当前位置:网站首页>Thesis reading_ Chinese medical model_ eHealth
Thesis reading_ Chinese medical model_ eHealth
2022-07-03 04:43:00 【xieyan0811】
English title :Building Chinese Biomedical Language Models via Multi-Level Text Discrimination
Chinese title : Build a Chinese biomedical language model based on multi-level text discrimination
Address of thesis :https://arxiv.org/pdf/2110.07244.pdf
field : natural language processing , biomedical science
Time of publication :2021
author :Quan Wang etc. , Baidu
Model download :https://huggingface.co/nghuyong/ernie-health-zh
Model is introduced :https://github.com/PaddlePaddle/Research/tree/master/KG/eHealth
The model code :https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-health
Reading time :22.06.25
Journal entry
The best biomedical pre training model at present , stay CBLUE The pro test data has really improved significantly .
Introduce
Previously, the pre training model in biomedical field only used special data training , And most of them are English models , Vertical domain models are often trained on the basis of general models , There are also some experiments to prove , It is better to train directly with domain data .
PCL-MedBERT and MC-BERT It is a Chinese medical domain model , However, the effect of its use in medical and general fields is not very obvious ; SMedBERT and EMBERT Use domain knowledge to improve the effect of the model , But it introduces external knowledge , The knowledge map used has not been made public ( translator's note :SMedBERT Provide model download ).
This paper puts forward eHealth Chinese language representation model , It is pre trained based on a large amount of biomedical data , And modified the model framework . It's based on eHealth Model , It includes two parts: generation and discrimination . And in ELECTRA The discrimination model is subdivided into token Level and sequence level .eHealth Do not rely on external resources , therefore , Fine tuning model is also more convenient .
It's in CBLUE Of 11 Xiang medicine NLP The effect in the task is better than the previous pre training model , Use only normal model size ( Not a big model ), It has achieved good results in the fields of medicine and general use , Even more than the big model .
The main contributions are as follows :
- A Chinese medical pre training model is established , it Rely only on the text itself , Convenient for fine adjustment .
- Put forward a new method of pre training , It can be Migrate to other fields outside medicine .
Method
The confrontation model includes two parts: general generator and discriminator , Its main principle is : The generator tries to generate more realistic data , The discriminator tries to distinguish the generated false text , Improve quickly through confrontation .

generator
The generator in this article G It's a Transforer Encoder , Use MLM Way training , For input text x=[x1,…,xn], Mask some of the words , Generate xM, It is then fed into the encoder to generate a hidden layer representation hG(xM), Then send the hidden representation into a softmax To predict each token Is "of" the word behind the cover :

In total xt It means the t Positional token,hg(xM) Is the combination of context after t The representation of position ,e It's word embedding ,V It's all about token The vocabulary of . The loss function is calculated as follows :
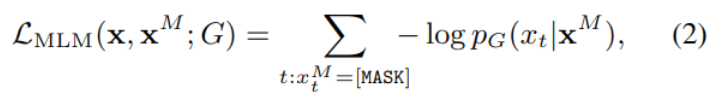
Here we only focus on what is really covered token, The goal of the loss function is to generate the most falsified text . The data generated by the generator is sent to the discriminator for processing .
Judging device
Judging device D It is also the final encoder , Also used Transformer structure , Its input is a string tampered with by the generation model , Train the two-layer discriminator .
Token Level discrimination
Token There are two kinds of level discriminators , One is token Replace RTD, The other is token choice MTS.RTD Is in ELECTRA Proposed in , It is used for Identify the tampered in the sentence token,MTS yes 2020 year Xu And so on , Its goal is to choose from the given options what the original text should be at the tampered place .
RTD
Set the generated tampered text as xR,RTD Used to identify each of them token Has it been tampered with . The hidden layer generated by the model hD(xR) Substitute into the second category sigmoid layer , Output each position t Of token The probability of being tampered :
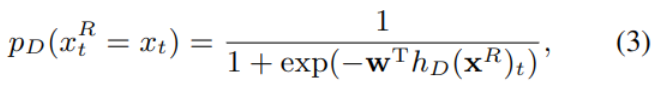
The corresponding loss function is as follows , It adds the result of each position .

