当前位置:网站首页>Thinking on large file processing (upload, download)
Thinking on large file processing (upload, download)
2022-06-30 17:45:00 【twinkle||cll】
Document processingIt has always been the heart disease of the front-end people , How to control the file size , The file is too big to upload , File download takes too long ,tcp Just disconnect
effect
In order to facilitate meaningful learning , Let's start with the renderings , If not, just return directly , Don't waste everyone's time .
Upload files

File upload to achieve , Patch uploading , Pause upload , Resume upload , File merging, etc
File download
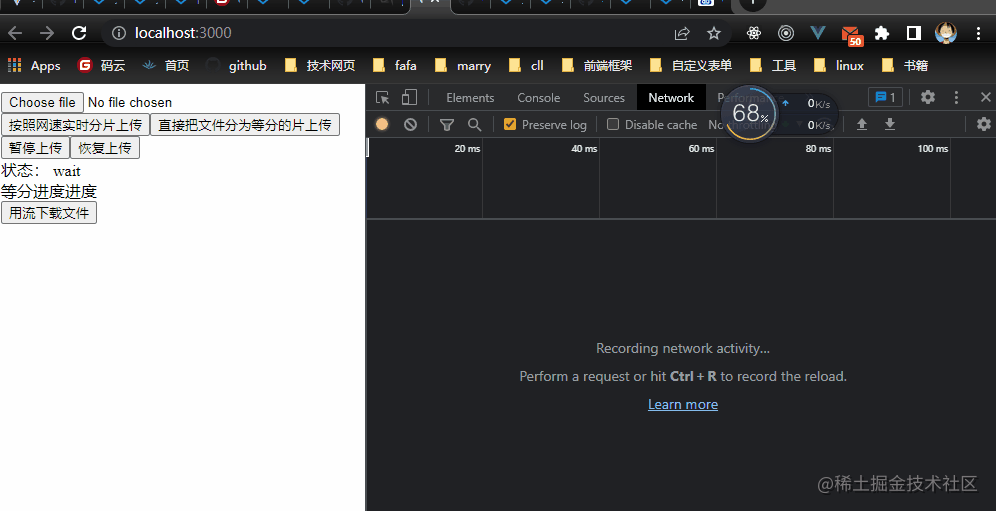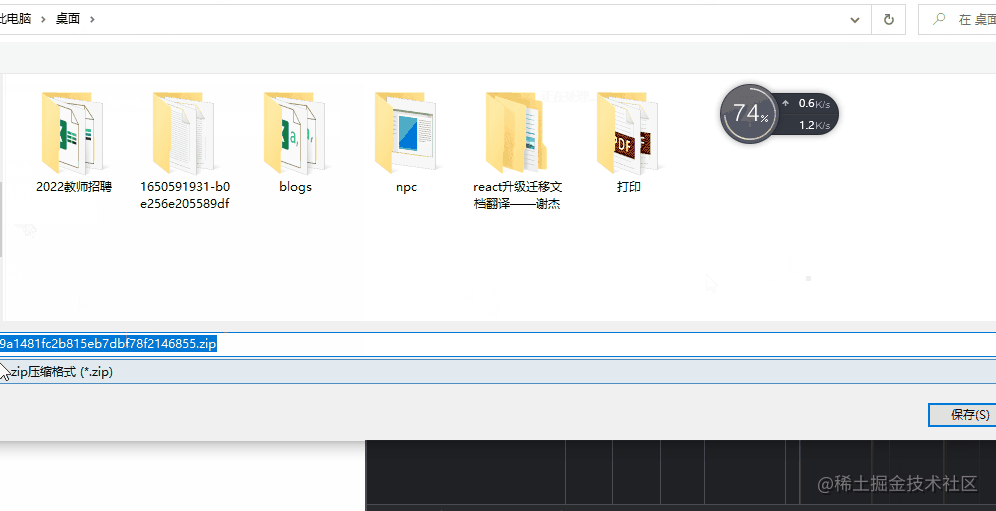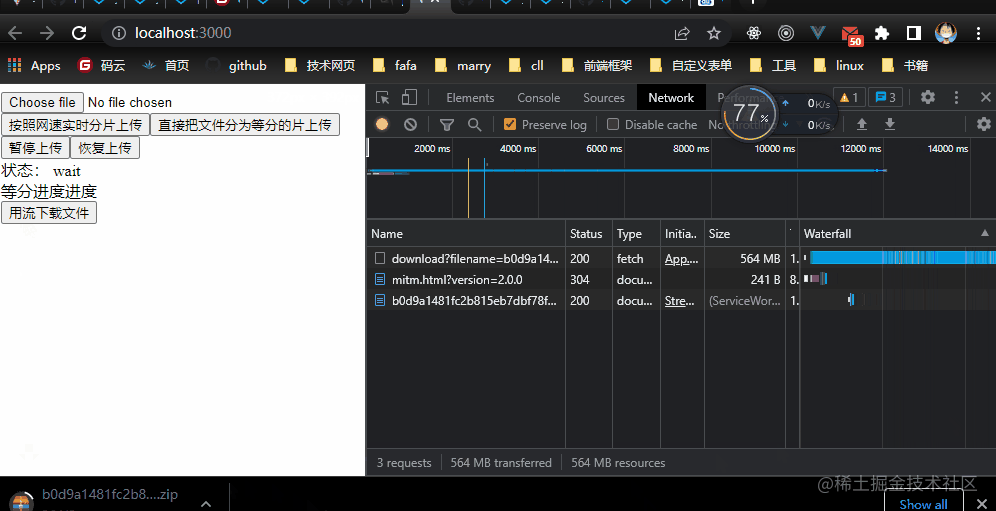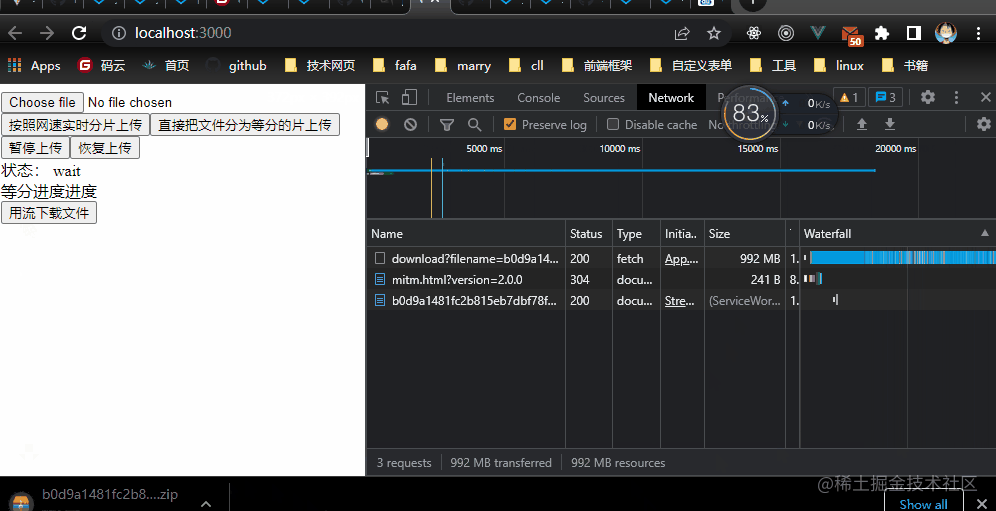
For testing purposes , I uploaded 1 individual 1g Big files to download , The front end uses
streamTo save the file , See this for details api TransformStream
Text
The address of this project is : https://github.com/cll123456/deal-big-file Self delivery required
Upload
Please read the following article with the following questions
- How to calculate the of a file hash, How to do the calculation hash It's the fastest
- What are the ways of file fragmentation
- How to control fragment upload http request ( Control concurrent ), There are too many fragments of large files , Directly break the network
- How to pause upload
- How to resume uploading, etc
Calculation file hash
In the calculation file hash The way , There are mainly the following : Calculation of the total quantity of slices hash、 Sampling calculation hash.
In both ways , Separately, you can use web-work And browser idle (requestIdleCallback) To achieve .
web-workIf you don't understand, you can see here : https://juejin.cn/post/7091068088975622175requestIdleCallbackIf you don't understand, you can see here : https://juejin.cn/post/7069597252473815053
Next, let's calculate the of the file hash, Calculate the hash Need to use spark-md5 This library ,
Full volume calculation document hash
export async function calcHashSync(file: File) {
// Fragment the file , Each file is divided into 2MB, You can control it by yourself
const size = 2 * 1024 * 1024;
let chunks: any[] = [];
let cur = 0;
while (cur < file.size) {
chunks.push({
file: file.slice(cur, cur + size) });
cur += size;
}
// You can get the progress from the current calculation to the first few files
let hashProgress = 0
return new Promise(resolve => {
const spark = new SparkMD5.ArrayBuffer();
let count = 0;
const loadNext = (index: number) => {
const reader = new FileReader();
reader.readAsArrayBuffer(chunks[index].file);
reader.onload = e => {
// accumulator Can't rely on index,
