当前位置:网站首页>60 Feature Engineering Operations: Using Custom Aggregate Functions【Favorites】
60 Feature Engineering Operations: Using Custom Aggregate Functions【Favorites】
2022-08-02 02:13:00 【SeafyLiang】
参考资料:https://mp.weixin.qq.com/s/ezLKKvw4G1pQv3SiBy6X-A
60种特征工程操作:使用自定义聚合函数
- 简介
- 内置的聚合函数
- 自定义聚合函数
- median
- variation_coefficient
- variance
- skewness
- kurtosis
- standard_deviation
- large_standard_deviation
- variation_coefficient
- variance_std_ratio
- ratio_beyond_r_sigma
- range_ratio
- has_duplicate_max
- has_duplicate_min
- has_duplicate
- count_duplicate_max
- count_duplicate_min
- count_duplicate
- sum_values
- log_return
- realized_volatility
- realized_abs_skew
- realized_skew
- realized_vol_skew
- realized_quarticity
- count_unique
- count
- maximum_drawdown
- maximum_drawup
- drawdown_duration
- drawup_duration
- max_over_min
- mean_n_absolute_max
- count_above
- count_below
- number_peaks
- mean_abs_change
- mean_change
- mean_second_derivative_central
- root_mean_square
- absolute_sum_of_changes
- longest_strike_below_mean
- longest_strike_above_mean
- count_above_mean
- count_below_mean
- last_location_of_maximum
- first_location_of_maximum
- last_location_of_minimum
- first_location_of_minimum
- percentage_of_reoccurring_values_to_all_values
- percentage_of_reoccurring_datapoints_to_all_datapoints
- sum_of_reoccurring_values
- sum_of_reoccurring_data_points
- ratio_value_number_to_time_series_length
- abs_energy
- quantile
- number_crossing_m
- absolute_maximum
- value_count
- range_count
- mean_diff
简介
agg是一个聚合函数,使用指定轴上的一个或多个操作进行聚合.通过agg函数,可以同时对多列进行提取特征,非常适合用于特征工程.
内置的聚合函数
在Pandas内部支持了13中聚合函数,可以在分组之后进行使用:
- mean():分组均值
- sum():分组求和
- size():分组个数
- count():分组大小
- std():分组标准差
- var():分组方差
- sem():均值误差
- describe():分组描述
- first():分组第一个元素
- last():分组最后一个元素
- nth():分组第N个元素
- min():分组最小值
- max():分组最大值
案例如下,有多种使用方式可供选择:
# 定义模型
df = pd.DataFrame({
'group':[1,1,2,2],
'values':[4,1,1,2],
'values2':[0,1,1,2]
})
# 分组对两列求均值
df.groupby('group').mean()
# 分组对两列求均值、标准差
df.groupby('group').agg([np.mean,np.std])
# 分组对两列分别聚合
df.groupby('group').agg(
{
'values':['mean','median'],
'values2':['mean','std']}
)
自定义聚合函数
如果在Pandas内部的聚合函数不满足要求,也可以自定义聚合函数搭配使用
median
def median(x):
return np.median(x)
variation_coefficient
def variation_coefficient(x):
mean = np.mean(x)
if mean != 0:
return np.std(x) / mean
else:
return np.nan
variance
def variance(x):
return np.var(x)
skewness
def skewness(x):
if not isinstance(x, pd.Series):
x = pd.Series(x)
return pd.Series.skew(x)
kurtosis
def kurtosis(x):
if not isinstance(x, pd.Series):
x = pd.Series(x)
return pd.Series.kurtosis(x)
standard_deviation
def standard_deviation(x):
return np.std(x)
large_standard_deviation
def large_standard_deviation(x):
if (np.max(x)-np.min(x)) == 0:
return np.nan
else:
return np.std(x)/(np.max(x)-np.min(x))
variation_coefficient
def variation_coefficient(x):
mean = np.mean(x)
if mean != 0:
return np.std(x) / mean
else:
return np.nan
variance_std_ratio
def variance_std_ratio(x):
y = np.var(x)
if y != 0:
return y/np.sqrt(y)
else:
return np.nan
ratio_beyond_r_sigma
