当前位置:网站首页>MWEC:一种基于多语义词向量的中文新词发现方法
MWEC:一种基于多语义词向量的中文新词发现方法
2022-07-26 00:12:00 【米朵儿技术屋】
摘要
【目的】 提出一种基于多语义词向量的中文新词发现方法(MWEC),解决多领域社交媒体文本的分词不准确问题。【方法】 利用社交媒体文本,结合中文知网和汉字笔画数据库训练多语义词向量,以解决语义混淆问题。使用N-gram频繁字符串挖掘方法识别相关度高的子词集合,以此获取新词候选集。利用多语义词向量的语义相似度评估候选词进而获得新词。【结果】 在金融、体育、旅游和音乐4个领域数据集上进行实验,结果表明本文方法的F1指标较对比方法分别提升了2.0(金融)、3.0(体育)、2.6(旅游)、11.3(音乐)个百分点。【局限】 候选词生成策略着重关注子词的热度,低频词很难被识别出来。【结论】 通过增强词向量的语义理解能力,利用多语义词向量对新词候选词进行剪枝,能有效提升针对中文社交媒体文本的新词发现能力。
关键词: 向量; 新词; 分词; N-gram; 多语义词向量; 语义相似度
1 引言
随着以新浪、搜狐、马蜂窝、网易云为代表的垂直领域互联网社交应用的发展和普及,社会媒体已经逐渐发展为信息传递的重要载体,融入到人们的日常生活中[1]。社交媒体文本具有分布领域广、口语化程度高等特点,分词标准一直以来都无法被统一[2]。新词发现是分词任务关注的重要问题之一,社交媒体日常产生的文本往往伴随着大量新词的出现,分词工具不能有效地识别这些新词语,会直接影响以分词为基础的上层任务(如信息抽取、情感计算、依存句法分析等)的分析效果。社交媒体文本语料中没有成熟的训练语料,无法通过有监督的方法训练得到可靠的新词识别模型,因而无监督的新词发现方法受到人们的重视。目前,国内外已有一些关于无监督方法的新词发现研究。最早的主流研究是基于统计规则的新词发现,其最大的弱点是具有领域局限性,由领域专家制定与领域文本相匹配的规则模板,然后利用规则模板针对大规模社交文本语料进行新词发现,该类方法准确率普遍偏低;随着词向量技术的普及与发展,词向量开始应用于新词发现任务中,基于词向量剪枝的新词发现方法先利用共现频率、信息熵等手段获取新词候选词集,然后利用训练好的词向量对候选词进行剪枝来获得新词,该方法领域通用性有所提升,但准确率仍然偏低。针对基于词向量剪枝的新词发现方法准确率低的问题,本文提出一种基于多语义词向量的中文新词发现方法,通过在金融、体育、旅游和音乐4个不同领域数据集上进行算法实验,证明了在新词发现时利用多语义词向量进行剪枝可以有效识别中文社交媒体文本中存在的未被分词工具发现的新词。
本文的主要贡献包括以下三个方面:
(1)提出一种基于多语义词向量表示的中文新词发现方法(MWEC),通过利用多语义词向量对N-gram新词候选集进行剪枝,实现新词发现;
(2)设计热度规则和合成性规则挖掘多领域文本中的N-gram新词候选词集;
(3)引入外部知识库训练多语义词向量,多语义词向量表示方法被应用到候选词集剪枝中,解决了中文一词多义的问题,同时保留子词间的语义关系,提升新词发现能力。
2 相关工作
新词发现主要有基于规则的新词发现方法和基于统计的新词发现方法。有监督的新词发现和无监督的新词发现在不同的背景下也都有着重要的研究意义。
基于规则的新词发现方法是通过匹配规则模板来发现新词的传统方法[3],优点是在特定领域的文本内准确度高。Zheng等提出基于领域专家的用户字典进行新词发现[4]。Chen等利用单音节词的语义和语法实现新词发现[5]。基于统计的方法主要利用文本本身信息进行新词发现,准确率普遍偏低[3]。许多研究表明,基于统计的方法又可以分为监督学习的方法和无监督学习的方法[6]。基于监督学习方法的新词发现需要消耗大量的精力进行标注[7],基于无监督学习方法的新词发现通常很难区分新词、命名实体等[8]。张华平等提出通过在分词前利用CRF对字进行标注来提升新词候选词质量[9]。
