当前位置:网站首页>MAML principle explanation and code implementation
MAML principle explanation and code implementation
2022-08-04 07:11:00 【hot-blooded chef】
Model-Agnostic Meta-Learning - MAML
一、相关概念:
1、meta-leaning
meta-leaningRefers to meta-learning,Meta-learning is a branch of deep learning,a good metamodel(meta-learner)should have the new、Fast and accurate learning with small amounts of data.通俗的来讲, 对于人来说,Let's take a look at some pictures of orange cats,Give you a few pictures of British Shorthair cats that you haven't seen before,You must be able to quickly recognize that it is a cat.但是对于神经网络来说,并非如此.If a small car classification network is used to identify different large trucks,That must be bad.而传统的CNNNetwork is input large amounts of data,Then learn to classify.但是这样做的问题就是,Neural networks are too general,根本达不到“智能”的标准.the human cognitive system,Rules can be learned from a small amount of data,The reason why humans can be so intelligent,because the human brain exists“先验知识”.
2、few-shot learning
few-shot learningTranslated as small sample learning,refers to learning a model from very few samples.
N-way K-shot
这是小样本学习中常用的数据,用以描述一个任务:它包含N个分类,每个分类只有K张图片.
Support set and Query set
Support set指的是参考集,Query setrefers to the test set.Identifying animal species with humans,有5种不同的动物,每种动物2张图片,这样10张图片给人做参考.另外给出5张动物图片,让人去判断各自属于那一种类.那么10张作为参考的图片就称为Support set,5A test image is calledQuery set.

二、什么是MAML?
1、要解决的问题
- 小样本问题
- Model convergence is too slow
common classification、检测任务中,因为分类、The class of the detected object is known,可以收集大量数据来训练.例如 VOC、COCO 等检测数据集,都有着上万张图片用于训练.And if we only have a few images for training,This poses a big obstacle to model prediction.
在深度学习中,解决训练数据不足常用的一个技巧是“预训练-微调”(Pretraining-finetune),即大数据集上面预训练模型,然后在小数据集上去微调权重.但是,在训练数据极其稀少的时候(仅有个位数的训练图片),这个技巧是无法奏效的.And this way sometimes makes the model fall into a local optimum.
2、MAML的关键点
The idea of this article is traininga set of initialization parameters,The model passes the initialization parameters,Fast convergence with only a small amount of data.为了达到这一目的,The model requires a lot of先验知识to constantly modify the initialization parameters,使其能够适应不同种类的数据.
