当前位置:网站首页>MySQL的索引事务&&JDBC编程
MySQL的索引事务&&JDBC编程
2022-07-23 06:19:00 【Master_hl】
目录
- 索引
- 事务
- JDBC编程
1.索引
1.1 何为索引?
索引其实就对应生活中的目录,目录!存在的意义就是加快查找的速度。
索引本质上是通过一些更复杂的数据结构,把所有待查询的记录给组织起来了,从而就能够加快查询的速度!!
1.2 索引的应用场景
美中不足:
1.消耗额外的空间!!(目录总得占用书的纸张吧)
2.虽然有了索引,加快了查询速度,但是拖慢了增删改的速度!!(增删改,我们书的目录是不是都得变化,非常麻烦)
适合的场景:
1.对于空间不紧张,对于时间更敏感(空间换时间)
2.查询频繁,增删改不频繁 -- 少写多读的场景
(其实大多数情况都是符合第二点的,例如学校发电子版的作业给学生做,大部分都是往年师兄师姐做过的,除非题目有问题,跟老师反应,才会涉及到增删改)
1.3 索引的一些操作
- 查看索引
show index from 表名;
show indexe from student;- 创建索引
create index 索引名 on 表名(列名);
create idnex id_index on student(id);- 删除索引
drop index 索引名 on 表名;
drop index id_index on student;注意:
1.当我们没有给表手动创建索引时,表的主键,unique,以及外键约束的列,都会自动带上一个索引。
2.像主键这种,为了保证记录不重复,每次插入新纪录,都需要查询一下旧纪录,看新纪录是否已经存在!判定是否重复!
3.创建索引和删除索引和增删查改一样,也是危险操作!!尤其时是针对一个已经包含很大数据量的表进行操作的时候,创建索引,就会导致大规模磁盘IO,直接把主机的磁盘IO吃满!!,主机可能就卡了,无法对线上服务进行响应......
1.4 索引的数据结构
我们回顾前面学过的数据结构,用来查找的数据结构最可观的只有二叉搜索树O(N)和哈希表O(1)
二叉搜索树:高度可能比较高,数据库高度每增加一层,就要多出磁盘IO操作!!显然不适合索引。
哈希表:查找是块,但是不能支持范围查找和模糊匹配,固然也不适合索引。
既然二叉搜索树和哈希表都不适合索引的数据结构,聪明的程序员就发明了N叉搜索树,就是B树,它和二叉搜索树类似,只不过就是结点的度多了。