近年来,中文新词发现研究大都针对领域文本,目前在古汉语[10]、旅游[11]、专利[12]、食品安全[13]、金融[14]、新闻[15]、消费品[16]等领域都有相关研究。刘昱彤等设计并行化算法获取新词候选词,利用SVM、RNN网络等结合关联规则过滤候选词获得古汉语领域新词[10]。Li等提出的DWWP模型考虑旅游领域新词和情感词的关系,利用人工标注的情感知识提高模型识别能力[11]。陈梅婕等关注专利领域的长词,利用统计学方法获得中心词两端的统计特征,以更好地获取新词边界[12]。李少峰依托国家食品安全监管中心的食品安全数据,统计食品安全数据的特征,设计新词模板,挖掘食品安全领域新词[13]。张长在统计金融文本特征信息后,提取词语信息熵和作为独立词的概率,利用CNN网络提取金融领域中文新词[14]。王馨等设计关联算法挖掘新闻标题特征,结合新闻语料中的互信息,挖掘网络热点关键词[15]。彭郴等利用TF-IDF算法获取热词短语,人工删选领域相关词后,利用卷积神经网络对提取的消费品领域新词进行分类删选[16]。
Qian等提出WEBM方法[17],其核心思想是利用包含词语信息的Word2Vec词向量[18]对N-gram频繁字符串候选词组进行剪枝,从而在不需要标注的情况下获得新词,但是此方法没有考虑中文词语的一词多义现象,召回率很低。本文针对WEBM方法存在的中文词语的一词多义问题提出了一种无监督的中文社交媒体文本的新词发现方法MWEC,在训练Word2vec词向量时引入汉字笔画知识和知网(HowNet)[19]中的义原知识,从而获得多语义词向量,利用多语义词向量对N-gram频繁字符串候选词组进行剪枝得到新词。
3 基于多语义词向量的新词发现方法
新词识别流程如图1所示,对爬取的网络社交文本进行去重、分句等预处理获得领域语料库,然后分别采用词向量技术和候选词规则获得多语义词向量和N-gram候选词集。在训练多语义词向量时,先将语料库中的数据进行分词,考虑到中文词语的一词多义问题,提出Word2Vec结合知网和笔画外部数据库训练多语义词向量的方法,以增强词向量的语义表示能力,提高词向量的质量;在获取N-gram候选词集时,先将语料库中的数据处理为单序列分词文本,考虑到构成N-gram词串的子词共现频率和位置序列对候选词的影响,采用符合中文社交媒体文本热度规则和合成性规则获取N-gram候选词集。最后利用多语义词向量对N-gram候选词集进行剪枝获得新词,当N-gram候选词的子词相关性满足阈值时,候选词入选新词集。
图1

图1 新词发现流程
Fig.1 New Word Discovery Flow Chart
3.1 N-gram频繁字符串
新词发现的核心目的是研究词语语义,从而提高自然语言理解的能力[20]。在处理社交媒体文本获得新词时,通常共现频率较高的子词更有可能组成N-gram新词。N-gram新词具有热度规则和合成性规则。在详细描述新词发现实验之前,本文给出如下定义。
定义1 热度规则。如果一个新单词在语料库中频繁出现,那么这个单词可能会同时出现在一个新的单词中。本文使用一个出现频率的阈值过滤低频候选词,发现那些具有一定热度的新词候选词。
定义2 合成性规则。新词通常由2个或以上的被分词软件错误分割成的子词组合而成,它们具有一定的语义关系。但候选词由4个或以上子词组成时,子词之间的聚合度很低,语义联系不大,则它可能是命名实体而非新词,故新词大都由2~3个子词组成。
3.2 多语义词向量
知网(HowNet)[19]是以揭示概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。知网的结构中最重要的两个概念是“义项”和“义原”。研究表明引入知网义原对提升词向量质量有重要作用[21,22]。汉字笔画提供了一些关于每个汉字笔画的自然顺序的指导原则,笔画层次信息对于提高汉语单词嵌入的学习是至关重要的,通过挖掘中文字符的笔画特征信息,并以此构建词向量,能够获得中文字符内部的语义信息[23]。