3、MAML与Pretraining的区别
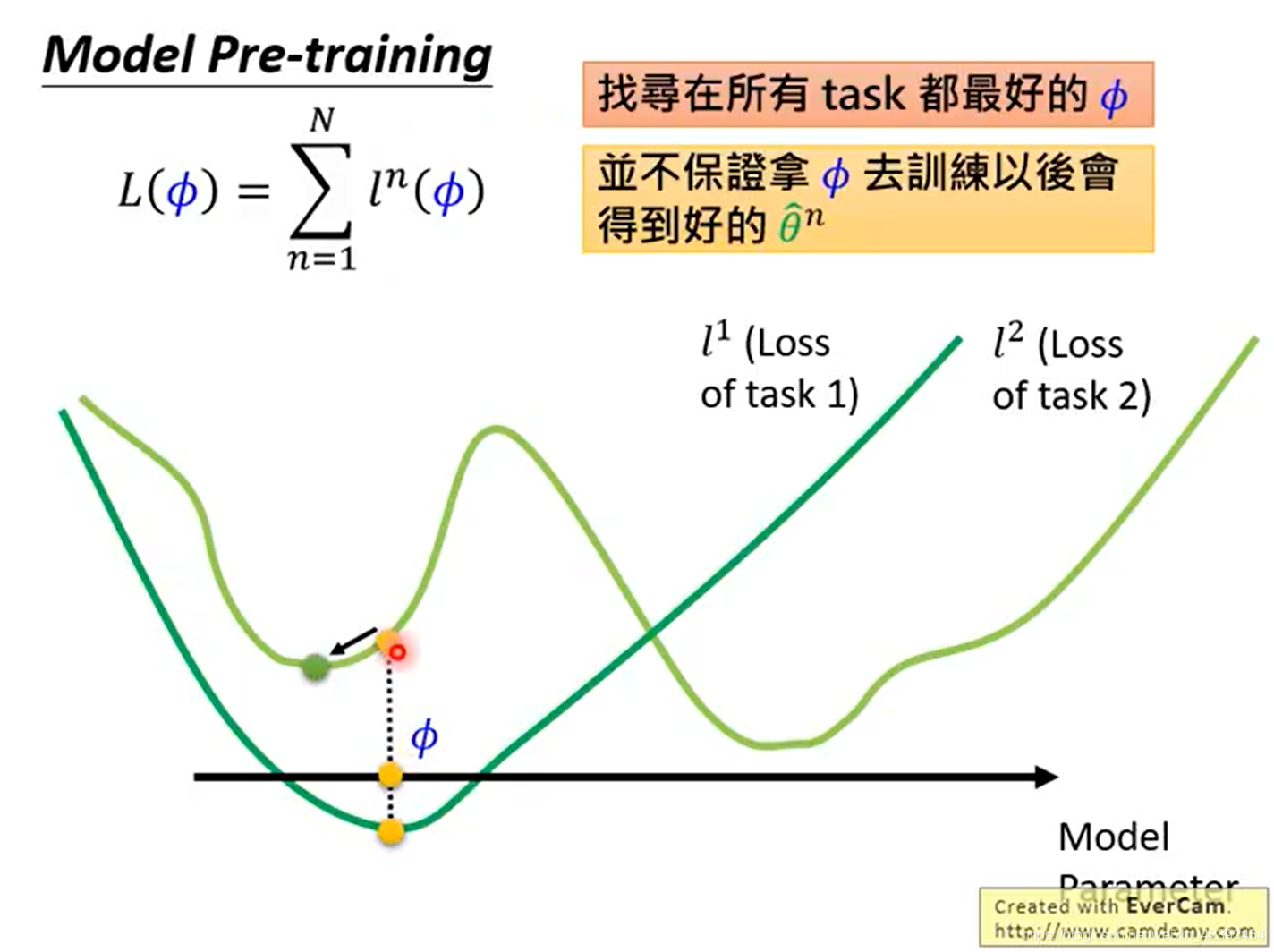
- Pretraining
Suppose there is a model fromtask1A set of weights are trained on the data,我们记为 θ 1 \theta1 θ1,这个 θ 1 \theta1 θ1is the dark green dot in the figure,可以看到,在task1下,He has reached the global optimum.And if our model uses θ 1 \theta1 θ1作为task2的初始值,We will eventually reach the light green point,And this point is justtask2the local optimum of.The question is simple,Because model in trainingtask1When data is not consideredtask2的数据.
- MAML
MAMLThen you need to consider the distribution of the two datasets at the same time,假设MAMLAfter training, we get a set of weights, which we record as θ 2 \theta2 θ2,Although the picture shows,This weight is for both tasks,did not reach the global optimum.但是很明显,经过训练以后,They can all converge to the global optimum.
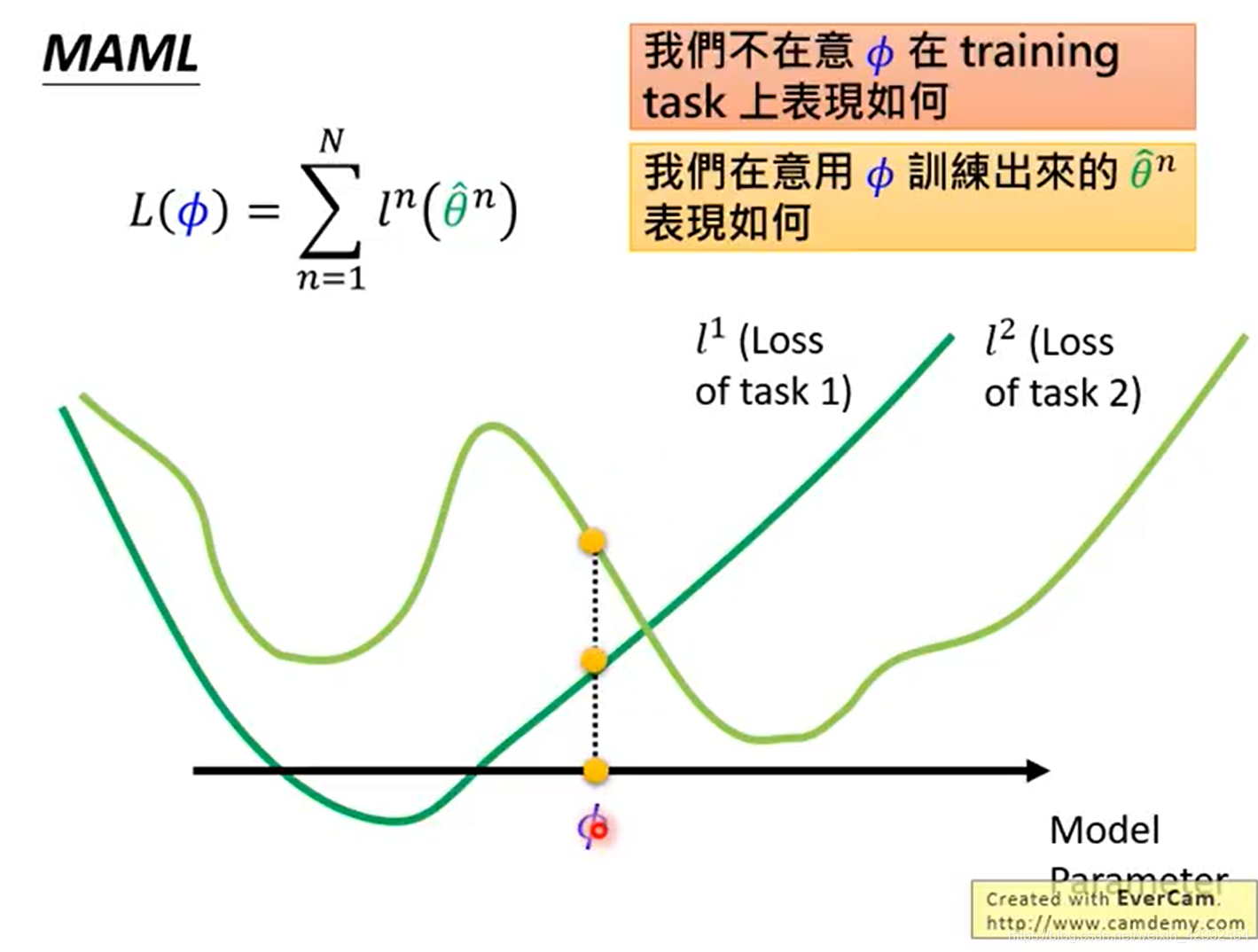
所以,PretrainingEach time the emphasis is当下Can this model be optimal?,而MAML强调的则是经过训练Will it be possible to achieve the best.
三、MAML的核心算法
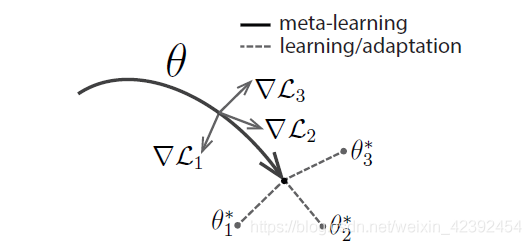
刚刚说了MAML关注的是,model uses a copy“very adaptable”权重,It works well for new tasks after a few gradient descents.Then the goal of our training becomes“how to find this weight”.而MAMLas one of the,It makes for a firstbatchis trained once for each task in,then go back to this original position,for these taskslossmake a comprehensive judgment,Choose another direction that suits all tasks.
The algorithm flow of the classification problem with supervised learning is as follows:

先决条件:
- task-based dataset
- 两个学习率 α 、 β \alpha 、\beta α、β
流程解析:
Step 1: Randomly initialize a weight
Step 2: 一个while循环,The corresponding is in trainingepochs(Step 3-10)
Step 3: 采样一个batch的task(假设为4个任务)
Step 4: for循环,用于遍历所有task(Step 5-8)
Step 5: 从support setOut of a batchtask图片和标签
Step 6-7: On this picture prior to transmission,After calculating the gradient, use l r α lr_\alpha lrα反向传播,更新 θ ′ \theta' θ′这个权重
