Continuous updating ......
Generalization : In the past, many papers have used in-depth information to make 2D Rise to 3D, The purpose of this paper is to replace depth data with network training ( The cost of equipment is relatively high ), Improve his universality , As long as the composite data set is large enough and the network is strong enough , So I don't need deep information . The idea of this paper is very clear , It is divided into three parts :
1、HandSegNet
2、PoseNet
3、the PosePrior network
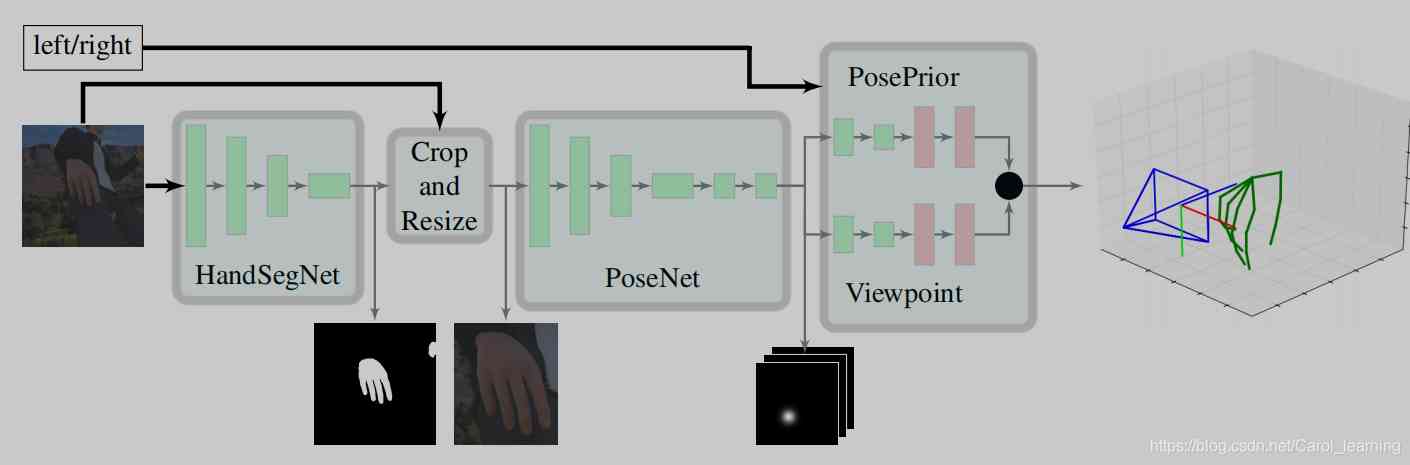
The first 1、2 The network mainly relies on Convolutional Pose Machines The network of this paper is set up , Through convolution layer to express texture information and spatial information to extract the position of the hand ( It's just adding binarization to the first network to form handmask The intermediate output of ), Because the gestures are small , So the opponent's position is tailored to become the input of the second network , Extract the position of the joint in a similar way (score map).
The core of this paper is the third network , The network uses score map As input , The regularization framework is estimated by training the network WC Three dimensional coordinates inside , And estimate the rotation matrix respectively R(Wrel), According to the formula, we can get wc (rel).
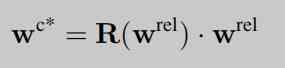
Why? 2D Data can be carried out directly through the network 3D Estimation ?
The key is that the method uses a composite dataset (synthetic dataset (R-val) ), What is a composite dataset ?Unity You must be familiar with it . Through something like Unity We can simulate all kinds of scenarios 、 People in the light , According to their own needs to produce a large number of data sets , To solve the shortage of data sets in computer vision field . however , This is just one of the benefits of composite datasets , The biggest advantage is that we use the engine to simulate people , So we have the data of this character , That is, we can know the relative position and absolute position of each joint of the three-dimensional gesture (ground truth), So we can train with these data , In order to achieve no depth data can 3D The effect of training .
Why use one canonical frame Well ?