相比于神经网络语言模型(Neural Network Language Model,NNLM)[24]及Log_Linear模型[25],Word2Vec可以更快速地训练词向量。利用Word2Vec训练的词向量,只能提供词语之间的相关性,语义相似度计算的准确度不高,针对这一问题,通常采用《同义词词林》提高词语语义相似度计算的准确性[26],但此方法并不适用于新词识别中的候选词剪枝。为获得语义清晰、表达明确、剪枝效果好的词向量,针对领域文本中新词识别不准确的问题,MWEC在Word2Vec模型的基础上,利用知网和汉字笔画作为外部知识库构建了多语义词向量进行新词候选词的剪枝。MWEC方法一方面通过SAT模型[27]利用注意力机制在考虑上下文信息的同时考虑词语的义原信息,得到能够准确表示义原信息的词向量;另一方面,由于知网中的义原信息没有覆盖所有构成新词的子词,通过cw2vec模型利用词语的N-gram笔画特征信息代替词语训练词向量对子词向量进行补充,结合Word2Vec最终得到包含文本语义信息的词向量 W1、W1、包含词语义原信息的词向量 W2W2以及包含汉字笔画信息的词向量 W3W3,共同构成向量 W=W={ W1W1, W2W2, W3W3},向量 WW同时包含上下文语义信息、义原信息和笔画信息,因此被称为多语义词向量。
3.3 候选词剪枝
分词软件在对句子进行分词操作时,可能会将出现的新词不恰当地分割成若干个子词。这些子词单独看包含一部分含义,但当几个相邻子词组合在一起时可能是某个领域出现的新词。这些新词可能是新的现象也可能是新的理论,新词由子词的语境、位置、语法功能共同组合形成,而词向量恰好包含子词的这些特性。如果新词的子词被分词软件错误分割,通过子词的词向量相似性可以在一定程度上重新检测出被错误分割的新词。例如,在本文实验中,N-gram候选词“新冠肺炎疫情”被分词软件分成“新冠”、“肺炎”和“疫情”三个子词,经过观察发现,“新冠”、“肺炎”和“疫情”的词向量余弦相似度很高,故依据N-gram候选词子词词向量剪枝策略可以有效检测出被分词软件不恰当分割的新词。
具体地,对组合成新词候选词的相邻子词相似度进行两两比较,如果存在某两个相邻子词相似度低的情况,就将该词从新词候选词集中移除。剪枝时首先确定相邻子词是否在多语义词向量的集合里,若相邻子词全部在多语义词向量集合里则用多语义词向量进行剪枝,否则用Word2Vec词向量代替多语义词向量进行剪枝。
4 实验与结果分析
4.1 数据采集及预处理
为从大量的领域文本中检测出新词,本文分别从新浪财经、搜狐体育、马蜂窝旅游和网易云音乐4个网站提取金融、体育、旅游和音乐语料构成4个领域的语料库。将收集到的篇章语料在句子层次进行分句,然后利用Jieba分词工具 (https://github.com/fxsjy/jieba.)对分句进行分词,数据集经过处理后的信息如表1所示。本实验采用“专家注释”的策略来评估实验效果,因此,在4个语料库上分别选取2 000个文本进行人工标注,专家依据特定领域的词语使用习惯对随机选取的8 000个文本进行新词标注,标注实例如表2所示。
表1 数据集信息统计
Table 1 The Data Set Information Statistics
数据集 | 领域 | URL | 大小(MB) | 句子数量 | 子词数量 |
DF | 金融 | http://finance.sina.com.cn/chanjing/ | 20.1 | 155 168 | 3 475 459 |
DS | 体育 | http://sports.sohu.com/guojizuqiu_a.shtml | 4.0 | 34 300 | 724 525 |
DT | 旅游 | http://www.mafengwo.cn | 62.8 | 553 958 | 11 285 076 |
DM | 音乐 | http://music.163.com/ | 35.0 | 662 640 | 6 818 760 |
表2 数据标注实例
Table 2 The Examples of Data Annotation
金融领域文本 | 分句 | 分词 | 标注 |
