当前位置:网站首页>C3d model pytorch source code sentence by sentence analysis (III)
C3d model pytorch source code sentence by sentence analysis (III)
2022-07-25 10:46:00 【zzh1370894823】
3.1 The source code parsing
train.py Explain
This code is C3D The training part of the model , It is divided into preparation before training , And training .
1. Preparation before training
1.1 Parameter settings
nEpochs = 101 # Number of epochs for training
resume_epoch = 0 # Default is 0, change if want to resume That is, change the parameters and start training again
useTest = True # See evolution of the test set when training
nTestInterval = 20 # Run on test set every nTestInterval epochs
snapshot = 25 # Store a model every snapshot epochs
lr = 1e-5 # Learning rate
save_dir_root = os.path.join(os.path.dirname(os.path.abspath(__file__))) # save_dir_root = '...\\C3D'
exp_name = os.path.dirname(os.path.abspath(__file__)).split('/')[-1] # exp_name = '...\\C3D'
This section is about the setting of some parameters
os.path.dirname(–file–) Get the path of the currently running script
1.2 Loading of models and datasets
model = C3D_model.C3D(num_classes=num_classes, pretrained=False)
train_params = [{
'params': C3D_model.get_1x_lr_params(model), 'lr': lr},
{
'params': C3D_model.get_10x_lr_params(model), 'lr': lr * 10}]
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(train_params, lr=lr, momentum=0.9, weight_decay=5e-4) # An optimization method , gradient descent
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10,
gamma=0.1)
# Load data set
train_dataloader = DataLoader(VideoDataset(dataset=dataset, split='train',clip_len=16), batch_size=2, shuffle=True, num_workers=0)
val_dataloader = DataLoader(VideoDataset(dataset=dataset, split='val', clip_len=16), batch_size=2, num_workers=0)
test_dataloader = DataLoader(VideoDataset(dataset=dataset, split='test', clip_len=16), batch_size=2, num_workers=0)
trainval_loaders = {
'train': train_dataloader, 'val': val_dataloader} # take train and val form dict
trainval_sizes = {
x: len(trainval_loaders[x].dataset) for x in ['train', 'val']}
test_size = len(test_dataloader.dataset)
train_params It's a two element list, Each element is two elements dict
scheduler Set up : Set the learning rate as per 10 individual epoch, The attenuation is 0.1 times
take train and val form dict, Easy to train
2. Training part
for epoch in range(resume_epoch, num_epochs):
for phase in ['train', 'val']:
start_time = timeit.default_timer()
# Clear losses and accuracy
running_loss = 0.0
running_corrects = 0.0
if phase == 'train':
scheduler.step() # Training set update learning rate
model.train()
else:
model.eval()
Every epoch It is divided into train and val Two parts
start_time Record run start time
scheduler.step() The training set needs to update the learning rate
Send input into the model
for inputs, labels in tqdm(trainval_loaders[phase]):
inputs = Variable(inputs, requires_grad=True).to(device)
labels = Variable(labels).to(device)
optimizer.zero_grad()
if phase == 'train':
outputs = model(inputs)
else:
with torch.no_grad():
outputs = model(inputs)
probs = nn.Softmax(dim=1)(outputs)
preds = torch.max(probs, 1)[1]
loss = criterion(outputs, labels.long()) # Calculate the loss function
if phase == 'train':
loss.backward()
optimizer.step() # Training set update parameters
running_loss += loss.item() * inputs.size(0) # Loss multiplication batchsize
running_corrects += torch.sum(preds == labels.data) # Predict the right number
# Calculate a epoch Loss and accuracy
epoch_loss = running_loss / trainval_sizes[phase]
epoch_acc = running_corrects.double() / trainval_sizes[phase]
tqdm It's a fast one , Extensible Python Progress bar , Can be in Python Add a progress prompt to the long loop .
with torch.no_grad(): Validation set disables gradient calculation , It will reduce the memory consumption required for calculation .
probs Of torch.size by (2, 101) , At this time take batchsize by 2, common 101 Action categories , Record the probability of each action classification .
preds = torch.max(probs, 1)[1] , Find out the maximum probability , Return its subscript , That is their prediction label
Such as :preds =tensor[4,32], That is, the prediction label is 4 and 32
Finally, calculate each epoch Loss and accuracy
write in tensorboard
if phase == 'train':
writer.add_scalar('data/train_loss_epoch', epoch_loss, epoch)
writer.add_scalar('data/train_acc_epoch', epoch_acc, epoch)
else:
writer.add_scalar('data/val_loss_epoch', epoch_loss, epoch)
writer.add_scalar('data/val_acc_epoch', epoch_acc, epoch)
print("[{}] Epoch: {}/{} Loss: {} Acc: {}".format(phase, epoch+1, nEpochs, epoch_loss, epoch_acc))
stop_time = timeit.default_timer() # Record the stop time
print("Execution time: " + str(stop_time - start_time) + "\n")
Save training parameters
if epoch % save_epoch == (save_epoch - 1):
torch.save({
'epoch': epoch + 1,
'state_dict': model.state_dict(),
'opt_dict': optimizer.state_dict(),
}, os.path.join(save_dir, 'models', saveName + '_epoch-' + str(epoch) + '.pth.tar'))
print("Save model at {}\n".format(os.path.join(save_dir, 'models', saveName + '_epoch-' + str(epoch) + '.pth.tar')))
Load test set
Methods are similar to validation sets , You don't have to calculate the gradient , Update parameters
if useTest and epoch % test_interval == (test_interval - 1):
model.eval()
start_time = timeit.default_timer()
running_loss = 0.0
running_corrects = 0.0
for inputs, labels in tqdm(test_dataloader):
inputs = inputs.to(device)
labels = labels.to(device)
with torch.no_grad():
outputs = model(inputs)
probs = nn.Softmax(dim=1)(outputs)
preds = torch.max(probs, 1)[1]
loss = criterion(outputs, labels.long())
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / test_size
epoch_acc = running_corrects.double() / test_size
writer.add_scalar('data/test_loss_epoch', epoch_loss, epoch)
writer.add_scalar('data/test_acc_epoch', epoch_acc, epoch)
print("[test] Epoch: {}/{} Loss: {} Acc: {}".format(epoch+1, nEpochs, epoch_loss, epoch_acc))
stop_time = timeit.default_timer()
print("Execution time: " + str(stop_time - start_time) + "\n")
Pure personal thinking summary , Mistakes are inevitable , Welcome to correct , Thank you for .
边栏推荐
- 2021 written examination summary of niuke.com 01
- Visual thematic map of American airport go style: ArcGIS Pro version
- Differences between redis and mongodb
- Druid 查询超时配置的探究 → DataSource 和 JdbcTemplate 的 queryTimeout 到底谁生效?
- 7.shell实用的小工具cut等
- I wrote code for openharmony, and the second phase of "code" pioneer officially opened!
- 微信小程序WxPrase中包含文件无法点击解决
- Reproduce asvspoof 2021 baseline rawnet2
- 7. Shell practical gadget cut, etc
- [strategic mode] like Zhugeliang's brocade bag
猜你喜欢
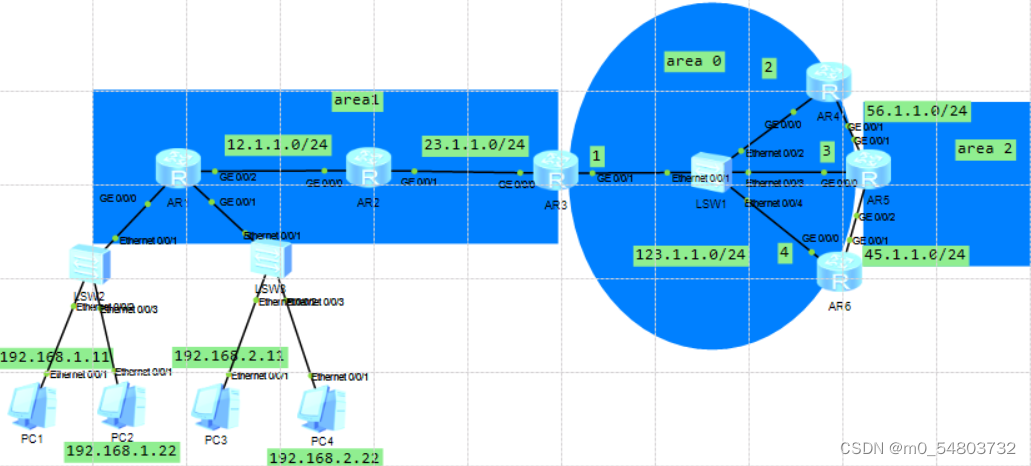
Configuration of OSPF protocol (take Huawei ENSP as an example)
UE4 quickly find the reason for packaging failure