def ratio_beyond_r_sigma(x, r):
if x.size == 0:
return np.nan
else:
return np.sum(np.abs(x - np.mean(x)) > r * np.asarray(np.std(x))) / x.size
range_ratio
def range_ratio(x):
mean_median_difference = np.abs(np.mean(x) - np.median(x))
max_min_difference = np.max(x) - np.min(x)
if max_min_difference == 0:
return np.nan
else:
return mean_median_difference / max_min_difference
has_duplicate_max
def has_duplicate_max(x):
return np.sum(x == np.max(x)) >= 2
has_duplicate_min
def has_duplicate_min(x):
return np.sum(x == np.min(x)) >= 2
has_duplicate
def has_duplicate(x):
return x.size != np.unique(x).size
count_duplicate_max
def count_duplicate_max(x):
return np.sum(x == np.max(x))
count_duplicate_min
def count_duplicate_min(x):
return np.sum(x == np.min(x))
count_duplicate
def count_duplicate(x):
return x.size - np.unique(x).size
sum_values
def sum_values(x):
if len(x) == 0:
return 0
return np.sum(x)
log_return
def log_return(list_stock_prices):
return np.log(list_stock_prices).diff()
realized_volatility
def realized_volatility(series):
return np.sqrt(np.sum(series**2))
realized_abs_skew
def realized_abs_skew(series):
return np.power(np.abs(np.sum(series**3)),1/3)
realized_skew
def realized_skew(series):
return np.sign(np.sum(series**3))*np.power(np.abs(np.sum(series**3)),1/3)
realized_vol_skew
def realized_vol_skew(series):
return np.power(np.abs(np.sum(series**6)),1/6)
realized_quarticity
def realized_quarticity(series):
return np.power(np.sum(series**4),1/4)
count_unique
def count_unique(series):
return len(np.unique(series))
count
def count(series):
return series.size
maximum_drawdown
def maximum_drawdown(series):
series = np.asarray(series)
if len(series)<2:
return 0
k = series[np.argmax(np.maximum.accumulate(series) - series)]
i = np.argmax(np.maximum.accumulate(series) - series)
if len(series[:i])<1:
return np.NaN
else:
j = np.max(series[:i])
return j-k
maximum_drawup
def maximum_drawup(series):
series = np.asarray(series)
if len(series)<2:
return 0
series = - series
k = series[np.argmax(np.maximum.accumulate(series) - series)]
i = np.argmax(np.maximum.accumulate(series) - series)
if len(series[:i])<1:
return np.NaN
else:
j = np.max(series[:i])
return j-k
drawdown_duration
def drawdown_duration(series):
series = np.asarray(series)
if len(series)<2:
return 0
k = np.argmax(np.maximum.accumulate(series) - series)
i = np.argmax(np.maximum.accumulate(series) - series)
if len(series[:i]) == 0:
j=k
else:
j = np.argmax(series[:i])
return k-j
drawup_duration
def drawup_duration(series):
series = np.asarray(series)
if len(series)<2:
return 0
series=-series
k = np.argmax(np.maximum.accumulate(series) - series)
i = np.argmax(np.maximum.accumulate(series) - series)
if len(series[:i]) == 0:
j=k
else:
j = np.argmax(series[:i])
return k-j
max_over_min
def max_over_min(series):
if len(series)<2:
return 0
if np.min(series) == 0:
return np.nan
return np.max(series)/np.min(series)
mean_n_absolute_max
def mean_n_absolute_max(x, number_of_maxima = 1):
""" Calculates the arithmetic mean of the n absolute maximum values of the time series."""