奢侈品消费,将决战于“90后”一代。不可否认,目前中国消费者的奢侈品购买力,虽然仍集中于千万以上资产的人群,但奢侈品消费的“后劲”,则看千禧一代。 | 奢侈品消费,将决战于“90后”一代。 | 奢侈品消费将决战于 90 后一代 | 奢侈品消费 |
不可否认,目前中国消费者的奢侈品购买力,虽然仍集中于千万以上资产的人群,但奢侈品消费的“后劲”,则看千禧一代。 | 不可否认目前中国消费者的奢侈品购买力虽然仍集中于千万以上资产的人群但奢侈品消费的后劲则看千禧一代 | 中国消费者奢侈品消费千禧一代 |
4.2 评测指标
使用精确率(Precision)、召回率(Recall)和F1值(F-measure)三个指标来评估新词发现方法的效果,各指标的计算方法如公式(1)-公式(3)所示。
Precision=#newwordscorrectlyidentified#recognizedwordsPrecision=#newwordscorrectlyidentified#recognizedwords
(1)
Recall=#newwordscorrectlyidentified#newwordsintheannotationcorpusRecall=#newwordscorrectlyidentified#newwordsintheannotationcorpus
(2)
F−measure=2×Precision×RecallPrecision+RecallF-measure=2×Precision×RecallPrecision+Recall
(3)
精确率是由正确识别的新词数除以识别出来的词数得到;召回率是由正确识别的新词数除以人工标注新词总数得到。
4.3 特征的选取与表示
基于合成性规则,从随机选取的文本中挖掘出由2~3个字词组成的N-gram候选词组,然后依据热度规则,分别对4个数据集的文本进行分析,统计结果如图2所示。
图2
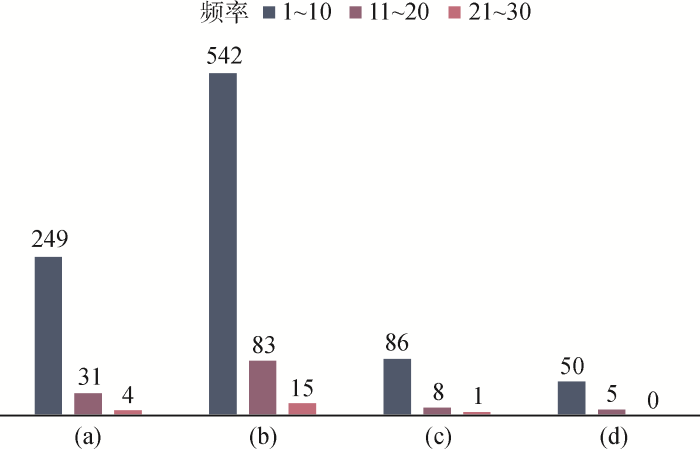
图2 N-gram字符串的频率分布
Fig.2 Frequency Distribution of N-gram String
其中,图2(a)-图2(d)分别代表财经新闻、体育新闻、旅游评论、音乐评论。可以看出,选择合适的热度规则对于候选词的生成具有显著影响,随着热度频率的增加,候选词的数量呈阶梯式下降。这个现象与数据的来源有关,金融新闻和体育新闻经过编辑校对,从专业角度出发对事件进行阐述,写作过程中有固定的话术表达;而旅游评论和音乐评论由用户个人发表,从个人角度表达对旅游景点或者音乐的直观感受,没有固定的话术。
4.4 相似度选择实验
在数据挖掘的文献中,最常用的向量比较的相似度度量方法是余弦相似度(Cosine)、欧氏距离(Euclidean)和曼哈顿距离(Manhattan)[28]。为此,在实验前进行了相似度选择实验,利用词向量对N-gram候选词集进行剪枝时,引入余弦相似度、欧氏距离和曼哈顿距离三种词向量相似性度量方法对候选词进行剪枝,并用F1值、精确率和召回率对不同词向量相似性度量方法的剪枝效果进行评价。
金融、体育、旅游、音乐4个领域数据库分别用余弦相似度、欧氏距离和曼哈顿距离三种词向量相似度度量方法进行剪枝的F1指标评价结果如表3所示。从F1指标来看,用余弦相似度进行剪枝在4个数据集上均能取得最好的结果。
表3 剪枝实验F1指标
Table 3 The F1 Index of Pruning Experiment
领域 | 余弦相似度 | 欧氏距离 | 曼哈顿距离 |
金融 | 0.702 | 0.659 | 0.670 |
体育 | 0.692 | 0.603 | 0.628 |
旅游 | 0.480 | 0.473 | 0.473 |
音乐 | 0.531 | 0.441 | 0.476 |
为进一步区别余弦相似度、欧氏距离和曼哈顿距离三种相似度度量方法的应用场景,将三种方法在4个领域数据库的精确率和召回率结果可视化如图3所示,其中图3(a)-图3(d)分别表示金融、体育、旅游、音乐。分析发现,利用新词候选词子词的词向量进行剪枝操作时,余弦相似度比欧氏距离或者曼哈顿距离在4个领域数据库均有更好的性能。基于此,接下来的新词发现实验采用余弦相似度进行剪枝操作。
