当前位置:网站首页>数仓4.0(二)------ 业务数据采集平台
数仓4.0(二)------ 业务数据采集平台
2022-08-03 07:49:00 【JiaXingNashishua】
目录
一:电商业务简介
1.1 电商业务流程
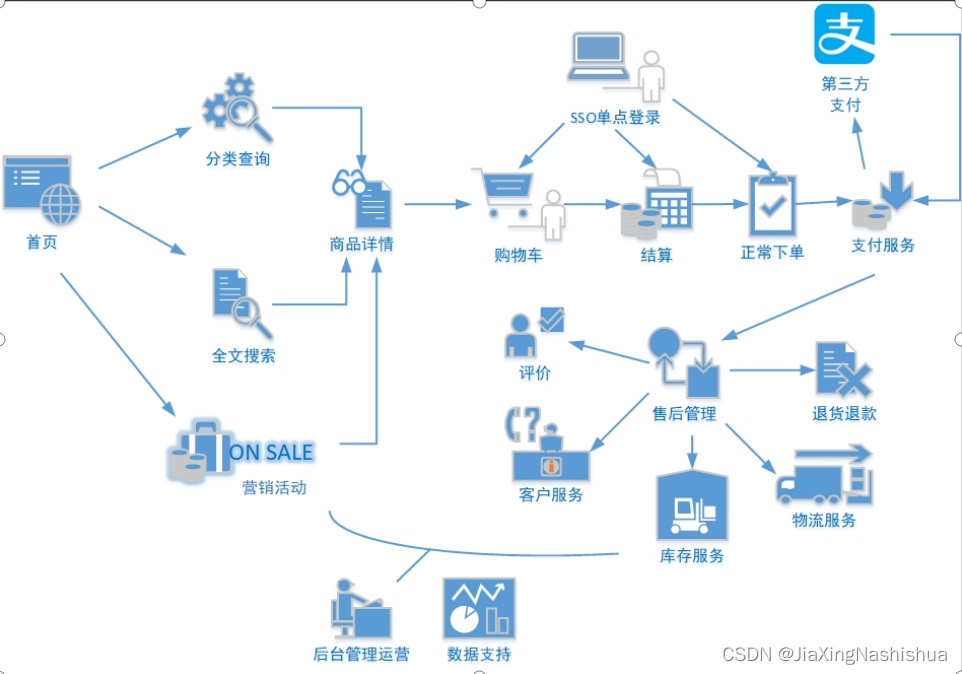
电商的业务流程可以以一个普通用户的浏览足迹为例进行说明,用户点开电商首页开始浏览,可能会通过分类查询也可能通过全文搜索寻找自己中意的商品,这些商品无疑都是存储在后台的管理系统中的。
当用户寻找到自己中意的商品,可能会想要购买,将商品添加到购物车后发现需要登录,登录后对商品进行结算,这时候购物车的管理和商品订单信息的生成都会对业务数据库产生影响,会生成相应的订单数据和支付数据。
订单正式生成之后,还会对订单进行跟踪处理,直到订单全部完成。
电商的主要业务流程包括用户前台浏览商品时的商品详情的管理,用户商品加入购物车进行支付时用户个人中心&支付服务的管理,用户支付完成后订单后台服务的管理,这些流程涉及到了十几个甚至几十个业务数据表,甚至更多。
1.2 电商常识
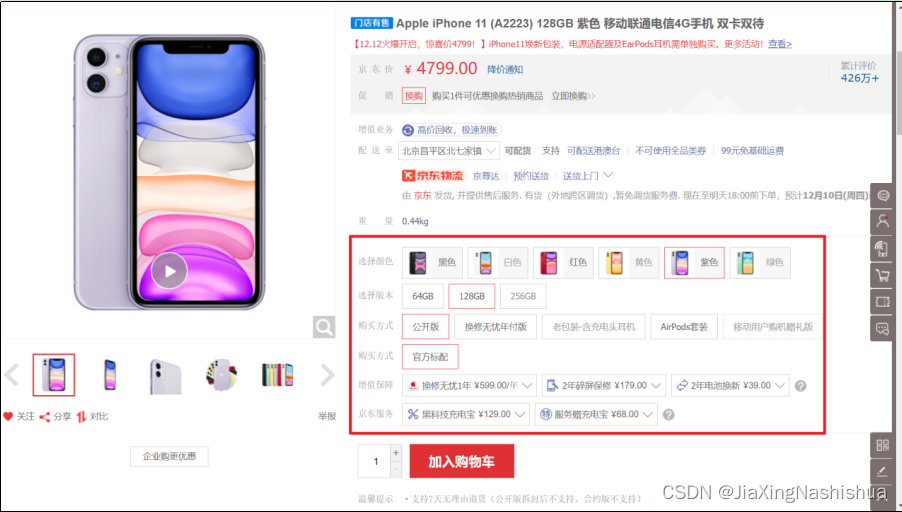
SKU:
SKU = Stock Keeping Unit(库存量基本单位)。现在已经被引申为产品统一编号的简称,每种产品均对应有唯一的SKU号。
SPU:
SPU(Standard Product Unit):是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息集合。
例如:iPhoneX手机就是SPU。一台银色、128G内存的、支持联通网络的iPhoneX,就是SKU。
平台属性:

销售属性:
二:业务数据采集模块
2.1 安装MySQL及配置
由于篇幅原因,这里就不记录安装MySQL的流程了。
2.2 业务数据生成
2.2.1 连接Mysql以及建表
通过MySQL可视化客户端(我用的是Navicat)连接数据库。
1)通过Navicat创建数据库
2)设置数据库名称为gmall,编码为utf-8,排序规则为utf8_general_ci
3)导入数据库结构脚本(gmall.sql)
注意:完成后,要记得右键,刷新一下对象浏览器,就可以看见数据库中的表了。
2.2.2 生成业务数据
1)在hadoop102的/opt/module/目录下创建db_log文件夹
2)把gmall2020-mock-db-2021-01-22.jar和application.properties上传到hadoop102的/opt/module/db_log路径上。
3)根据需求修改application.properties相关配置(主要修改主机名、数据库名、用户名及密码),这里注意,在第一次生成业务数据的时候,要将重置的配置修改为1,后续不要重置,所以改成0