count++;
// Incremental calculation md5
spark.append(e.target?.result as ArrayBuffer);
if (count === chunks.length) {
// Notification thread , End of calculation
hashProgress = 100;
resolve({
hashValue: spark.end(), progress: hashProgress });
} else {
// End of each block calculation , Just notify the progress
hashProgress += 100 / chunks.length
// Calculate next
loadNext(count);
}
};
};
// start-up
loadNext(0);
});
}
Full volume calculation document hash, When the file is small, the calculation is very fast , But in the case of large files , Calculate the hash It's going to be very slow , And affect the main process
Sampling calculation document hash
Sampling is to take part of the file to continue , The principle is as follows :
/** * Sampling calculation hash value Probably 1G File cost 1S Time for * * Using sampling hash The way to calculate hash * We are calculating hash When , Convert the oversized file to 2M Split to get another chunks Array , * First element (chunks[0]) And the last element (chunks[-1]) We'll take it all * Other elements (chunks[1,2,3,4....]) Let's do another segmentation , At this time, the segmentation is a super small size, such as 2kb, We take * The head of each element , The tail , In the middle of the 2kb. * Finally, they form a new file , Let's fully calculate the of this new document hash value . * @param file {File} * @returns */
export async function calcHashSample(file: File) {
return new Promise(resolve => {
const spark = new SparkMD5.ArrayBuffer();
const reader = new FileReader();
// file size
const size = file.size;
let offset = 2 * 1024 * 1024;
let chunks = [file.slice(0, offset)];
// front 2mb The data of
let cur = offset;
while (cur < size) {
// The last piece is all in
if (cur + offset >= size) {
chunks.push(file.slice(cur, cur + offset));
} else {
// In the middle of the Two bytes before, middle and back
const mid = cur + offset / 2;
const end = cur + offset;
chunks.push(file.slice(cur, cur + 2));
chunks.push(file.slice(mid, mid + 2));
chunks.push(file.slice(end - 2, end));
}
// Take the first two bytes
cur += offset;
}
// Splicing
reader.readAsArrayBuffer(new Blob(chunks));
// Last 100K
reader.onload = e => {
spark.append(e.target?.result as ArrayBuffer);
resolve({
hashValue: spark.end(), progress: 100 });
};
});
}
This design is not found to be very flexible , What a person
On the basis of these two , We can also use web-worker and requestIdleCallback To achieve , The source code in hereヾ(≧▽≦*)o
Here's my computer configuration , The computer configuration given to me by the company is quite lower, 8g Old machines with memory . Calculation (3.3g Of documents )hash The results are as follows :