图3
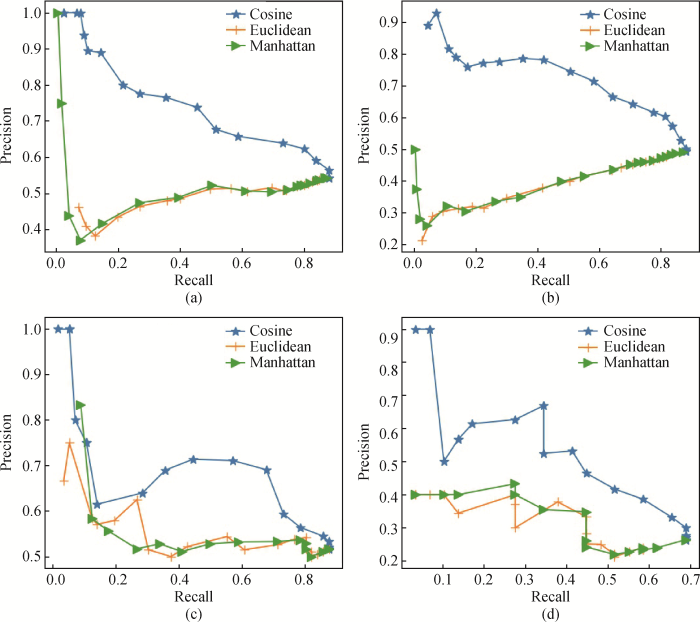
图3 不同相似性度量方法在剪枝中的性能比较
Fig.3 Comparing the Performance of Different Similarity Metrics in Candidate Pruning
4.5 结果分析
本文的候选词策略、MWEC方法、人工标注方法在4个2 000条领域数据集上的实验结果如表4所示。在金融、体育、旅游和音乐测试语料库中,分别挖掘出280、652、95和55个候选N-gram词串,通过MWEC方法分别识别出197、502、73和30个新词,而专家标注的新词分别为173、364、112和29个。MWEC方法和人工标注的方法在新词数量上呈现出正相关的趋势,音乐领域的新词最少,体育领域新词最多。通过分析数据发现,音乐评论短且评论中与演唱者、歌词相关的词以及情绪词较多,因此新词较少;体育新闻中有专业性较强的词汇,如“主场对战”、“左侧传中”等,因此新词较多。
表4 新词发现结果
Table 4 The Results on New Word Discovery
领域 | 数据集大小 | 候选集 | MWEC | 新词标注 |
金融 | 2 000 | 280 | 197 | 173 |
体育 | 2 000 | 652 | 502 | 364 |
旅游 | 2 000 | 95 | 73 | 112 |
音乐 | 2 000 | 55 | 30 | 29 |
一些领域专属的新词如表5所示,这些词被软件错误分割,利用MWEC方法可以有效识别并重新组合为新词。例如,“老舍纪念馆”(名词)被不适当地分词为“老舍”(名词)和“纪念馆”(名词)两个子词;“无目的地航班”(名词)被不适当地分为“无目的地”(形容词)和“航班”(名词)两个子词。
表5 新词发现实例
Table 5 Examples of New Word Discovery
金融 | 体育 | 旅游 | 音乐 |
名贵/特产 | 比赛/结束 | 东/夹道 | 植物/大战/僵尸 |
八渡/水文站 | 联赛杯/八强 | 史家/胡同 | 道德/绑架 |
无目的地/航班 | AC/米兰 | 爬/长城 | 网易/云/音乐 |
房地产/调控 | 主场/对阵 | 百花/草甸 | 网易/云 |
新冠/肺炎/疫情 | 血洗/林肯城 | 百花山/主峰 | 黑人/抬棺 |
北京/车展 | 海鸥/军团 | 老舍/纪念馆 | 中文/歌 |
生态/环保 | 英超/联赛 | 园博/园 | 火影/迷 |
合同/签署 | 佩里/西奇 | 深度/游 | 戳/爷 |
光线/传媒 | 鲁本/迪亚斯 | 鼓楼/东大街 | 螺旋/丸 |
为验证本文方法在检测发现方面的能力,在标注集上进行消融实验,使用如下4个方法在金融、体育、旅游和音乐测试语料库中进行实验。
(1) WEBM方法
WEBM方法是一种基于词向量剪枝的领域文本中文新词检测方法,其中词向量使用Word2Vec,采用余弦相似度进行候选词剪枝。
(2) WEBM+sense方法
WEBM+sense方法是在WEBM方法的基础上,引入知网外部知识库中的义原知识增强词向量的语义表示能力。
(3) WEBM+stroke方法
WEBM+stroke方法是在WEBM方法的基础上,引入汉字笔画外部知识库中的汉字笔画知识增强词向量的语义表示能力。
(4) MWEC方法
MWEC方法是在WEBM方法的基础上,针对Word2Vec在训练词向量时存在的一词多义问题,引入知网外部知识库中的义原知识和汉字笔画外部知识库中的汉字笔画知识增强词向量的语义表示能力。
MWEC方法在4个领域数据集上的精确率、召回率和F1值三个评价指标均有提升,如表6所示。通过消融实验的结果可以发现,引入知网或者笔画外部知识库对于召回率都有较大的提升。进一步分析可以发现,本文提出的无监督新词发现方法,对新闻类文本(如新浪财经、搜狐体育)比评论类文本(如马蜂窝旅游、网易云音乐评论)有更好的识别效果,其原因可能是新闻类文本有固定的话术,文本编辑者的自我表达相对较少,在写作过程中更趋于理性地讲述事件本身,具有一定的专业性。
