当前位置:网站首页>【AI4Code】《CoSQA: 20,000+ Web Queries for Code Search and Question Answering》 ACL 2021
【AI4Code】《CoSQA: 20,000+ Web Queries for Code Search and Question Answering》 ACL 2021
2022-07-25 12:40:00 【chad_ lee】
《CoSQA: 20,000+ Web Queries for Code Search and Question Answering》 ACL 2021
similar CLIP Made a NL-PL Of query-key Binary data sets , And then it's like CLIP The same two-mode alignment training , On this basis, comparative learning is added , Two kinds of data amplification methods are designed . Twin tower encoder All are CodeBERT.
CoSQA Data sets
What the article wants to achieve is that we can search for pictures on the Internet , Input according to the demand query, Return the code implementation that meets the requirements ( Now we usually return to the blog ). This article has made great efforts to construct such a data set , It looks something like this .
There are also a lot of data structure details , For example, partial satisfaction query The needs of , Completely satisfied query The needs of , Meet less than 50% The needs of , Only and query Relevant, etc .

Model

The input form of the model is a sequence :[CLS] xxxxxxxx [SEP]. Twin network for model ,query and code All with the same CodeBERT code . The output of the model is [CLS] The representation of .
q i = C o d e E R T ( q i ) , c i = C o d e B E R T ( c i ) \mathbf{q}_{i}=\mathbf{C o d e} \mathbf{E R T}\left(q_{i}\right), \quad \mathbf{c}_{i}=\mathbf{C o d e B} \mathbf{E R T}\left(c_{i}\right) qi=CodeERT(qi),ci=CodeBERT(ci)
The model is not simply used q and c The inner product of calculates the similarity , Instead, use another MLP Calculate the matching relationship between the two .MLP The output of is a vector , Not the similarity score
r ( i , i ) = tanh ( W 1 ⋅ [ q i , c i , q i − c i , q i ⨀ c i ] ) \mathbf{r}^{(i, i)}=\tanh \left(\mathbf{W}_{1} \cdot\left[\mathbf{q}_{i}, \mathbf{c}_{i}, \mathbf{q}_{i}-\mathbf{c}_{i}, \mathbf{q}_{i} \bigodot \mathbf{c}_{i}\right]\right) r(i,i)=tanh(W1⋅[qi,ci,qi−ci,qi⨀ci])
Another single layer NN Calculate the similarity between them :
s ( i , i ) = sigmoid ( W 2 ⋅ r ( i , i ) ) s^{(i, i)}=\operatorname{sigmoid}\left(\mathbf{W}_{2} \cdot \mathbf{r}^{(i, i)}\right) s(i,i)=sigmoid(W2⋅r(i,i))
And then use BCE loss Training :
L b = − [ y i ⋅ log s ( i , i ) + ( 1 − y i ) log ( 1 − s ( i , i ) ) ] \mathcal{L}_{b}=-\left[y_{i} \cdot \log s^{(i, i)}+\left(1-y_{i}\right) \log \left(1-s^{(i, i)}\right)\right] Lb=−[yi⋅logs(i,i)+(1−yi)log(1−s(i,i))]
Comparative learning
except BCE loss Outside ,In-Batch Augmentation (IBA) and Query-Rewritten Augmentation (QRA)
IBA Loss
For each of these query, At the same time, select the current batch Others in code As a negative sample , Equivalent to a query More than code Negative sample