This is the definition in the paper :
Given a color image I∈RN×M3 Show a hand , We want to infer its three-dimensional posture . We use a set of coordinates wi=(xi,yi,zi) To define hand posture , It describes the J The location of the key points in three-dimensional space , In our case , use J=21 Come on ∈[1,J].
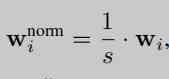
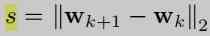
s Normalize the distance between a pair of key points into unit length .
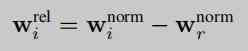
Depth data limits the way we can break away from the entire image , If you don't use depth data , We just need to look at one hand , To establish an object by hand to study its properties . In the paper , The authors normalized the distance between joints , And the key point of the palm joint is used as a sign (land mark), Calculate the distance from other joints to the joint point of the palm , So as to form a canonical frame. The third layer of network is to keep canonical frame The measured value and ground truth use L2 Loss on two estimates WC The three-dimensional coordinates and rotation matrix within R(Wrel) Training .
Why use the rotation matrix to unify the perspective ?
My understanding is that if the perspective is unified , Then all possible forms of gesture will be greatly reduced , In this way, the sub network training accuracy will be improved .
The paper studies knowledge supplement ( And then moved to other places )
ill-posed problems
Definition : A well posed problem is called a well posed problem (well-posed problem):1. a solution exists The solution must exist 2. the solution is unique The solution must be unique 3. the solution's behavior changes continuously with the initial conditions. The solution can change continuously according to the initial conditions , It doesn't jump , That is, the solution must be stable
understand : The pathological problem is simply that the result is not unique , such as a*b=5, solve a and b The value of is a sick problem . In practice, many problems are pathological problems , For example, if a hot thing , You can't measure him directly , You can only measure him indirectly , Indirect can form a model equation y=f(x,h...), So we get the measurements y, solve x, It can be seen that due to indirect measurement, we will be affected by other factors that cannot be measured , Reverse the search x There are multiple solutions , This is called a sick problem, so for a sick problem , We need to make all kinds of priori assumptions to constrain him , Let him become well-posed problem.
Regularization and over fitting
Extract and arrange
The basic definition : For a lot of training data , If we just minimize the error , Then the complexity of the model will increase ( imagine maltab The expression is very long ), This will make the model less generalized , So we define regular functions , Let him not over fit , Keep the model simple ( The model error is small ).
There is another understanding : Regular function is to take the experience of predecessors to make you less detours .
There is a third understanding : Regularization is in line with the Occam razor principle , From the perspective of Bayesian estimation , The prior of the regularized model . There is also a folk saying that , Regularization is the implementation of structural risk minimization strategy , Is to add a regularization term to the empirical risk (regularizer) Or penalty item (penalty term).
For minimizing the objective function :
Obj(Θ)=L(Θ)+Ω(Θ)
The common loss function : Loss function link
The loss on the training set is defined as :L=∑ni=1l(yi,y^i)
1.0-1 Loss function (0-1 loss function): L(Y,f(X))={1,Y≠f(X)0,Y=f(X)
2. Square loss function (quadratic loss function) : L(Y,f(X))=(Y−f(x))2
3. Absolute loss function (absolute loss function) : L(Y,f(x))=|Y−f(X)|
4. Logarithmic loss function (logarithmic loss function) : L(Y,P(Y∣X))=−logP(Y∣X)
5.Logistic Loss :l(yi,yi)=yiln(1+eyi)+(1−yi)ln(1+eyi)
6.Hinge Loss :hinge(xi)=max(0,1−yi(w⊤xi+b)) ,SVM Loss function , If the points are correctly classified and outside the interval , Then the loss is 0; If the points are correctly classified and within the interval , The loss is in (0,1); If you click the wrong classification , The loss is in (1,+∞)
7. Negative logarithmic loss (negative log-likelihood, NLL):Li=−log(pyi), The degree of disappointment with a certain kind of correct prediction (>0), The less it's worth , It shows that the probability of correct prediction is greater , Represents the predicted output and y The smaller the gap
8. Cross entropy loss (cross entropy): First of all softmax Defined as pk=efk/∑jefj, among fk=Wx+b Represents the predicted output value of a class , Then the cross entropy loss of a class is the output exponential value of the class divided by the sum of all classes . Based on cross entropy and softmax The normalized loss
L=−1N∑i=1Nyi log ef(xi)∑ef(xi)
condition number
excerpts
If a system is ill-conditioned Morbid , We will have doubts about its results . How much do you have to believe in it ? We have to find a standard to measure , Because some systems are less sick , Its results are still believable , You can't do it all at once . Finally back , above condition number Just to measure ill-condition The credibility of the system .condition number It measures when there is a small change in input , How much will the output change . That is, the sensitivity of the system to small changes .condition number What's worth less is well-conditioned Of , The big one is ill-conditioned Of .