4)并在该目录下执行,如下命令,生成2020-06-14日期数据
[[email protected] db_log]$ java -jar gmall2020-mock-db-2021-01-22.jar5)查看gmall数据库,观察是否有2020-06-14的数据出现
2.3 安装Sqoop
2.3.1 安装
1)上传安装包sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz到hadoop102的/opt/software路径中
2)解压sqoop安装包到指定目录
[[email protected] software]$ tar -zxf
sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/module/5)解压sqoop安装包到指定目录
[[email protected] module]$ mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop2.3.2 修改配置文件
1)进入到/opt/module/sqoop/conf目录,重命名配置文件
[[email protected] conf]$ mv sqoop-env-template.sh sqoop-env.sh2)修改配置文件
[[email protected] conf]$ vim sqoop-env.sh 增加如下内容
export HADOOP_COMMON_HOME=/opt/module/hadoop-3.1.3
export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3
export HIVE_HOME=/opt/module/hive
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7
export ZOOCFGDIR=/opt/module/zookeeper-3.5.7/conf2.3.3 拷贝JDBC驱动
1)将mysql-connector-java-5.1.48.jar 上传到/opt/software路径
2)进入到/opt/software/路径,拷贝jdbc驱动到sqoop的lib目录下。
[[email protected] software]$ cp mysql-connector-java-5.1.48.jar
/opt/module/sqoop/lib/2.3.4 验证Sqoop
(1)我们可以通过某一个command来验证sqoop配置是否正确:
[[email protected] sqoop]$ bin/sqoop help2.3.5 测试Sqoop是否能够成功连接数据库