The result is clear , No matter how you do it , Are slower than the sampling .
The way of file fragmentation
Here you may say , Isn't the way of file segmentation equal , In fact, you can also adjust the size of the partition in real time according to the speed of network speed and upload !
const handleUpload1 = async (file:File) => {
if (!file) return;
const fileSize = file.size
let offset = 2 * 1024 * 1024
let cur = 0
let count = 0
// The size of each moment needs to be preserved , Facilitate background merging
const chunksSize = [0, 2 * 1024 * 1024]
const obj = await calcHashSample(file) as {
hashValue: string };
fileHash.value = obj.hashValue;
//todo If you judge whether the file exists, you don't need to upload , That is, second pass
while (cur < fileSize) {
const chunk = file.slice(cur, cur + offset)
cur += offset
const chunkName = fileHash.value + "-" + count;
const form = new FormData();
form.append("chunk", chunk);
form.append("hash", chunkName);
form.append("filename", file.name);
form.append("fileHash", fileHash.value);
form.append("size", chunk.size.toString());
let start = new Date().getTime()
// todo Upload a single fragment
const now = new Date().getTime()
const time = ((now - start) / 1000).toFixed(4)
let rate = Number(time) / 10
// There are maximum and minimum rates Consider smoother filtering such as 1/tan
if (rate < 0.5) rate = 0.5
if (rate > 2) rate = 2
offset = parseInt((offset / rate).toString())
chunksSize.push(offset)
count++
}
//todo You can send the merge operation
}

