当前位置:网站首页>MySQL index and data storage structure foundation
MySQL index and data storage structure foundation
2022-06-30 09:35:00 【Tyndarus Hound】
MySql Based on the index and data storage structure
The essence of index
Indexes Help MySql Efficient access to data Arrange order well Of data structure
It can be seen from this sentence that , An index is essentially an ordered data structure , And can efficiently query . So what is the orderly structure , How to be efficient ?
Index data structure classification
- Binary tree
- Red and black trees
- Hash surface
- B-Tree
as everyone knows ,mysql It's using B+ Trees . This raises some questions .(1) What is? B-Tree,(2)B+Tree and B-Tree The difference between ,(3) Why use B+Tree, Instead of other .
B-Tree
Is a multi-channel self balancing search tree , It's like an ordinary binary tree , however B Trees allow each node to have more children .
characteristic :
- Leaf nodes have the same depth , The pointer of the leaf node is null
- All index elements are not duplicated
- Nodes in the The data index is arranged incrementally from left to right
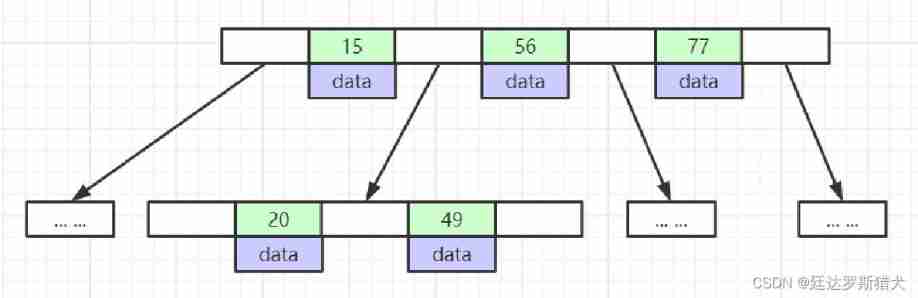
notes : Because the data is stored in the leaf node , Therefore, the index that can be stored on each page is variable , This is also mysql Not one of the reasons for using him .
Reason two : Leaf nodes are not connected to each other , It is not possible to search directly through the lowest leaf node .
B+Tree
She is B-Tree A variant of .
characteristic
- Non leaf nodes do not store data, Store index only ( redundancy ), Easy to store more indexes , At the same time, keep the size of node pages of non leaf nodes .
- The leaf node contains all index fields
- Leaf nodes are linked with pointers , Improve the performance of interval access .

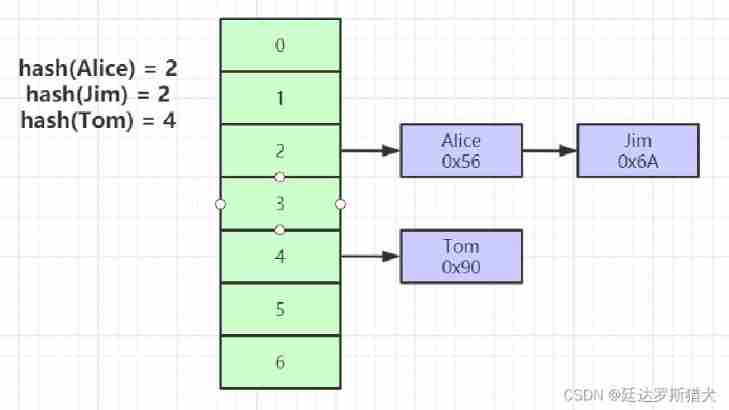
Hash
- Evaluation of index key Do it once. hash Calculation can locate the location of data storage
- A lot of times Hash Index is better than B+ Tree indexing is more efficient
- Can only satisfy “=”,“IN”, Range query is not supported
- hash The question of conflict
engine
MyISAM
MyISAM Index files and data files are separate ( Non aggregation )
InnoDB
innoDB The index to achieve ( Gather )
- Table data file itself is by pressing B+Tree An index structure file of an organization
- Clustered index - Leaf nodes contain complete data records
- Why suggest InnoDB A table must have a primary key , And it is recommended to use the auto increasing primary key of integer type ?
- Why do leaf nodes of non primary key index structure store primary key values ( Consistency and storage savings )