Step 8: 从query set中取出所有task进行前向传播,But I don't update model
Step 10: 将所有用 θ ′ \theta' θ′Calculated loss summation,After calculating the gradient, use l r β lr_\beta lrβ进行梯度下降,更新 θ \theta θ的权重
相关代码如下:
def train_on_batch(self, train_data, inner_optimizer, inner_step, outer_optimizer=None):
"""
MAML一个batch的训练过程
:param train_data: 训练数据,以task为一个单位
:param inner_optimizer: support set对应的优化器
:param inner_step: Several internal updatesstep
:param outer_optimizer: query set对应的优化器,If the object does not exist, don't update the gradient
:return: batch query loss
"""
batch_acc = []
batch_loss = []
task_weights = []
# 用meta_weightsSave initial weights,并将其设置为inner step模型的权重
meta_weights = self.meta_model.get_weights()
meta_support_image, meta_support_label, meta_query_image, meta_query_label = next(train_data)
for support_image, support_label in zip(meta_support_image, meta_support_label):
# 每个taskneed to load the originalweights进行更新
self.meta_model.set_weights(meta_weights)
for _ in range(inner_step):
with tf.GradientTape() as tape:
logits = self.meta_model(support_image, training=True)
loss = losses.sparse_categorical_crossentropy(support_label, logits)
loss = tf.reduce_mean(loss)
acc = tf.cast(tf.argmax(logits, axis=-1, output_type=tf.int32) == support_label, tf.float32)
acc = tf.reduce_mean(acc)
grads = tape.gradient(loss, self.meta_model.trainable_variables)
inner_optimizer.apply_gradients(zip(grads, self.meta_model.trainable_variables))
# 每次经过inner loop更新过后的weightsneed to save once,保证这个weights后面outer looptrained the sametask
task_weights.append(self.meta_model.get_weights())
with tf.GradientTape() as tape:
for i, (query_image, query_label) in enumerate(zip(meta_query_image, meta_query_label)):
# load eachtask weights进行前向传播
self.meta_model.set_weights(task_weights[i])
logits = self.meta_model(query_image, training=True)
loss = losses.sparse_categorical_crossentropy(query_label, logits)
loss = tf.reduce_mean(loss)
batch_loss.append(loss)
acc = tf.cast(tf.argmax(logits, axis=-1) == query_label, tf.float32)
