当前位置:网站首页>文本预处理库spaCy的基本使用(快速入门)
文本预处理库spaCy的基本使用(快速入门)
2022-06-29 14:33:00 【iioSnail】
spaCy 简介
spaCy(官方网站,github链接)是一个NLP领域的文本预处理Python库,包括分词(Tokenization)、词性标注(Part-of-speech Tagging, POS Tagging)、依存分析(Dependency Parsing)、词形还原(Lemmatization)、句子边界检测(Sentence Boundary Detection,SBD)、命名实体识别(Named Entity Recognition, NER)等功能。具体支持功能参考链接。
spaCy的特点:
spaCy 安装
pip install spacy -i https://pypi.tuna.tsinghua.edu.cn/simple
若想安装GPU版,可参考官方文档
spaCy的基本使用
spacy对所有的任务基本都是4步走:
- 下载模型
- 加载模型
- 对句子进行处理
- 获取结果
举例,使用spacy进行英文分词:
1.首先通过命令下载模型:
python -m spacy download en_core_web_sm
en_core_web_sm 是模型的名称,可以到该链接搜索模型。
由于在国内,可能会有下载慢的问题,可以到github搜索模型,然后使用
pip install some_model.whl手动安装
2.加载、使用模型和获取结果
import spacy # 导包
# 加载模型
nlp = spacy.load("en_core_web_sm")
# 使用模型,传入句子即可
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
# 获取分词结果
print([token.text for token in doc])
最终输出为:
['Apple', 'is', 'looking', 'at', 'buying', 'U.K.', 'startup', 'for', '$', '1', 'billion']
spaCy中的几个重要类
在上一节中,有几个关键对象
nlp:该对象为spacy.Language类(官方文档链接)。spacy.load方法会返回该类对象。nlp("...")本质就是调了Language.__call__方法doc: 该对象为spacy.tokens.Doc(官方文档链接),里面包含分词、词性标注、词形还原等结果(具体可参考链接)。doc是一个可迭代对象。token: 该对象为spacy.tokens.token.Token(官方文档链接),可以通过该对象获取每个词的具体属性(单词、词性等),具体可参考链接。
spaCy的处理过程(Processing Pipeline)

调用nlp(...)时会按照上图的顺序执行(先分词,然后进行词性标注等等)。对于不需要的组件,可以选择在加载模型时排除掉:
nlp = spacy.load("en_core_web_sm", exclude=["ner"])
或者禁用掉:
nlp = spacy.load("en_core_web_sm", disable=["tagger", "parser"])
对于禁用,可以在后续想要使用的时候解除禁用:
nlp.enable_pipe("tagger")
所有内置的组件可参考链接
实战:对中文进行分词和Word Embedding
1.首先到官方文档的中文模块下找到合适的模型。这里就选择最小的那个吧。
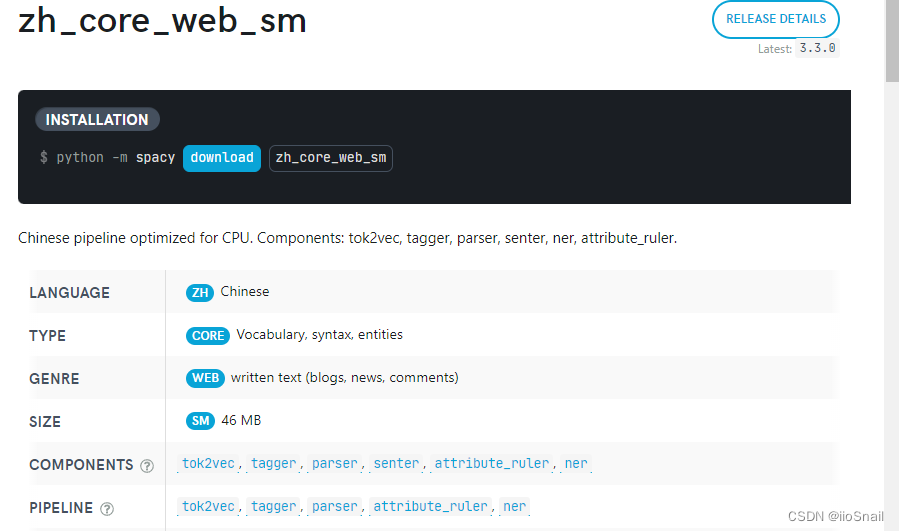
2.下载模型
python -m spacy download zh_core_web_sm
3.写代码
import spacy # 导包
# 加载模型,并排除掉不需要的components
nlp = spacy.load("zh_core_web_sm", exclude=("tagger", "parser", "senter", "attribute_ruler", "ner"))
# 对句子进行处理
doc = nlp("自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。")
# for循环获取每一个token与它对应的向量
for token in doc:
# 这里为了方便展示,只截取5位,但实际该模型将中文词编码成了96维的向量
print(token.text, token.tensor[:5])
在官方提供的模型中,具有tok2vec这个组件,说明该模型可以对词进行embedding,很方便。最终的输出为:
自然 [-0.16925007 -0.8783153 -1.4360809 0.14205566 -0.76843846]
语言 [ 0.4438781 -0.82981354 -0.8556605 -0.84820974 -1.0326502 ]
处理 [-0.16880168 -0.24469137 0.05714838 -0.8260342 -0.50666815]
是 [ 0.07762825 0.8785285 2.1840482 1.688557 -0.68410844]
... // 略
和 [ 0.6057179 1.4358768 2.142096 -2.1428592 -1.5056412]
方法 [ 0.5175674 -0.57559186 -0.13569726 -0.5193214 2.6756258 ]
。 [-0.40098143 -0.11951387 -0.12609476 -1.9219975 0.7838618 ]
边栏推荐
- Methods of accessing external services in istio grid
- Redis' data expiration clearing strategy and memory obsolescence strategy
- Chapter 6 picture operation of canvas
- Research Report on research and development prospect of China's urea dioxide industry (2022 Edition)
- Kubernetes Pod 排错指南
- word如何自动生成目录
- 论文学习——考虑场次降雨年际变化特征的年径流总量控制率准确核算
- 网易严选离线数仓质量建设实践
- 揭秘!付费会员制下的那些小心机!
- Thanos store component
猜你喜欢









随机推荐
idea输出台输出中文乱码问题
【Try to Hack】vulnhub DC2
Swagger2的配置教程
Alibaba cloud experience Award: use polardb-x and Flink to build a large real-time data screen
Redis' cache avalanche, cache breakdown, cache penetration, cache preheating, and cache degradation
Differences between @resource and @autowired annotations automatically injected:
Heavyweight! The latest SCI impact factors were released in 2022, and the ranking of the three famous journals NCS and the top10 of domestic journals has changed (the latest impact factors in 2022 are
EMC-浪涌防护及退耦设计
传输层 选择性确认 SACK
华曙高科冲刺科创板:拟募资6.6亿 实控人许小曙父子均为美国籍
阿里云体验有奖:使用PolarDB-X与Flink搭建实时数据大屏
《canvas》之第10章 canvas路径
Weigao blood purification sprint to Hong Kong: annual revenue of RMB 2.9 billion, net profit decreased by 12.7%
. Net program configuration file operation (INI, CFG, config)
Interview shock 61: tell me about MySQL transaction isolation level?
Thanos store component
How bad can a programmer be?
高并发软件(网站,服务器端接口)的评价指标
[shell] Jenkins shell realizes automatic deployment
精品商城拼团秒杀优惠折扣全功能完美双端自适应对接个人免签网站源码