Why suggest InnoDB A table must have a primary key , And it is recommended to use the auto increasing primary key of integer type ?
1、 If the primary key is set , that InnoDB Will choose the primary key as the clustered index 、 If the primary key is not explicitly defined , be InnoDB Will choose the first one that does not contain NULL The unique index of the value is the primary key index 、 If there is no such unique index , be InnoDB Will choose built-in 6 Byte long ROWID As an implicit clustered index (ROWID The primary key is incremented as the row record is written ).
2、 If the table uses an auto increment primary key
So every time you insert a new record , Records are added to the subsequent locations of the current inode in order , The order of primary keys is arranged according to the insertion order of data records , Automatic ordering . When a page is full , Will automatically open a new page
3、 If a non auto increment primary key is used ( If Id number or student number, etc )
Because the value of each primary key inserted is approximately random , So every time a new record is inserted in the middle of an existing index page , here MySQL Data has to be moved in order to plug new records into place , Even the target page may have been written back to disk and purged from the cache , Now I want to read it back from the disk , This adds a lot of overhead , At the same time, frequent movement 、 Paging causes a lot of fragmentation , The index structure is not compact enough , I have to go through OPTIMIZE TABLE To rebuild the table and optimize the page population .
Why does the leaf node of non primary key index structure store the primary key value ?
It reduces the maintenance of secondary index in case of row movement or data page splitting ( When data needs to be updated , The secondary index does not need to be modified , Just modify the cluster index , A table can only have one clustered index , The others are secondary indexes , In this way, you only need to modify the cluster index , There is no need to rebuild the secondary index )
A clustered index is also called a primary key index , The leaf node of its index tree stores the whole row of data , The physical order of the rows in the table and the logic of the key values ( Indexes ) Same order . A table can only contain one clustered index . Because index ( Catalog ) You can only sort in one way .
Nonclustered index ( General index ) The content of the leaf node is the value of the primary key . stay InnoDB in , Non primary key indexes are also called secondary indexes (secondary index)
Quote from :https://blog.csdn.net/weixin_41699562/article/details/104139458
Federated index underlying storage structure

Why? mysql Page file default 16K?
Let's say the data size of a row is 1K, So one page can be saved 16 Data , That is, a leaf node can store 16 Data ; Look at the non leaf nodes , Suppose the primary key ID by bigint type , So the length is 8B, The size of the pointer is Innodb Source code for 6B, All together 14B, So one page can store 16K/14=1170 individual ( Primary key + The pointer )
So the height of one is 2 Of B+ The data that the tree can store is :117016=18720 strip , A height of 3 Of B+ The data that the tree can store is :11701170*16=21902400( Tens of millions )
边栏推荐
- Simple redis lock
- Using appbarlayout to realize secondary ceiling function
- Why won't gold depreciate???
- Linear-gradient()
- Tablet PC based ink handwriting recognition input method
- Design of mfc+mysql document data management system based on VS2010
- Idea setting automatic package Guide
- Small program learning path 1 - getting to know small programs
- Flutter 0001, environment configuration
- Talk about how the kotlin collaboration process establishes structured concurrency
猜你喜欢

MySQL优化

Small program learning path 1 - getting to know small programs

Talking about kotlin process exception handling mechanism

Baidu map JS browsing terminal

Framework program of browser self-service terminal based on IE kernel

9.JNI_ Necessary optimization design

So the toolbar can still be used like this? The toolbar uses the most complete parsing. Netizen: finally, you don't have to always customize the title bar!

Flutter 0001, environment configuration

Pit encountered by fastjason

Express の post request
随机推荐
DataTableToModelList实体类
MySQL优化
Talk about the job experience of kotlin cooperation process
2020-11-02
Pytorch for former Torch users - Tensors
【新书推荐】MongoDB Performance Tuning
About MySQL Boolean and tinyint (1)
Initialize static resource demo
MySQL directory
Niuke rearrangement rule taking method
Distributed things
Startup of MySQL green edition in Windows system
7. know JNI and NDK
QR code generation and analysis
[shutter] solve failed assertion: line 5142 POS 12: '_ debugLocked‘: is not true.
机器学习笔记 九:预测模型优化(防止欠拟合和过拟合问题发生)
MySQL index optimization miscellaneous
Tclistener server and tcpclient client use -- socket listening server and socketclient use
Why must redis exist in distributed systems?
桂林 稳健医疗收购桂林乳胶100%股权 填补乳胶产品线空白