acc = tf.reduce_mean(acc)
batch_acc.append(acc)
mean_acc = tf.reduce_mean(batch_acc)
mean_loss = tf.reduce_mean(batch_loss)
# 无论是否更新,Both need to load the initial weights to update,防止valThe stage changed the original weight
self.meta_model.set_weights(meta_weights)
if outer_optimizer:
grads = tape.gradient(mean_loss, self.meta_model.trainable_variables)
outer_optimizer.apply_gradients(zip(grads, self.meta_model.trainable_variables))
return mean_loss, mean_acc
推荐阅读:PytochVersion code details
四、The author's source code
五、MAML存在的问题
MAMLThere are some problems are reported in itselfHow to train your MAML中.
边栏推荐
- curl (7) Failed connect to localhost8080; Connection refused
- QT 显示窗口到最前面(非置顶)
- 数据库技巧:整理SQLServer非常实用的脚本
- 如何在Excel 里倒序排列表格数据 || csv表格倒序排列数据
- 目标检测中的IoU、GIoU、DIoU与CIoU
- JVM工具之 JPS
- Hardware Knowledge: Introduction to RTMP and RTSP Traditional Streaming Protocols
- 用matlab打造的摩斯电码加解码器音频版,支持包括中文在内的任意字符
- 狗都能看懂的变化检测网络Siam-NestedUNet讲解——解决工业检测的痛点
- MySQL重置root密码
猜你喜欢
数据库文档生成工具V1.0
matlab科研绘图模板,直接奉上源代码!
A semi-supervised Laplace skyhawk optimization depth nuclear extreme learning machine for classification

什么是多态。
sql常用函数

Memory limit should be smaller than already set memoryswap limit, update the memoryswap at the same
如何用matlab做高精度计算?【第三辑】(完)

用手机也能轻松玩转MATLAB编程
CMDB 腾讯云部分实现
FCN——语义分割的开山鼻祖(基于tf-Kersa复现代码)
随机推荐
在线公众号文章内容转音频文件实用小工具
软件稳定性思考
缓动动画,有关窗口的一些常见操作,BOM操作
MySQL错误-this is incompatible with sql_mode=only_full_group_by完美解决方案
搭建redis哨兵
基于时序模式注意力机制(TPA)的长短时记忆(LSTM)网络TPA-LSTM的多变量输入风电功率预测
Hardware Knowledge: Introduction to RTMP and RTSP Traditional Streaming Protocols
数据库文档生成工具V1.0
网页中常用的两种绘图技术,用canvas绘图,绘制出一个三角形,矩形,柱状图,扇形图
自适应迁移学习核极限学习机用于预测
Operating System Random
花了近70美元入手的学生版MATLAB体验到底如何?
DenseNet详解及Keras复现代码
树莓派 4 B 拨动开关控制风扇 Rasberry Pi 4 B Add Toggle Switch for the Fan
Time Series Forecasting Based on Reptile Search RSA Optimized LSTM
网络端口大全
电脑知识:台式电脑应该选择品牌和组装,值得收藏
Detailed explanation of DenseNet and Keras reproduction code
零分贝超静音无线鼠标!数量有限!!先到先得!!!【元旦专享】
对产品设计,架构设计的一点思考