像这样的树,整体的高度,就大大缩短了!!l(logn^N < log2^N)
虽然这个B树相比于二叉搜索树,哈希表是好多了但是在实现数据库的时候,一般也不会直接使用B树,而是使用B树的改进版本,B+树!
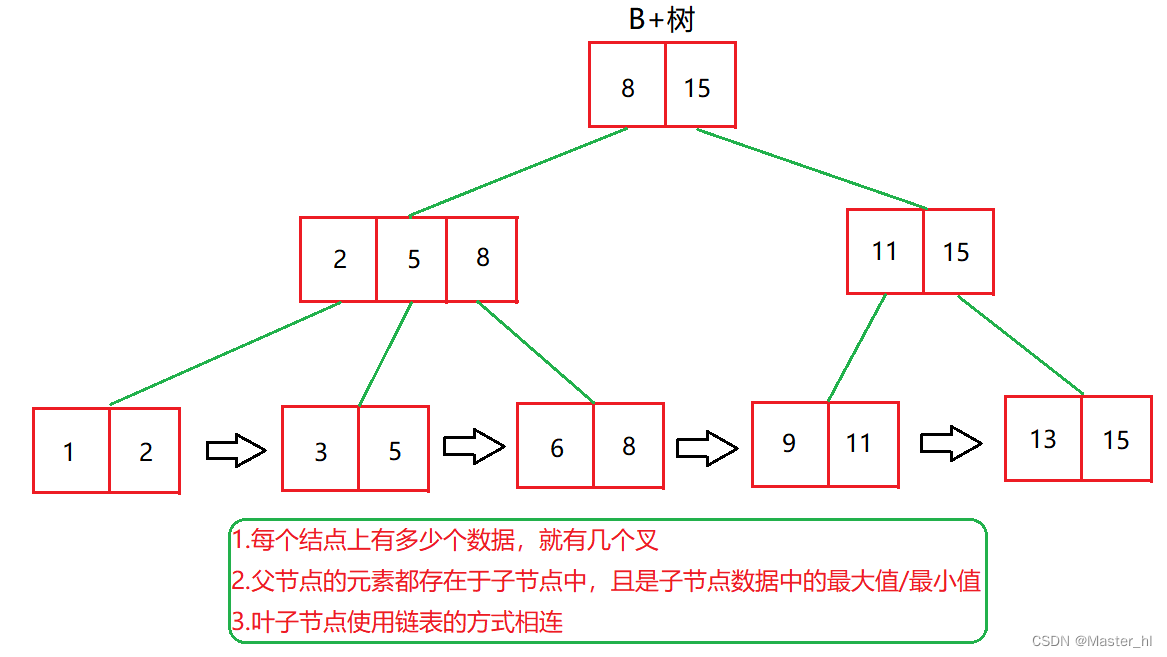
B+树可以说是为了实现数据库索引,量身定做的数据结构!
特点:
- 查询速度快,类似于二叉搜索树!
- 单个结点存储更多的数据,树的高度比较低,比较的次数相对少!
- 叶子节点包含了整个数据库的数据全集!
- 所有的叶子节点,使用链表首尾相连,非常便于范围查找!(例如我要找 id > 9 的,搜索树的方式定位到9,然后遍历 9 之后的所有数据)
- 每一个数据行,只需要保存在叶子节点上就够了,非叶子结点不必存储真实的数据行,只要存储用来做索引的 id 即可!!此时非叶子结点占用的空间小,就有了在内存中缓存非叶子结点的可能性,大大降低了磁盘IO!!
【面试问题】
谈谈对于数据库索引的理解?(高频问题)
【三个方面】
1.理解数据库的索引为啥使用B+树,而不是二叉搜索树 / 哈希表
2.理解 B+ 树的结构特点
3.理解 B+ 树的优势
2.事务
2.1 何为事务?
事务就是把一件事情的多个步骤,多个操作,打包成一个步骤,一个操作。其中任意一个步骤执行失败,都会进行回退,使影响降到最低!
2.2 事务的特性
2.2.1.原子性(最核心的特性)
一切事务要么全部执行完,要么一个都不执行。此处的"一个都不执行"并不是真的不执行,而是通过恢复的方式,,把之前操作造成的影响给还原了,我们把这个过程叫做"回滚"rollback。例如我们生活中转账,张三给李四转了500,在程序执行的过程出现了问题,导致张三的钱包已经少了500而李四的钱包并没有增加500,这就会造成纠纷,所以需要回滚来解决这种情况!
2.2.2.一致性
数据一定是对的,没有纰漏,不能出现张三给李四转账500,张三 -500 ,李四 +300这样的情况。
2.2.3.持久性
事务进行的操作都会存储在磁盘上,只要事务执行成功,就是持久化的保存了,哪怕重启主机这样的改变,也任然存在!
2.2.4.隔离性(重点)
描述多个事务并发执行的时候,所产生的影响。
【什么是并发执行?】
并发,简单粗暴理解成,两个事务在同时执行!就像一个数据库可以给多个客户端提供服务,这个时候就可能会涉及到多个客户端同时尝试操作同一个表,就可能产生这种并发事务的情况。
为啥要并发执行?目的是为了提高执行效率!!
为啥要有隔离性?使事务之间互不干扰,数据更精准都,但是效率低了!!
为了解决并发执行事务带来的问题,MySQL等数据库引入了"隔离级别",可以让用户自行选择一个适合自己当前业务场景的级别!!
先研究一下,并发执行事务的时候都还会有哪些问题??
【脏读问题】
一个事务A,在执行的过程中,对数据进行了一系列修改,在提交到数据库之前(完成事务之前),另一个事务B,读取了对应的数据,此时这个B读到的数据都是一些临时的结果,后续可能马上就被A给改了,此时B的读取行为就是"脏读"!
如何解决??
给读操作加锁,等到A事务提交事务后再进行读操作。
-- 隔离性最低,并发能力最强
【不可重复度】
事务A提交了事务之后,事务B才开始读(读的时候加了锁),然后B在执行的过程中,A又开启了一次,修改了数据,此时B执行中,就导致两次读取操作结果可能就不一致!
如何解决??
在A提交事务之前,给B的读加锁。A提交事务之后,B在读的时候,规定A不能修改B正在读的数据。
-- 隔离性提高了,并发性降低了
【幻读】
事务B读取过程中,事务A进行了修改,没有直接修改B读取的数据,但是影响到了B读取的结果集,事务B两次读取到的结果集不一样,这个就是幻读!幻读相当于不可重复的特殊情况。
如何解决??
B事务在读的时候,严格规定A不能修改,保证读和写操作都是严格串行化执行的。(一个执行完,才能执行另一个)
-- 隔离性最高,并发程度最低;数据的准确性最好,同时速度最慢!
对于这四种情况,MySQL里给我们提供了四个隔离级别,供我们自由选择,我们可以根据实际需求,在配置文件中,修改数据库的隔离级别。
【重点】
1.read uncommitted 并发能力最强,隔离性最弱。
2.read committed 只能读取提交之后的数据,解决了脏读问题,并发能力下降一些,隔离性增加了一些。
3.repeatable read 针对读和写都进行了限制,解决了不可重复读问题。并发能力又进一步下降,隔离性进一步增加。
4.serializable 严格的串行执行,解决了幻读问题,并发能力最低,隔离性最高。
3.JDBC编程
在idea上编写代码时,我们要做一些准备工作:
1.打开MySQL服务;2.建立一个 directory 目录,然后将我们的连接器导入,并add一下;
先演示一下插入操作:
Insert--插入
public static void main(String[] args) throws SQLException {
// 1.使用 DataSource 描述 MySQL 服务器的位置
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource)dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/xyz?characterEncoding=utf8&useSSL=false");
//Url--网址 jdbc:mysql://协议名 ,127.0.0.1 ip地址 ,3306 端口号 ,xyz 数据库,useSSL=false 是否启用加密