[[email protected] sqoop]$ bin/sqoop list-databases --connect
jdbc:mysql://hadoop102:3306/ --username root --password 0000002.3.6 Sqoop基本使用
将mysql中user_info表数据导入到HDFS的/test路径
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/gmall \
--username root \
--password 000000 \
--table user_info \
--columns id,login_name \
--where "id>=10 and id<=30" \
--target-dir /test \
--delete-target-dir \
--fields-terminated-by '\t' \
--num-mappers 2 \
--split-by id2.4 同步策略
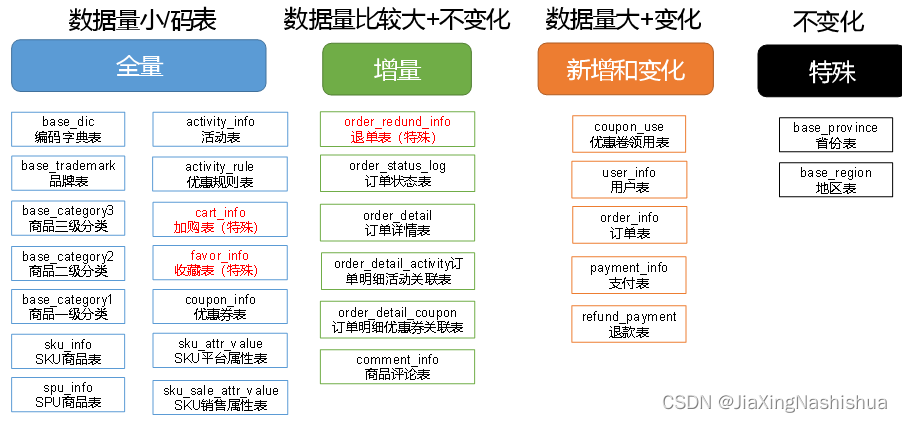
数据同步策略的类型包括:全量同步、增量同步、新增及变化同步、特殊情况
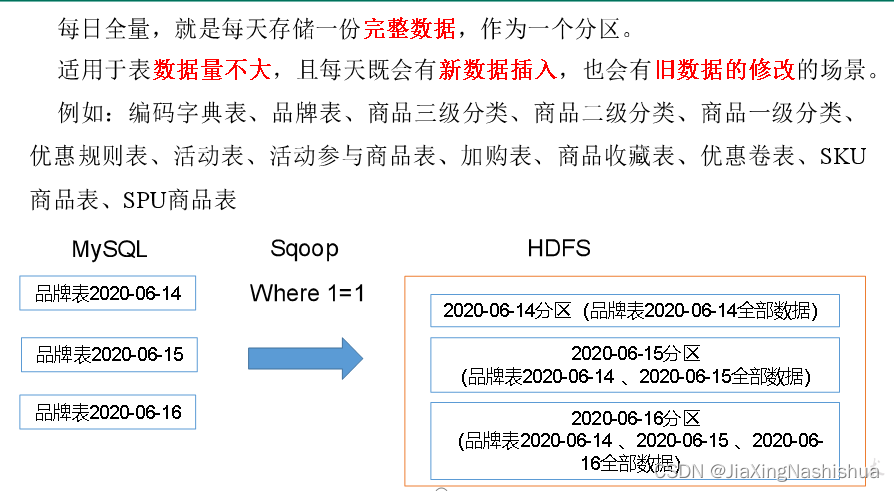
- 全量表:存储完整的数据。
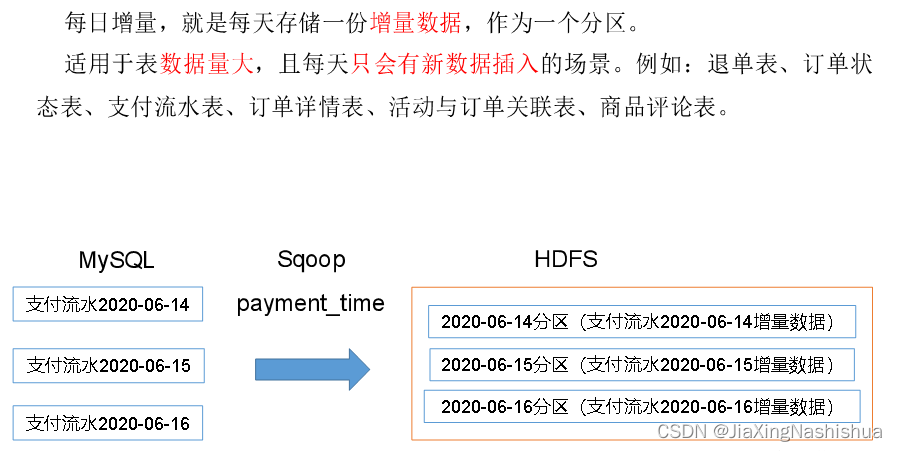
- 增量表:存储新增加的数据。
- 新增及变化表:存储新增加的数据和变化的数据。
- 特殊表:只需要存储一次。
2.4.1 全量同步策略
2.4.2 增量同步策略
2.4.3 新增及变化策略
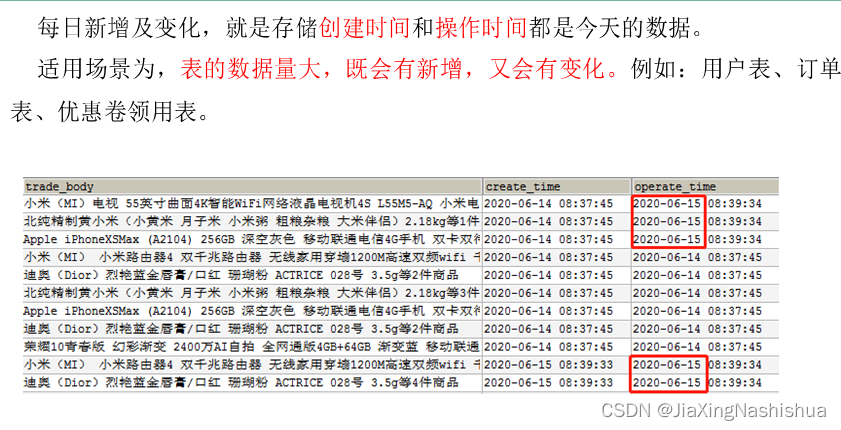
2.4.4 特殊策略
某些特殊的表,可不必遵循上述同步策略。例如某些不会发生变化的表(地区表,省份表,民族表)可以只存一份固定值。
2.5 业务数据导入HDFS
2.5.1 分析表同步策略
在生产环境,个别小公司,为了简单处理,所有表全量导入。
中大型公司,由于数据量比较大,还是严格按照同步策略导入数据。
2.5.2 业务数据首日同步脚本
由于篇幅原因,就不列出脚本代码了
2.5.3 业务数据每日同步脚本
由于篇幅原因,就不列出脚本代码了
2.5.4 项目经验
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用--input-null-string和--input-null-non-string两个参数。导入数据时采用--null-string和--null-non-string。
三:数据环境准备
1)把apache-hive-3.1.2-bin.tar.gz上传到Linux的/opt/software目录下
2)解压apache-hive-3.1.2-bin.tar.gz到/opt/module/目录下面