L i b = − 1 n − 1 ∑ j = 1 j ≠ i n log ( 1 − s ( i , j ) ) \mathcal{L}_{i b}=-\frac{1}{n-1} \sum_{\substack{j=1 \\ j \neq i}}^{n} \log \left(1-s^{(i, j)}\right) Lib=−n−11j=1j=i∑nlog(1−s(i,j))
QRA Loss
because Web query Usually very short , And grammar is not guaranteed , So for a couple The label is 1 Of query-code pair, Yes query Do some rewriting and modification , Include : Randomly delete a word 、 Randomly switch the positions of two words 、 Copy a word randomly .
This is equivalent to a code More than Query Positive sample . stay QRA It will also be applied on the basis of IBA loss:
L q r = L b ′ + L i b ′ \mathcal{L}_{q r}=\mathcal{L}_{b}^{\prime}+\mathcal{L}_{i b}^{\prime} Lqr=Lb′+Lib′
experiment
In this paper, code contrastive learning method (CoCLR) Is a learning method , The experiment is done in pre training CodeBERT Continue training on the basis of .
Two task One is Code Question Answering Divide the test set directly from the training set , One is code search .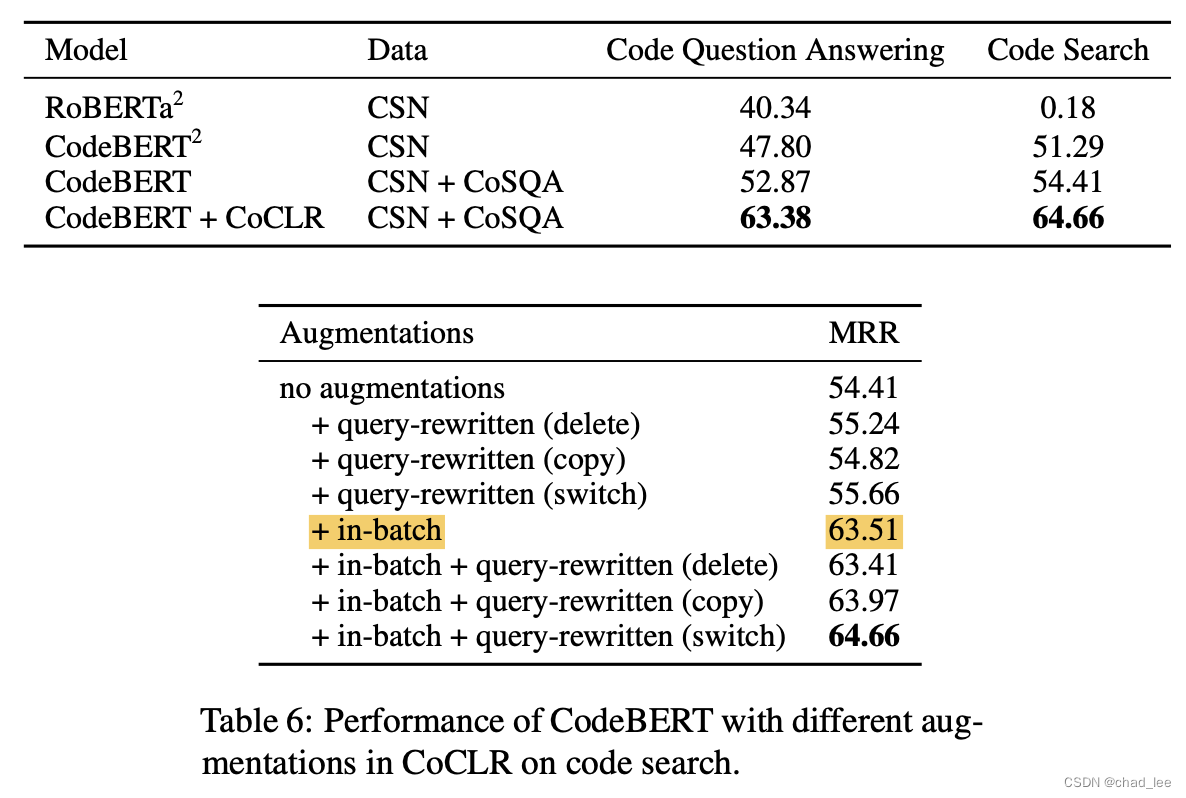
CodeBERT+CoSQA Is in the BERT Based on the explicit alignment of the two languages , There is a certain improvement , But the best effect is the data amplification of comparative learning . The most useful one is batch Inner negative sample .query In the enhancement, the order of exchanging words is greatly improved , It's also more intuitive , Because usually changing two words doesn't affect reading comprehension .
边栏推荐
- PyTorch主要模块
- Resttemplate and ribbon are easy to use
- Pytorch advanced training skills
- 2022.07.24(LC_6126_设计食物评分系统)
- 状态(State)模式
- 【3】 DEM mountain shadow effect
- 2022河南萌新联赛第(三)场:河南大学 I - 旅行
- [ROS advanced chapter] Lecture 9 programming optimization of URDF and use of xacro
- 【10】 Scale bar addition and adjustment
- shell基础知识(退出控制、输入输出等)
猜你喜欢


![[rust] reference and borrowing, string slice type (& STR) - rust language foundation 12](/img/48/7a1777b735312f29d3a4016a14598c.png)







随机推荐
如何从远程访问 DMS数据库?IP地址是啥?用户名是啥?
我想问DMS有没有定时备份某一个数据库的功能?
想要做好软件测试,可以先了解AST、SCA和渗透测试
3.2.1 what is machine learning?
Ansible
Azure Devops(十四) 使用Azure的私有Nuget仓库
Interviewer: "classmate, have you ever done a real landing project?"
Intval MD5 bypass [wustctf2020] plain
【5】 Page and print settings
公安部:国际社会普遍认为中国是世界上最安全的国家之一
【10】 Scale bar addition and adjustment
Ecological profile of pytorch
LeetCode 1184. 公交站间的距离
R language uses LM function to build multiple linear regression model, step function to build forward stepwise regression model to screen the best subset of prediction variables, and scope parameter t
软件测试流程包括哪些内容?测试方法有哪些?
Visualize the training process using tensorboard
shell基础知识(退出控制、输入输出等)
LeetCode 0133. 克隆图
Spirng @Conditional 条件注解的使用
If you want to do a good job in software testing, you can first understand ast, SCA and penetration testing