表6 消融实验
Table 6 Ablation Experiment
数据集 | 方法 | 精确率 | 召回率 | F1值 |
DF | WEBM | 0.643 | 0.734 | 0.689 |
+sense | 0.596 | 0.796 | 0.682 | |
+stroke | 0.606 | 0.856 | 0.710 | |
MWEC | 0.655 | 0.773 | 0.709 | |
DS | WEBM | 0.617 | 0.712 | 0.661 |
+sense | 0.592 | 0.821 | 0.688 | |
+stroke | 0.520 | 0.874 | 0.652 | |
MWEC | 0.596 | 0.821 | 0.691 | |
DT | WEBM | 0.552 | 0.429 | 0.482 |
+sense | 0.643 | 0.420 | 0.508 | |
+stroke | 0.515 | 0.438 | 0.473 | |
MWEC | 0.644 | 0.420 | 0.508 | |
DM | WEBM | 0.486 | 0.586 | 0.531 |
+sense | 0.571 | 0.690 | 0.625 | |
+stroke | 0.528 | 0.655 | 0.585 | |
MWEC | 0.633 | 0.655 | 0.644 |
自Word2Vec提出后,文本的语义表示近年来有许多新的发展,如BERT[29]等被设计用来解决一词多义问题,且效果也被证明优于传统词向量,考虑到相对于Word2Vec词向量,BERT词向量的训练需要大量的语料支撑,使用BERT-wwm训练子词的BERT向量并在金融领域的数据集上进行对比实验,结果如表7所示,MWEC方法的剪枝效果优于BERT向量的剪枝效果。
表7 实验对比结果
Table 7 Experimental Comparison Results
方法 | 精确率 | 召回率 | F1值 |
BERT(0.85) | 0.560 | 0.728 | 0.633 |
BERT(0.80) | 0.546 | 0.850 | 0.665 |
+sense | 0.596 | 0.796 | 0.682 |
+stroke | 0.606 | 0.856 | 0.710 |
MWEC | 0.655 | 0.773 | 0.709 |
通过观察发现子词的BERT向量之间的余弦相似度普遍偏高,但子词的BERT向量表示不能体现子词间的相关性差异,例如利用N-gram候选机制得到的候选词“点分”和“新冠肺炎”,“点”和“分”的余弦相似度为0.927,“新冠”和“肺炎”的余弦相似度为0.808。实验中,MWEC方法的剪枝效果优于BERT向量的剪枝效果,这是由于BERT训练的向量是基于字符级和句子级的,利用句子级向量生成词级的词向量,语义表示能力会有所下降。BERT对句子进行编码的向量存在各向异性,向量值会受句子中词在所有训练语料里的词频影响,导致高频词编码的句向量距离更近,更集中在原点附近[30]。这会导致即使一个高频词和一个低频词的语义是等价的,但词频的差异也会带来很大的距离偏差,词向量的距离就不能很好地代表语义相关性,无法体现向量在剪枝过程中的作用。
5 结语
传统的词向量具有训练瓶颈的问题,即词向量的质量达到一定水平之后,很难通过增加语料库的大小来提升词向量的质量。
本文提出的MWEC新词发现方法在WEBM方法的基础上引入中文知网和汉字笔画知识库,使得词向量具有更好的语义表达能力,MWEC方法中的多语义词向量在剪枝时能够解决中文词语的一词多义问题,提升N-gram候选词集剪枝的效果。在金融、体育、旅游、音乐4个领域数据集上的实验结果表明,MWEC方法针对领域中文文本构建多语义词向量能大大提升中文新词发现的效果,这对以词向量剪枝进行无监督的新词发现方法的发展以及针对多领域中文文本的多语义词向量构建有一定促进作用,同时为无监督的领域词提取、关键词提取等信息抽取任务提供了研究思路。本研究的候选词生成词策略对低频词不敏感,未来研究可以关注候选词的生成策略,进一步发现网络文本中的低频新词。