// characterEncoding=utf8 设置客户端连接服务器使用的字符集
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("123456");
//2.和数据库服务器建立连接
Connection connection = dataSource.getConnection();
//输入
Scanner scanner = new Scanner(System.in);
System.out.println("请输入你要插入信息的id: ");
int id = scanner.nextInt();
System.out.println("请输入你要插入信息的name: ");
String name = scanner.next();
String sql = "insert into student values(?,?)";
// 3.构造 SQL 语句,JDBC 操作数据,本质仍然是通过 SQL 来描述数据库操作
PreparedStatement statement = connection.prepareStatement(sql);
statement.setInt(1,id);
statement.setString(1,name);
// 4.执行SQL语句,insert,update,delete 都是通过 executeUpdate() 来执行的
int count = statement.executeUpdate();
System.out.println("成功向student表中插入了"+count+"条记录!");
//关闭,释放资源(先打开,后关闭;后打开,先关闭)
statement.close();
connection.close();
}【注意事项】
1.我们注意到第一步使用 DataSource 描述 MySQL 服务器位置的时候,先向下转型,再向下转型:
((MysqlDataSource)dataSource).setUrl(), 为啥前面要写成 DataSource dataSource = new MysqlDataSource(); 为什么不直接实例化MysqlDataSource的对象呢??虽然两种写法没啥区别,但实际开发中,可能还是更多的看到前面这种写法。前面这种写法里,得到的数据源是 DataSource 类型,后续写其他代码,方法/类,如果使用到数据源,持有的类型也是 DataSource 类型。
DataSource 是通用的类型,可以指代任何数据库。未来一旦需要更换数据库,代码改动非常小的,只需要将实例化这一小块代码更改即可,其他代码都不需要变。而后面这种写法就需要将所有地方出现的 MysqlDataSource 类型的都更改。所以第一种写法,代码的可维护性,可扩展性就相比于第二种好很多!!
2.dataSource.getConnection() 和 DriverManager.getConnection() 有啥区别??
DriverManager 每次 getConnection() 都会重新和数据库服务器建立连接。
而 DataSource 则可能会复用之前的连接,就不必多次建立连接,毕竟建立连接的过程还挺麻烦,比较低效。(DataSource 内置了数据库连接池)
再演示一个查找操作,插入,删除,修改执行后返回值都是整形,所以代码差别不大,只需要将sql 语句做简单修改即可。
select--查找
public static void main(String[] args) throws SQLException {
DataSource dataSource = new MysqlDataSource();
// 1.使用 DataSource 描述 MySQL 服务器的位置
((MysqlDataSource)dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/xyz?characterEncoding=utf8&useSSL=false");
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("123456");
//2.和数据库服务器建立连接
Connection connection = dataSource.getConnection();
String sql = "select * from student";
PreparedStatement statement = connection.prepareStatement(sql);
//查询操作,返回的是一个结果集,类似于我们的迭代器,resultSet指针最初指向第一行数据的前头,所以需要先调用 next() 往后走!
ResultSet resultSet = statement.executeQuery();
while(resultSet.next()) {
//根据列标签获取当前列的值
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.println(id+"\t"+name);
}
resultSet.close();
statement.close();
connection.close();
}以上操作中重要的知识点还有:1.Statement 对象,2. SQL的两种执行方法。