3.跟你思想一样DNS域名解析服务!!!

Flask框架——Flask-WTF表单:文件上传、验证码

2021 CEC笔试总结

Introduction to onnx (open neural network exchange)

云原生IDE:iVX免费的首个通用无代码开发平台

Use three.js to realize the cool cyberpunk style 3D digital earth large screen

2021 jd.com written examination summary

CONDA configures the deep learning environment pytorch transformers
随机推荐
6. PXE combines kickstart principle and configuration to realize unattended automatic installation
js 集合
Storage, computing, distributed Virtualization (collection and sorting is suitable for Xiaobai)
HCIA实验(07)综合实验
9. Shell text processing three swordsmen awk
7.shell实用的小工具cut等
The idea has been perfectly verified again! The interest rate hike is approaching, and the trend is clear. Take advantage of this wave of market!
Use of mongodb
HCIP实验(03)
Configuration of OSPF protocol (take Huawei ENSP as an example)
Idea overall font size modification
C class library generation, use class library objects to data bind DataGridView
Wechat applet wxprase contains files that cannot be solved by clicking
2021 jd.com written examination summary
Flask框架——消息闪现
接口流量突增,如何做好性能调优?
【信息系统项目管理师】思维导图系列精华汇总
11.iptables 防火墙
UE4 quickly find the reason for packaging failure
Flask框架——Flask-WTF表单:文件上传、验证码