low-rank
Extract and arrange
X It's a low rank matrix . Each row or column of a low rank matrix can be expressed linearly with other rows or columns , It can be seen that it contains a lot of redundant information . Take advantage of this redundant information , Missing data can be recovered , You can also extract features from the data .
L1 yes L0 The convex approximation of . because rank() It's not convex , It's hard to solve in optimization problems , Then we need to find its convex approximation to approximate it . Yes , You didn't guess wrong. ,rank(w) The convex approximation of is the kernel norm ||W||*.
L0 and L1 The relationship between
L1 We can make the matrix sparse , You can extract features
L2 Can prevent over fitting , Make irrelevant parameters smaller .
Convex optimization problem
Why can't you use MSE As the loss function of training binary classification ?
Because with MSE As the loss function of binary classification, there will be the problem of gradient vanishing .
one hot code
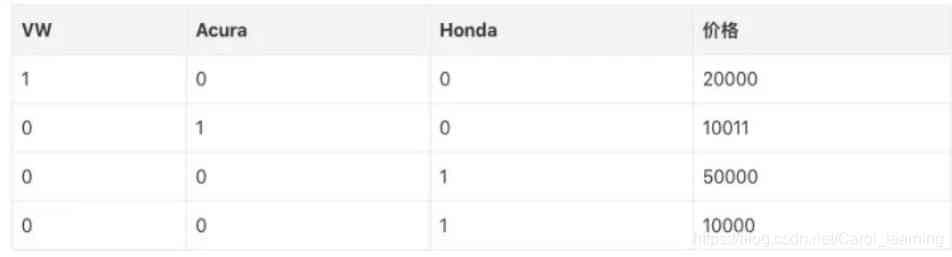
excerpts
Before we go on , You can think about why it's enough not to provide tag code directly to model training ? Why one hot code ?
The problem with tag encoding is that it assumes that the higher the category value , This category is better .“ wait , what !”
Let me explain : According to the category value encoded by the tag , Our mini dataset VW > Acura > Honda. For example , Suppose the average is calculated within the model ( There are a lot of weighted average operations in neural networks ), that 1 + 3 = 4,4 / 2 = 2. It means :VW and Honda On average Acura. without doubt , It's a bad plan . The prediction of this model will have a lot of errors .
We use one hot The coder performs... On categories “ Binary, ” operation , And then use it as a feature of model training , That's why .
Of course , If we take this into account when we design networks , Special handling of category values for tag encoding , No problem . however , in the majority of cases , Use one hot Coding is a simpler and more direct solution .
OpenCV Stereo correction of binocular vision
Stereo correction is , Two images with non coplanar lines aligned in practice , Correct to coplanar alignment . Because ideally, calculating the distance requires two cameras to be at the same level , But in real life, sometimes we don't take pictures with multiple perspectives on the same level , So stereo correction is needed to make the image look like two cameras at the same level .
Binocular stereo vision data set Stereo dataset
xx Yes , Each pair can be ranging after stereo correction .
A priori feature of an image
Intuitive understanding is what you know about images , For example, hand size in gesture estimation, other known information .
These priors are in many images task Can be used as loss The regularization term in , To force the processed image not to over fit .
Gradient explosion and gradient disappearance
@ see 【25】 The paper The difference from depth data
Then update
@@ How to use STB To train ?
And then go back to it , At present, it is considered that the depth data is input into the network for training after stereo correction .