SQL的两种执行方法:
- executeQuery() 方法执行后返回单个结果集的(类似于迭代器),通常用于select语句。
- executeUpdate()方法返回值是一个整数,指示受影响的行数,通常用于 update、insert、delete 语句。本篇博客就到这里了,谢谢观看!!
边栏推荐
- 北汇信息12岁啦|Happy Birthday
- GOM引擎版本为什么玩家会自动掉线或闪退?
- 射击游戏 第 1-2 课:使用精灵
- Redis distributed lock practice
- 【JZOF】07 重建二叉树
- C language - big end storage and small end storage
- Is it safe to open an account with Guosen Securities software? Will the information be leaked?
- 第七天笔记
- C语言插入排序(直接插入排序)
- What happens when you enter the web address and the web page is displayed
猜你喜欢

倍福PLC和C#通过ADS通信传输Bool数组变量

What is the reason for the failure of video playback and RTMP repeated streaming on easygbs platform?

0722~线程池扩展
![[jzof] 11 minimum number of rotation array](/img/a3/6c3672a2a7b4f436874664034a4964.png)
[jzof] 11 minimum number of rotation array

Cortex-a series processor

【JZOF】08 二叉树的下一个结点

OpenCV图像处理(上)几何变换+形态学操作

机器学习,吴恩达逻辑回归

How does redis implement persistence? Explain in detail the three triggering mechanisms of RDB and their advantages and disadvantages, and take you to quickly master RDB

转行软件测试有学历要求吗?低于大专是真的没出路吗?
随机推荐
C语言插入排序(直接插入排序)
Unity 模型显示到UI前面,后面的UI抖动
Shooting games lesson 1-2: using sprites
射击 第 1-3 课:图像精灵
Space shooting Part 2-3: dealing with the collision between bullets and the enemy
方法区、永久代、元空间的关系
【JZOF】10斐波那契数列
Feynman learning method (redis summary)
Beifu PLC and C transmit string type through ads communication
行业现状令人失望,工作之后我又回到UC伯克利读博了
Li Kou 729. My schedule I
Netease white hat hacker training camp notes (2)
Confused, work without motivation? Career development hopeless? It's enough to read this article
Redis distributed lock practice
吴恩达机器学习系列篇p31~p42
“算力猛兽”浪潮NF5468A5 GPU服务器开放试用免费申请
Jenkins持续集成报错stderr: fatal: unsafe repository (‘/home/water/water‘ is owned by someone else)
[jzof] 09 realize queue with two stacks
[jzof] 11 minimum number of rotation array
Outlook 教程,如何在 Outlook 中切换日历视图、创建会议?