ATTENTION!!! If so, the uploaded file fragments , If you disconnect halfway, you can't continue the transmission ( The network speed is different every moment ), Unless every upload puts chunksSize( Sliced array ) Save it
control http request ( Control concurrent )
control http We can change our mind , Is it Control asynchronous tasks Well ?
/** * Asynchronous control pool - Asynchronous controller * @param concurrency Maximum number of concurrency * @param iterable Parameters of asynchronously controlled functions * @param iteratorFn Asynchronous control function */
export async function* asyncPool<IN, OUT>(concurrency: number, iterable: ReadonlyArray<IN>, iteratorFn: (item: IN, iterable?: ReadonlyArray<IN>) => Promise<OUT>): AsyncIterableIterator<OUT> {
// Preach set To preserve promise
const executing = new Set<Promise<IN>>();
// Consumption function
async function consume() {
const [promise, value] = await Promise.race(executing) as unknown as [Promise<IN>, OUT];
executing.delete(promise);
return value;
}
// Traversal parameter variable
for (const item of iterable) {
const promise = (async () => await iteratorFn(item, iterable))().then(
value => [promise, value]
) as Promise<IN>;
executing.add(promise);
// Exceed the maximum limit , Need to wait
if (executing.size >= concurrency) {
yield await consume();
}
}
// Continue to consume when you exist promise
while (executing.size) {
yield await consume();
}
}
Pause request
Pause request , It's also very simple , In the original XMLHttpRequest There's a way to do it xhr?.abort(), While sending the request , When sending a request , We put it in an array , Then you can directly call abort The method .
In the packaging request When , We asked for an requestList Just fine :
export function request({
url,
method = "post",
data,
onProgress = e => e,
headers = {
},
requestList
}: IRequest) {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest();
xhr.upload.onprogress = onProgress
// Send a request
xhr.open(method, baseUrl + url);
// Put in other parameters
Object.keys(headers).forEach(key =>
xhr.setRequestHeader(key, headers[key])
);
xhr.send(data);
xhr.onreadystatechange = e => {
// The request was successful
if (xhr.readyState === 4) {
if (xhr.status === 200) {
if (requestList) {
// Delete the list after success
const i = requestList.findIndex(req => req === xhr)
requestList.splice(i, 1)
}
// Get the structure of the service response
const resp = JSON.parse(xhr.response);
// This code It's stipulated by the backstage ,200 Is the correct response ,500 It's abnormal
if (resp.code === 200) {
// Successful operation
resolve({
data: (e.target as any)?.response
});
} else {
reject(' Wrong report eldest brother ')
}
} else if (xhr.status === 500) {
reject(' Wrong report eldest brother ')
}
}
};
// Deposit request
requestList?.push(xhr)
});
}
With the request array , So we want to traverse the request array directly for the time being , call
abortMethod
Resume upload
Resume uploading is to judge which fragments already exist , There is no need to upload , Continue uploading if it doesn't exist . So we need an interface ,verify Pass in Of documents hash, File name , Determine whether the file exists or how many files have been uploaded .
/** * Verify that the file exists * @param req * @param res */
async handleVerify(req: http.IncomingMessage, res: http.ServerResponse) {
// analysis post Request data
const data = await resolvePost(req) as {
filename: string, hash: string }
const {
filename, hash } = data
// Get file suffix name
const ext = extractExt(filename)
const filePath = path.resolve(this.UPLOAD_DIR, `${
hash}${
ext}`)
// Does the file exist
let uploaded = false
let uploadedList: string[] = []
if (fse.existsSync(filePath)) {
uploaded = true
} else {
// The file is not completely uploaded , But there may be some slices uploaded
uploadedList = await getUploadedList(path.resolve(this.UPLOAD_DIR, hash))
}
res.end(
JSON.stringify({
code: 200,
uploaded,
uploadedList // Filter weird hidden files
})
)
}
Be careful , You also need to delete the last part of the fragment at each verification
A few piecesfile , Prevent the last few files from being incomplete uploaded .
Merge files
The merged file is well understood , Is to merge all the fragments , But one thing to note is , We can't read all the files into memory and merge them , Instead, use the flow method to merge , Read and write files . When writing files, you need to ensure the order , Otherwise, the file may be damaged .
This part of the code will be more , Interested students can see Source code
File download
For file download , The back end is actually very simple , Just return a stream , as follows :
/** * File download * @param req * @param res */
async handleDownload(req: http.IncomingMessage, res: http.ServerResponse) {
// analysis get Request parameters
const resp: UrlWithParsedQuery = await resolveGet(req)
// Get the file name
const filePath = path.resolve(this.UPLOAD_DIR, resp.query.filename as string)
// Judge whether the file exists
if (fse.existsSync(filePath)) {
// Create a stream to read the file and download
const stream = fse.createReadStream(filePath)
// write file
stream.pipe(res)
}
}
For the front end , We need to use a library , Namely streamsaver, This library calls TransformStream api To save the file in the browser in the local way of streaming . With this , That's very simple to use
const downloadFile = async () => {
// StreamSaver
// Download path
const url = 'http://localhost:4001/download?filename=b0d9a1481fc2b815eb7dbf78f2146855.zip'
// Create a file write stream
const fileStream = streamSaver.createWriteStream('b0d9a1481fc2b815eb7dbf78f2146855.zip')
// Send a request to download
fetch(url).then(res => {
const readableStream = res.body
// more optimized
if (window.WritableStream && readableStream?.pipeTo) {
return readableStream.pipeTo(fileStream)
.then(() => console.log('done writing'))
}
const writer = fileStream.getWriter()
const reader = res.body?.getReader()
const pump: any = () => reader?.read()
.then(res => res.done
? writer.close()
: writer.write(res.value).then(pump))
pump()
})
}
边栏推荐
- [Architecture] 1366- how to draw an excellent architecture diagram
- 应届生毕业之后先就业还是先择业?
- 3D chart effectively improves the level of large data screen
- Booking UI effect implemented by svg
- Nielseniq welcomes dawn E. Norvell, head of retail lab, to accelerate the expansion of global retail strategy
- 4年工作经验,多线程间的5种通信方式都说不出来,你敢信?
- 5g business is officially commercial. What are the opportunities for radio and television?
- Send the injured baby for emergency medical treatment. Didi's driver ran five red lights in a row
- . Net ORM framework hisql practice - Chapter 1 - integrating hisql
- Bridge emqx cloud data to AWS IOT through the public network
猜你喜欢
大文件处理(上传,下载)思考