边栏推荐
- Duplicate disk: recommended system - negative sampling strategy
- Stack and queue - 239. Sliding window maximum
- nodejs启动mqtt服务报错SchemaError: Expected `schema` to be an object or boolean问题解决
- 牛市还将继续,拿好手里的币 2021-05-08
- 06_ UE4 advanced_ Set up a large map using the terrain tool
- SHIB(柴犬币)一月涨幅数百倍,百倍币需具备哪些核心要素?2021-05-09
- 一个List到底能存多大的数据呢?
- Binary tree related knowledge
- 【Redis】② Redis通用命令;Redis 为什么这么快?;Redis 的数据类型
- J9 number theory: what is Dao mode? Obstacles to the development of Dao
猜你喜欢

对“DOF: A Demand-oriented Framework for ImageDenoising“的理解

NVIDIA cudnn learning

OPENCV学习DAY6

Piziheng embedded: the method of making source code into lib Library under MCU Xpress IDE and its difference with IAR and MDK

The bull market is not over yet, and there is still 2021-05-18 in the second half

MySQL——多版本并发控制(MVCC)

12.神经网络模型

Leetcode high frequency question 66. add one, give you an array to represent numbers, then add one to return the result

MPLS实验

"Animal coin" is fierce, trap or opportunity? 2021-05-12
随机推荐
SHIB(柴犬币)一月涨幅数百倍,百倍币需具备哪些核心要素?2021-05-09
二进制表示--2的幂
多任务编程
牛市还没有结束,还有下半场 2021-05-18
计算物理期刊修改
Nest.js 用了 Express 但也没完全用
FreeRTOS personal notes - message queue
Find the intermediate node of the linked list
Binary tree 101. Symmetric binary tree
如何用120行代码,实现一个交互完整的拖拽上传组件?
MySQL - database log
Binary tree - 654. Maximum binary tree
redis的使用
Js理解之路:Js常见的6中继承方式
Stack and queue - 347. Top k high frequency elements
Opencv learning Day6
Markdown writing platform
Binary tree - 226. Flip binary tree
Stack and queue - 239. Sliding window maximum
SSM environment integration