assert (
number_of_maxima > 0
), f" number_of_maxima={
number_of_maxima} which is not greater than 1"
n_absolute_maximum_values = np.sort(np.absolute(x))[-number_of_maxima:]
return np.mean(n_absolute_maximum_values) if len(x) > number_of_maxima else np.NaN
count_above
def count_above(x, t):
if len(x)==0:
return np.nan
else:
return np.sum(x >= t) / len(x)
count_below
def count_below(x, t):
if len(x)==0:
return np.nan
else:
return np.sum(x <= t) / len(x)
number_peaks
def number_peaks(x, n):
x_reduced = x[n:-n]
res = None
for i in range(1, n + 1):
result_first = x_reduced > _roll(x, i)[n:-n]
if res is None:
res = result_first
else:
res &= result_first
res &= x_reduced > _roll(x, -i)[n:-n]
return np.sum(res)
mean_abs_change
def mean_abs_change(x):
return np.mean(np.abs(np.diff(x)))
mean_change
def mean_change(x):
x = np.asarray(x)
return (x[-1] - x[0]) / (len(x) - 1) if len(x) > 1 else np.NaN
mean_second_derivative_central
def mean_second_derivative_central(x):
x = np.asarray(x)
return (x[-1] - x[-2] - x[1] + x[0]) / (2 * (len(x) - 2)) if len(x) > 2 else np.NaN
root_mean_square
def root_mean_square(x):
return np.sqrt(np.mean(np.square(x))) if len(x) > 0 else np.NaN
absolute_sum_of_changes
def absolute_sum_of_changes(x):
return np.sum(np.abs(np.diff(x)))
longest_strike_below_mean
def longest_strike_below_mean(x):
if not isinstance(x, (np.ndarray, pd.Series)):
x = np.asarray(x)
return np.max(_get_length_sequences_where(x < np.mean(x))) if x.size > 0 else 0
longest_strike_above_mean
def longest_strike_above_mean(x):
if not isinstance(x, (np.ndarray, pd.Series)):
x = np.asarray(x)
return np.max(_get_length_sequences_where(x > np.mean(x))) if x.size > 0 else 0
count_above_mean
def count_above_mean(x):
m = np.mean(x)
return np.where(x > m)[0].size
count_below_mean
def count_below_mean(x):
m = np.mean(x)
return np.where(x < m)[0].size
last_location_of_maximum
def last_location_of_maximum(x):
x = np.asarray(x)
return 1.0 - np.argmax(x[::-1]) / len(x) if len(x) > 0 else np.NaN
first_location_of_maximum
def first_location_of_maximum(x):
if not isinstance(x, (np.ndarray, pd.Series)):
x = np.asarray(x)
return np.argmax(x) / len(x) if len(x) > 0 else np.NaN
last_location_of_minimum
def last_location_of_minimum(x):
x = np.asarray(x)
return 1.0 - np.argmin(x[::-1]) / len(x) if len(x) > 0 else np.NaN
first_location_of_minimum
def first_location_of_minimum(x):
if not isinstance(x, (np.ndarray, pd.Series)):
x = np.asarray(x)
return np.argmin(x) / len(x) if len(x) > 0 else np.NaN
percentage_of_reoccurring_values_to_all_values
def percentage_of_reoccurring_values_to_all_values(x):
if len(x) == 0:
return np.nan
unique, counts = np.unique(x, return_counts=True)
if counts.shape[0] == 0:
return 0
return np.sum(counts > 1) / float(counts.shape[0])
percentage_of_reoccurring_datapoints_to_all_datapoints
def percentage_of_reoccurring_datapoints_to_all_datapoints(x):
if len(x) == 0:
return np.nan
if not isinstance(x, pd.Series):
x = pd.Series(x)
value_counts = x.value_counts()
reoccuring_values = value_counts[value_counts > 1].sum()
if np.isnan(reoccuring_values):
return 0
return reoccuring_values / x.size
sum_of_reoccurring_values
def sum_of_reoccurring_values(x):
unique, counts = np.unique(x, return_counts=True)
counts[counts < 2] = 0
counts[counts > 1] = 1
return np.sum(counts * unique)
sum_of_reoccurring_data_points
def sum_of_reoccurring_data_points(x):
unique, counts = np.unique(x, return_counts=True)
counts[counts < 2] = 0
return np.sum(counts * unique)
ratio_value_number_to_time_series_length
def ratio_value_number_to_time_series_length(x):
if not isinstance(x, (np.ndarray, pd.Series)):
x = np.asarray(x)
if x.size == 0:
return np.nan
return np.unique(x).size / x.size
abs_energy
def abs_energy(x):
if not isinstance(x, (np.ndarray, pd.Series)):
x = np.asarray(x)
return np.dot(x, x)
quantile
def quantile(x, q):
if len(x) == 0:
return np.NaN
return np.quantile(x, q)
number_crossing_m
def number_crossing_m(x, m):
if not isinstance(x, (np.ndarray, pd.Series)):
x = np.asarray(x)
# From https://stackoverflow.com/questions/3843017/efficiently-detect-sign-changes-in-python
positive = x > m
return np.where(np.diff(positive))[0].size
absolute_maximum
def absolute_maximum(x):
return np.max(np.absolute(x)) if len(x) > 0 else np.NaN
value_count
def value_count(x, value):
if not isinstance(x, (np.ndarray, pd.Series)):
x = np.asarray(x)
if np.isnan(value):
return np.isnan(x).sum()
else:
return x[x == value].size
range_count
def range_count(x, min, max):
return np.sum((x >= min) & (x < max))
mean_diff
def mean_diff(x):
return np.nanmean(np.diff(x.values))
边栏推荐
- leetcode / anagram in string - some permutation of s1 string is a substring of s2
- 2023年起,这些地区软考成绩低于45分也能拿证
- ¶Backtop 回到顶部 不生效
- 力扣(LeetCode)213. 打家劫舍 II(2022.08.01)
- ¶ Backtop back to the top is not effective
- A full set of common interview questions for software testing functional testing [open thinking questions] interview summary 4-3
- Good News | AR opens a new model for the textile industry, and ALVA Systems wins another award!