Rexroth hydraulic control check valve z2s10-1-3x/

将 EMQX Cloud 数据通过公网桥接到 AWS IoT

Property or method “approval1“ is not defined on the instance but referenced during render

Radio and television 5g officially set sail, attracting attention on how to apply the golden band
广电5G正式启航,黄金频段将如何应用引关注

K-line diagram must be read for quick start

Alibaba cloud disk sharing compressed package

Spin lock exploration

Write the simplest small program in C language Hello World
随机推荐
【C语言】详解线程 — 线程分离函数 pthread_detach
Shutter music recording playing audioplayers
5G业务正式商用,属于广电的机会在哪?
EMQ 助力青岛研博建设智慧水务平台
ROC-RK3566-PC使用10.1寸IPS触摸屏显示
水平视觉错误效果js特效代码
Booking UI effect implemented by svg
美国PARKER派克传感器P8S-GRFLX
万卷书 - 欧洲的门户 [The Gates of Europe]
Network: principle and practice of server network card group technology
Bridge emqx cloud data to AWS IOT through the public network
Ningx 1.20.2
面试突击60:什么情况会导致 MySQL 索引失效?
[sword finger offer] sword finger offer 53 - ii Missing numbers from 0 to n-1
腾讯云的一场硬仗
构建基本buildroot文件系统
24: Chapter 3: develop pass service: 7: user defined exceptions (to represent errors in the program); Create graceexceptionhandler to handle exceptions globally and uniformly (build JSON data of corre
Canvas cloud shape animation
Exploration and practice of "flow batch integration" in JD
Generate confrontation network, from dcgan to stylegan, pixel2pixel, face generation and image translation.