dataset for Autonomous Driving
ApolloScape由RGBVideo and the corresponding dense point cloud.包含140K张图片,And each image has the semantic information of pixel level.In the domestic data,So compared to some of the data set abroad,ApolloScapeThe data set contains traffic scene is very complicated,The first is the picture of one more,车多,Moving object more. 此外,This data set also includes lane based on color and style of different lane marker.
image source: The ApolloScape Dataset for Autonomous Driving
具体特点:
- 与kitti类似,也分为easy、moderate、hard三个子类.
- 标注信息包含28Class lane line
- 使用了2D/3DCombined with channel,是包含3DLabeling information of open data set
Compared with other data sets:
image source: The ApolloScape Dataset for Autonomous Driving
5. Lyft L5
数据集地址:
论文地址:
Data set is introduced address:
- Lyft 3D Object Detection for Autonomous Vehicles | Kaggle
- Devkit for the public 2019 Lyft Level 5 AV Dataset

数据介绍:
This data set is divided intoPrediction Dataset和PerceptionDataset.
- Prediction Dataset
The paper addresses of the data set:Self-driving Motion Prediction Dataset
超过1000Hours of autonomous movement data set.这是一个由20Self-driving car convoy of in 州Palo AltoA fixed route took on4Data collected in months.由17All of scene,Each scenario is long25秒, To capture the perception of the autopilot system output,Autopilot system coding traffic near、Bicycles and pedestrians precise location and move 作.除此之外,The data set contains a also contain15242A high-definition semantic markup elements and the area of hd An aerial view definition.总数据量有1000多个小时,接近90GB.
Data sets, there are three main parts:
- 17Thousands of scene,每25秒,Capture the self-driving cars and the movement of the traffic participants around it.
- A high-definition semantic map,Capture the rules of the road、Track geometry and other transportation elements.
- The region's high resolution aerial photographs,Can further help predict.
- Perception Dataset
- 1.3M 3D annotations
- 30K lidar point clouds
- 350+ scenes at 60-90 minutes long
This data set contains training set test set and validation set,大小为120GB左右.This url can be at the bottom of the manual withQWEASDOr up and down keys to watch point clouds and the correspondingRGB图像数据集.
image source: Perception - Level 5 (level-5.global)
6. Argoverse
7. H3D
8. Cityscapes
The city landscape data set(Cityscapes)Mainly focus on the city streets2D语义分割,包含30个类别,Fine label5000张图,Coarse mark20 000张图片.2020年10月上线了3D bounding box的标注,Mark points and the results are divided into8大类下的30类标签,Simplified version labels contain19类.
- 1024x2048RGB图像,采样频率17Hz,16位深HDR;At the same time also provide compression8位深LDR版本.
9. CADC
地址:https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2001.10117
The university of Toronto, Canada with unique advantage to provideSnow driving data set,Scenario highly targeted.
- With the data type of too little,只有3D bounding box
- Tag type is rough
- Acquisition route fixed,Scene is relatively drab
- The original data for500GB
10. Oxford RobotCar
All were very large data sets.Collect route isOxford中心,Because collected many times different weather and traffic condition data,The final dimension ridiculously large.但是,Data set provided only image、雷达、激光雷达和GPS/IMU的原始数据,And no additional annotations.
- 23+TB的原始数据
边栏推荐
猜你喜欢





随机推荐
企业级的dns服务器的搭建
Autowired注解与Resource注解的区别
this指向问题
Mysql数据库入门 (基础知识点 由来 各种指令 如何运用)
Gartner 权威预测未来4年网络安全的8大发展趋势
offset、client 和 scroll
未来智安入围《2022年中国数字安全百强报告》,威胁检测与响应领域唯一XDR厂商
v-bind动态绑定
The slave I/O thread stops because master and slave have equal MySQL server ids
ffmpeg视频播放、格式转化、缩放等命令
两端是圆角的进度条微信对接笔记
网络 7 层架构
七分钟深入理解——卷积神经网络(CNN)
CC1101魔幻的收发切换机制
ES6中变量的使用及结构赋值
Django、Rest framework访问数据库获取数据
计算属性的学习
Excel操作技巧大全
树莓派上QT连接海康相机
flask简单接口实现