- CodeTon Round 2 D. Magical Array 规律
- Huawei's 5-year female test engineer resigns: what a painful realization...
- Multi-Party Threshold Private Set Intersection with Sublinear Communication-2021: Interpretation
猜你喜欢

Handwriting a blogging platform ~ Day 3

Analysis of volatile principle

【LeetCode每日一题】——103.二叉树的锯齿形层序遍历
Check if IP or port is blocked
2022-07-30 mysql8 executes slow SQL-Q17 analysis
Ringtone 1161. Maximum In-Layer Elements and

Scheduled tasks for distributed applications in Golang

Multi-Party Threshold Private Set Intersection with Sublinear Communication-2021:解读
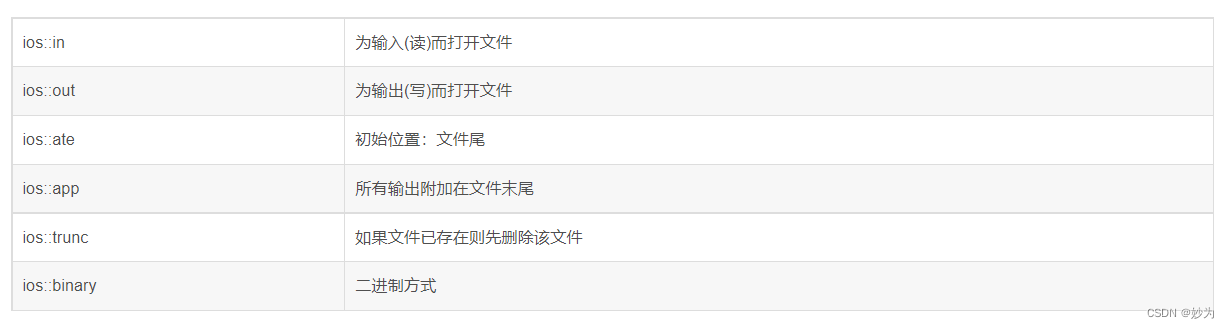
ofstream,ifstream,fstream read and write files
The ultra-large-scale industrial practical semantic segmentation dataset PSSL and pre-training model are open source!
随机推荐
LeetCode Review Diary: 153. Find the Minimum Value in a Rotated Sort Array
2022 Henan Youth Training League Game (3)
leetcode/字符串中的变位词-s1字符串的某个排列是s2的子串
哈希冲突和一致性哈希
Software testing Interface automation testing Pytest framework encapsulates requests library Encapsulates unified request and multiple base path processing Interface association encapsulation Test cas
雇用WordPress开发人员:4个实用的方法
¶Backtop 回到顶部 不生效
Can Youxuan database import wrongly be restored?
LeetCode brushing diary: 53, the largest sub-array and
垃圾回收器CMS和G1
数据链路层的数据传输
3.Bean的作用域与生命周期
Yunhe Enmo: Let the value of the commercial database era continue to prosper in the openGauss ecosystem
"NetEase Internship" Weekly Diary (2)
Day116. Shangyitong: Details of appointment registration ※
MySQL8 download, start, configure, verify
检查IP或端口是否被封
Redis Persistence - RDB and AOF
Record the pits where an error occurs when an array is converted to a collection, and try to use an array of packaging types for conversion
【LeetCode每日一题】——654.最大二叉树