MTS
MTS Can be used as a pair RTD Strengthening of , Further identify what the original text of the tampered position should be , Choose the most likely position from the candidates token.
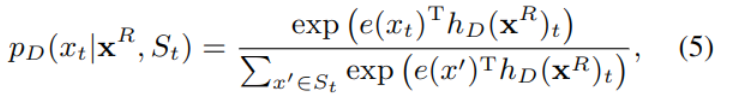
The corresponding loss function is as follows :
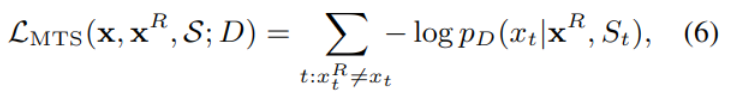
Optional set S For all tampered positions , The generated ones can be confused with the real ones k individual token As a candidate ,MTS In essence , It's a k+1 The classifier of the class .
Sequence Level discrimination
in addition , Also for sequences , Designed a comparison sequence prediction CSP (2020 year Chen Put forward ), For each original input , Two versions of tampering results are established . Pictured -1 in The left and right parts are shown , Use them separately XRi and XRj Express , Take them as a positive example ; Choose the same training minibatch As a counterexample , The candidate set is composed of positive examples and negative examples N(x).CSP The goal of the mission is to know XRi Under the condition of , From the candidate N(x) Choose the right XRj.

among s() Used to measure similarity , τ It's a super parameter. .
model training
The final objective function synthesizes the above losses ,λ It's a super parameter. :

experiment
The experiment includes pre training and fine tuning for each task .
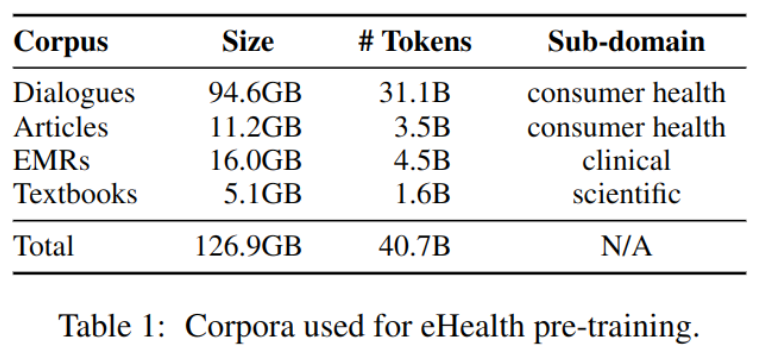
data
Use four Chinese datasets to pre train the model , contain :
- 100 million Unmarked doctor-patient conversation
- 6.5 million Hot articles in the medical field
- 6.5 million Electronic medical records
- 1500 This textbook includes medicine and clinical pathology
As shown in the table -1 Shown :
Domain vocabulary
Previous experiments have proved , The model trained with domain vocabulary from the beginning is better , In this experiment, a domain vocabulary is established : Use Tensor2Tensor library3 Create... In biomedical field WordPiece glossary , Discard occurs less than 5 Time of token, And keep your vocabulary at 20K about , And common domain Chinese BERT be similar .
As shown in the table -2 Shown , The effect of Neologisms on Chinese is not obvious , But it can better recognize English abbreviations .

The main experimental results

边栏推荐
- Number of 1 in binary (simple difficulty)
- I've been in software testing for 8 years and worked as a test leader for 3 years. I can also be a programmer if I'm not a professional
- Basic use of continuous integration server Jenkins
- The reason why the entity class in the database is changed into hump naming
- Review the old and know the new: Notes on Data Science
- Market status and development prospect prediction of the global forward fluorescent microscope industry in 2022
- 联发科技2023届提前批IC笔试(题目)
- [PHP vulnerability weak type] basic knowledge, PHP weak equality, error reporting and bypassing
- Apache MPM model and ab stress test
- String matching: find a substring in a string
猜你喜欢

论文阅读_清华ERNIE
Human resource management system based on JSP

Number of 1 in binary (simple difficulty)

Introduction to message queuing (MQ)

Joint search set: the number of points in connected blocks (the number of points in a set)

Symbol of array element product of leetcode simple problem

Jincang KFS data bidirectional synchronization scenario deployment
MPM model and ab pressure test

Employee attendance management system based on SSM
UiPath实战(08) - 选取器(Selector)
随机推荐
2022 tea master (intermediate) examination questions and tea master (intermediate) examination skills
Smart contract security audit company selection analysis and audit report resources download - domestic article
[SQL injection point] location and judgment of the injection point
Review the old and know the new: Notes on Data Science
并发操作-内存交互操作
Kingbasees plug-in KDB of Jincang database_ database_ link
Dive into deep learning - 2.1 data operation & Exercise
Learning practice: comprehensive application of cycle and branch structure (I)
Introduction to message queuing (MQ)
Human resource management system based on JSP
stm32逆向入门
Arthas watch grabs a field / attribute of the input parameter
[XSS bypass - protection strategy] understand the protection strategy and better bypass
普通本科大学生活避坑指南
2022-02-13 (347. Top k high frequency elements)
"Niuke brush Verilog" part II Verilog advanced challenge
Kingbasees plug-in KDB of Jincang database_ date_ function
《牛客刷verilog》Part II Verilog进阶挑战
[luatos sensor] 1 light sensing bh1750
论文阅读_ICD编码_MSMN