3)修改apache-hive-3.1.2-bin.tar.gz的名称为hive
4)修改/etc/profile.d/my_env.sh,添加环境变量,添加完后source一下,使环境变量生效
添加内容
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin5)解决日志Jar包冲突,进入/opt/module/hive/lib目录
3.2 Hive元数据配置到MySQL
3.2.1 拷贝驱动
将MySQL的JDBC驱动拷贝到Hive的lib目录下
[[email protected] lib]$ cp /opt/software/mysql-connector-java-5.1.27.jar
/opt/module/hive/lib/3.2.2 配置Metastore到MySQL
(1)在$HIVE_HOME/conf目录下新建hive-site.xml文件,并添加如下内容
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>3.3 启动Hive
3.3.1 初始化元数据库
(1)登陆MySQL
[[email protected] conf]$ mysql -uroot -p000000(2)新建Hive元数据库
mysql> create database metastore;(3)初始化Hive元数据库
[[email protected] conf]$ schematool -initSchema -dbType mysql -verbose3.3.2 启动Hive客户端
(1)启动Hive客户端
[[email protected] hive]$ bin/hive(2)查看一下数据库
hive (default)> show databases;
OK
database_name
default边栏推荐
- 《剑指Offer》刷题之打印从1到最大的n位数
- [Hello World] 二分查找笔记
- Detailed explanation of cause and effect diagram of test case design method
- 依赖注入(DI),自动配置,集合注入
- 分治法求解中位数
- 推荐系统-排序层-特征工程:用户特征、物品特征
- ArcEngine(二)加载地图文档
- 【云原生--Kubernetes】kubectl命令详解
- How does Mysql query two data tables for the same fields in two tables at the same time
- requests库
猜你喜欢
Roson的Qt之旅#105 QML Image引用大尺寸图片
![[Kaggle combat] Prediction of the number of survivors of the Titanic (from zero to submission to Kaggle to model saving and restoration)](/img/2b/d2f565d9221da094a9ccc30f506dc8.png)
[Kaggle combat] Prediction of the number of survivors of the Titanic (from zero to submission to Kaggle to model saving and restoration)
Detailed explanation of cause and effect diagram of test case design method
Postman will return to the interface to generate a json file to the local

学习Glide 常用场景的写法 +
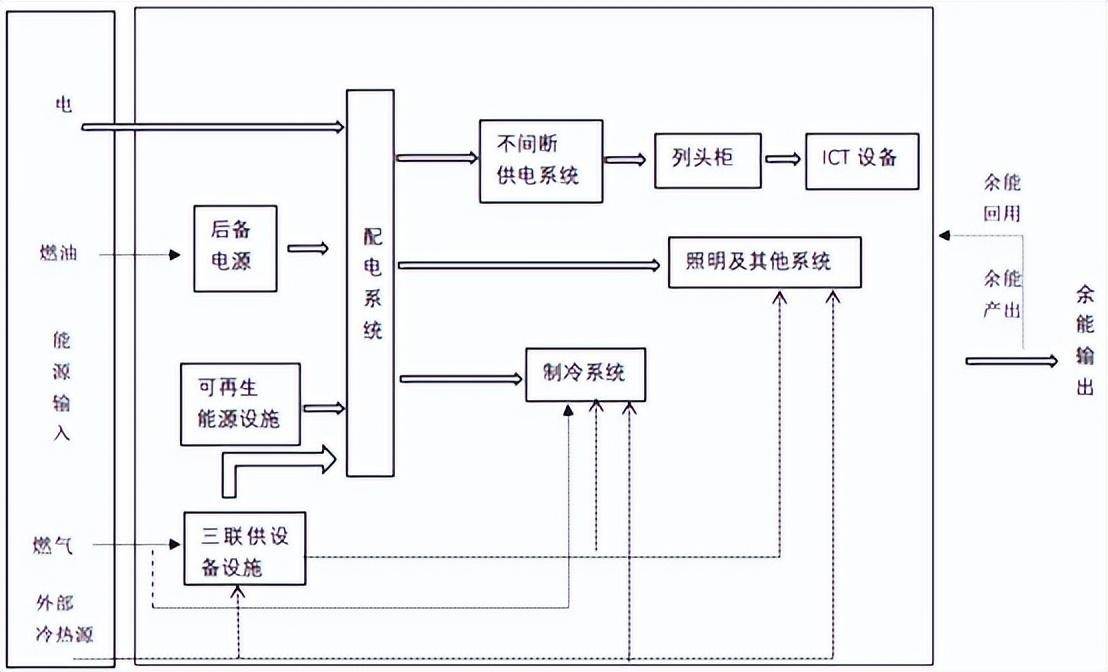
“碳中和”愿景下,什么样的数据中心才是我们需要的?
SSM整合流程
sqlite 日期字段加一天
pyspark df secondary sorting
【云原生--Kubernetes】kubectl命令详解
随机推荐
跨域嵌套传递信息(iframe)
Mysql如何对两张表的相同字段,同时查询两张数据表
STL迭代器
Karatsuba大数乘法的Verilog实现
Taro框架-微信小程序-调用微信支付
力扣(LeetCode)214. 打家劫舍 II(2022.08.02)
The use of the database table structure document generation tool screw
控制bean的加载
redis AOF持久化个人理解
使用pipreqs导出项目所需的requirements.txt(而非整个环境)
Qt5开发从入门到精通——第二篇(控件篇)
ArcEngine (4) Use of MapControl_OnMouseDown
【云原生--Kubernetes】kubectl命令详解
002-字段不为null
Dapr 与 NestJs ,实战编写一个 Pub & Sub 装饰器
[ 漏洞复现篇 ] yapi 代码执行 getshell 漏洞复现详解
Using pipreqs export requirements needed for the project. TXT (rather than the whole environment)
Haisi project summary
【图像去雾】基于matlab暗通道和非均值滤波图像去雾【含Matlab源码 2011期】
面试介绍项目经验(转)